
@ainyc/canonry
v4.117.2
Published
Agent-first open-source AEO operating platform - track how answer engines cite your domain

Readme
Canonry

Agent-first AEO operating platform. Open source. Self-hosted.
- Track citations across Gemini, ChatGPT, Claude, Perplexity, and local LLMs
- Watch AI engines crawl and refer traffic via server-log ingestion — Cloud Run, Vercel, and the WordPress Traffic Logger plugin today
- Diagnose against real traffic with built-in GSC, GA4, and Bing Webmaster
- Track local AEO via Google Business Profile — search-term impressions, performance metrics, and hotel lodging + booking-CTA gaps
- Discover who links to you with Common Crawl backlinks — follows Common Crawl's rolling monthly hyperlink graph, auto-syncing each new window on a schedule, queried locally with DuckDB
- Execute fixes via WordPress, JSON-LD schema, and indexing submissions
- Manage many clients declaratively — config-as-code YAML +
cnry apply - Schedule recurring visibility checks, traffic syncs, and Business Profile syncs, with webhook alerts on regressions
- Generate client-ready HTML reports —
cnry report <project> - Drive from your own agent via the 67-tool MCP adapter or webhooks
- Or use Aero — Canonry's built-in agent that wakes up after every run
Every dashboard view has a matching CLI command and API endpoint. The CLI is the surface; the UI consumes the same API your agent does.
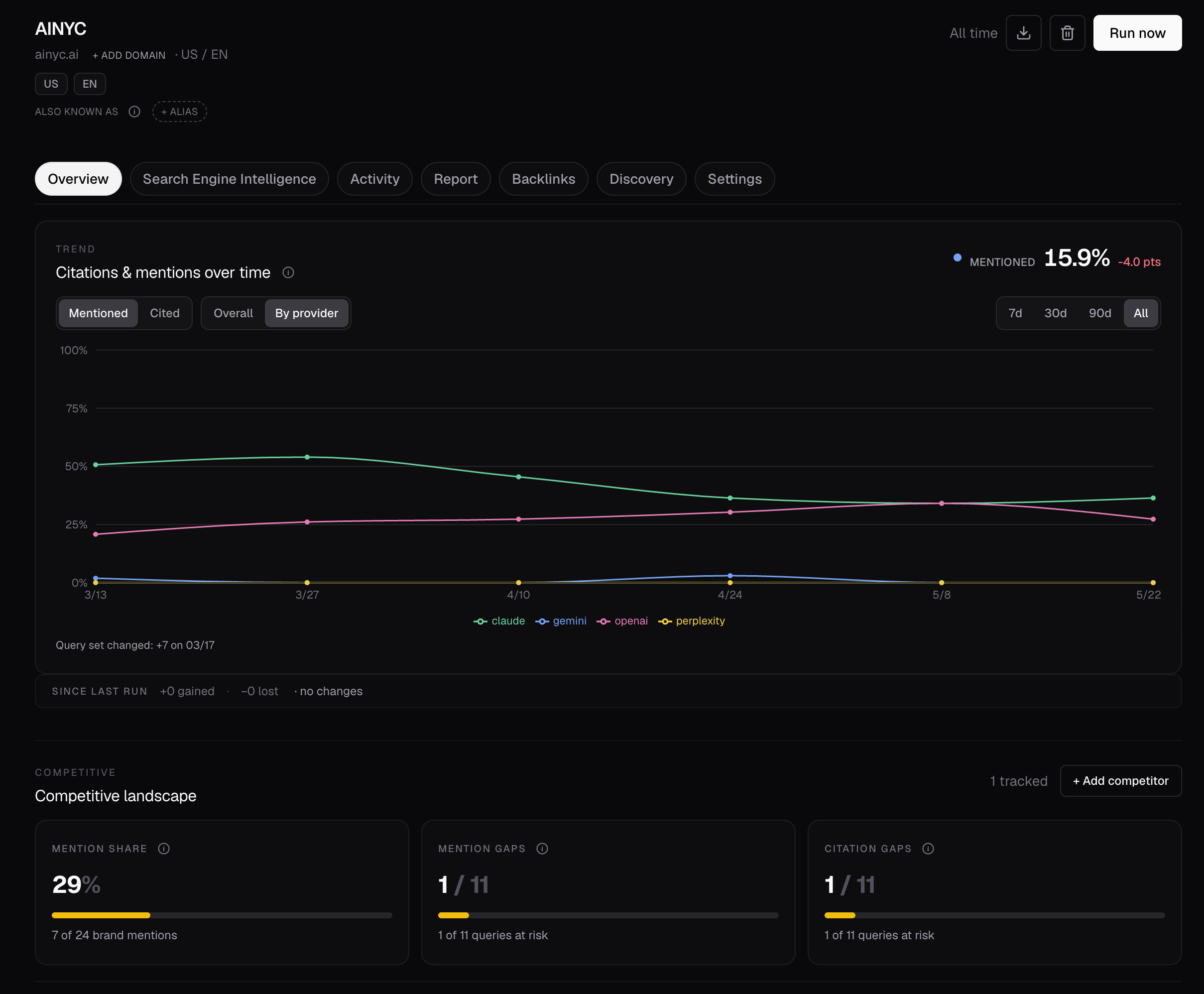
Run your first AI visibility check in 5 minutes
npm install -g @canonry/canonry
cnry init
cnry serveThe CLI installs as cnry (short form) and canonry — the two are interchangeable.
The legacy package name @ainyc/canonry is still published at the same versions for compatibility, but new installs should use @canonry/canonry.
Open http://localhost:4100/setup. A guided wizard walks you through provider keys, project setup, queries, and your first visibility check.
If you serve Canonry on 0.0.0.0 or a LAN address, complete first-run dashboard password setup from loopback first, or authenticate with a cnry_... bearer key. The unauthenticated setup path is loopback-only by design.
Prefer the terminal?
cnry project create my-site --domain example.com
cnry query add my-site "your first query" "second query"
cnry run my-site --wait
cnry evidence my-site
cnry insights my-siteOr set it up with your AI coding agent
Drop this into Claude Code, Codex, or any shell-capable agent. It installs canonry, runs your first sweep, audits your site for AEO readiness, and stops for your sign-off before taking any action on your behalf:
Set up canonry for me. Canonry is an open-source platform that tracks how AI answer engines (Gemini, ChatGPT, Claude, Perplexity) cite my site.
1. Ask me for: my domain, 3–5 queries I want to track, and which provider I want to start with (gemini / openai / claude / perplexity). Wait for my answers before proceeding.
2. Run `npm install -g @canonry/canonry`.
3. Run `cnry init` in this directory. This scaffolds config and installs the canonry skills into `.claude/skills/canonry/`, `.claude/skills/aero/`, `.codex/skills/canonry/`, and `.codex/skills/aero/`. If the skills aren't there afterwards, run `cnry skills install`.
4. Read the operator playbook at `.claude/skills/canonry/SKILL.md` and follow it end-to-end: create the project with my domain and queries, wire up the provider key I chose, and trigger the first sweep.
5. Open my browser to the dashboard so I can see the run results.
6. Switch to the analyst playbook at `.claude/skills/aero/SKILL.md` and run a baseline AEO audit on my behalf. Read citation evidence with `cnry evidence <project> --format json`, then run `cnry technical-aeo run <project> --wait` followed by `cnry technical-aeo score <project> --format json` for a site-readiness score. This crawls every page in my sitemap (not just the homepage), scores the whole site 0–100, and saves the result so it appears in the dashboard and can be re-audited on a schedule.
7. Summarize what you found: my mention and citation rates per provider, the top 3 queries I'm not yet cited on, and the highest-impact site issues from the audit. Ask me for permission before taking any further action, such as drafting content, submitting URLs for indexing, editing files, or anything else that changes my site.One-click copy at canonry.ai.
If you get stuck
| Problem | Fix |
|---------|-----|
| No provider key configured | Open /setup, or grab a free Gemini key, set GEMINI_API_KEY, and restart cnry serve. |
| Why did my first audit fail? | Run cnry doctor, then reopen /setup; it checks provider keys and setup blockers before the first sweep. |
| No results after a run | Visibility checks are async — check the Runs tab or use cnry run <project> --wait. |
| Not sure what queries to test | Setup wizard auto-generates them; expand the basket later with cnry discover run <project> --icp "..." — see the discovery methodology. |
| npm install fails on node-gyp | Install build tools for better-sqlite3 (guide). |
Provider keys
| Provider | Key source | Env var |
|----------|-----------|---------|
| Gemini | aistudio.google.com | GEMINI_API_KEY |
| OpenAI | platform.openai.com | OPENAI_API_KEY |
| Claude | console.anthropic.com | ANTHROPIC_API_KEY |
| Perplexity | perplexity.ai/settings/api | PERPLEXITY_API_KEY |
| Local LLMs | Any OpenAI-compatible endpoint | LOCAL_LLM_URL |
Configure during cnry init, in the dashboard /settings, or as env vars.
Documentation
| | |
|---|---|
| Architecture & data model | docs/architecture.md · docs/data-model.md |
| Aero — built-in agent | skills/aero/SKILL.md |
| MCP — Claude Desktop / Cursor / Codex | docs/mcp.md |
| Integrations | GSC · GA4 · Bing · Google Business Profile · WordPress · Server-side traffic (Cloud Run + Vercel + WordPress logs) |
| Deployment — Docker, Railway, Render, systemd, Tailscale | docs/deployment.md |
| API — 118+ endpoints | GET /api/v1/openapi.json (no auth) |
| Skills bundle for Claude Code / Codex | cnry skills install (details) |
| All docs | docs/README.md |
Requirements
Node.js ≥ 22.14.0. At least one provider API key.
Contributing
git clone https://github.com/Canonry/canonry.git && cd canonry
pnpm install && pnpm run typecheck && pnpm run test && pnpm run lintSee CONTRIBUTING.md.
License
FSL-1.1-ALv2. Free to use, modify, and self-host. Each version converts to Apache 2.0 after two years.