
@betterdb/semantic-cache
v0.11.1
Published
Valkey-native semantic cache for LLM applications with built-in OpenTelemetry and Prometheus instrumentation
Maintainers
 kivanow_betterdb
kivanow_betterdbReadme
@betterdb/semantic-cache


![]()


A standalone, framework-agnostic semantic cache for LLM applications backed by Valkey. Uses Valkey's vector search (valkey-search module) for similarity matching with built-in OpenTelemetry tracing and Prometheus metrics. Full adapter parity with @betterdb/agent-cache.
See it live in BetterDB Monitor
BetterDB Monitor auto-discovers every @betterdb/semantic-cache instance on your Valkey - zero configuration, the library already registers itself - and turns its stats into live dashboards:
- AI Cache & Memory - hit rate, cost saved, evictions, and index size across all your caches and memory stores, with history.
- AI Traces - OpenTelemetry waterfalls for each request, correlated with live Valkey state to explain every cache hit and miss.
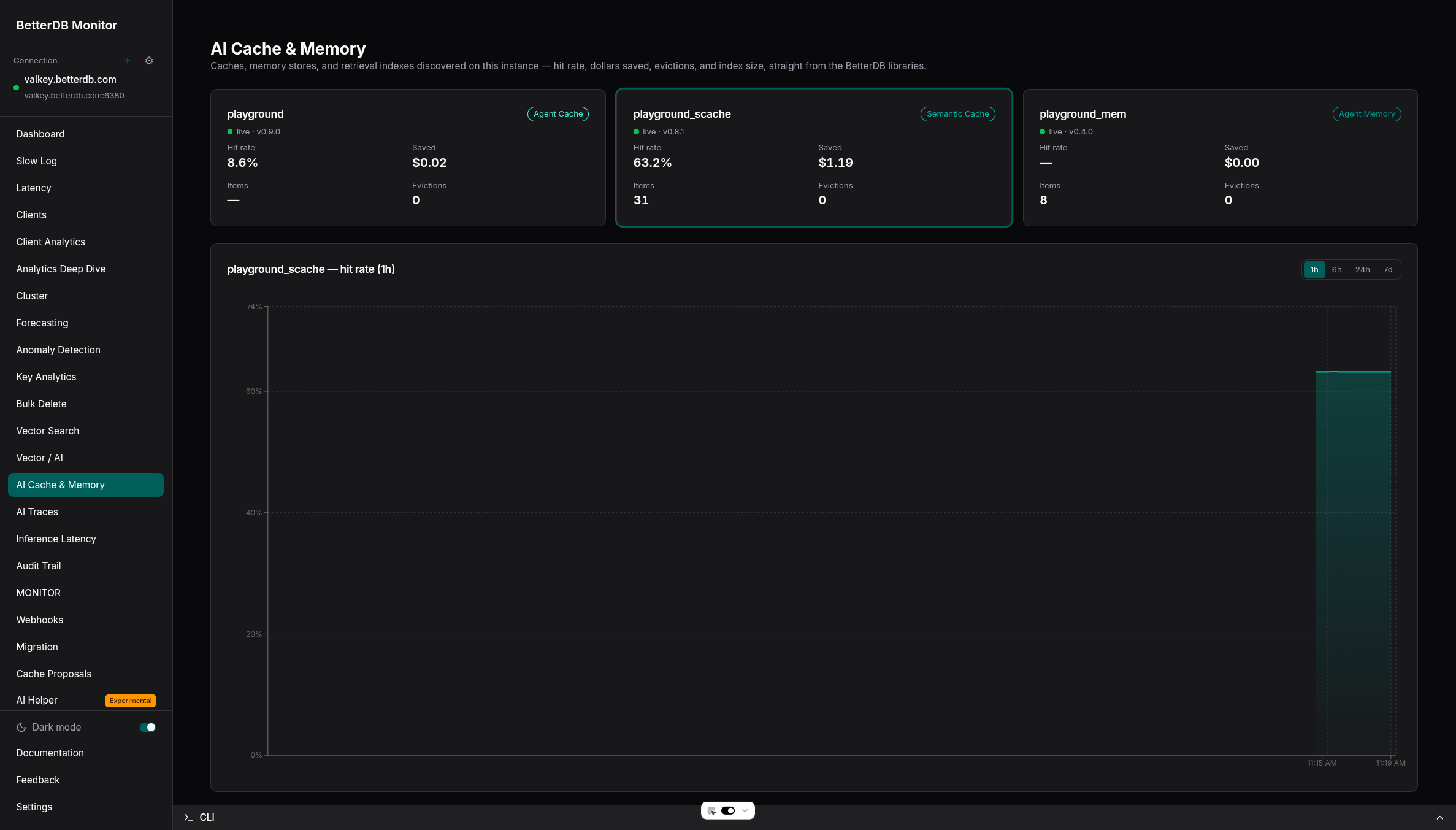
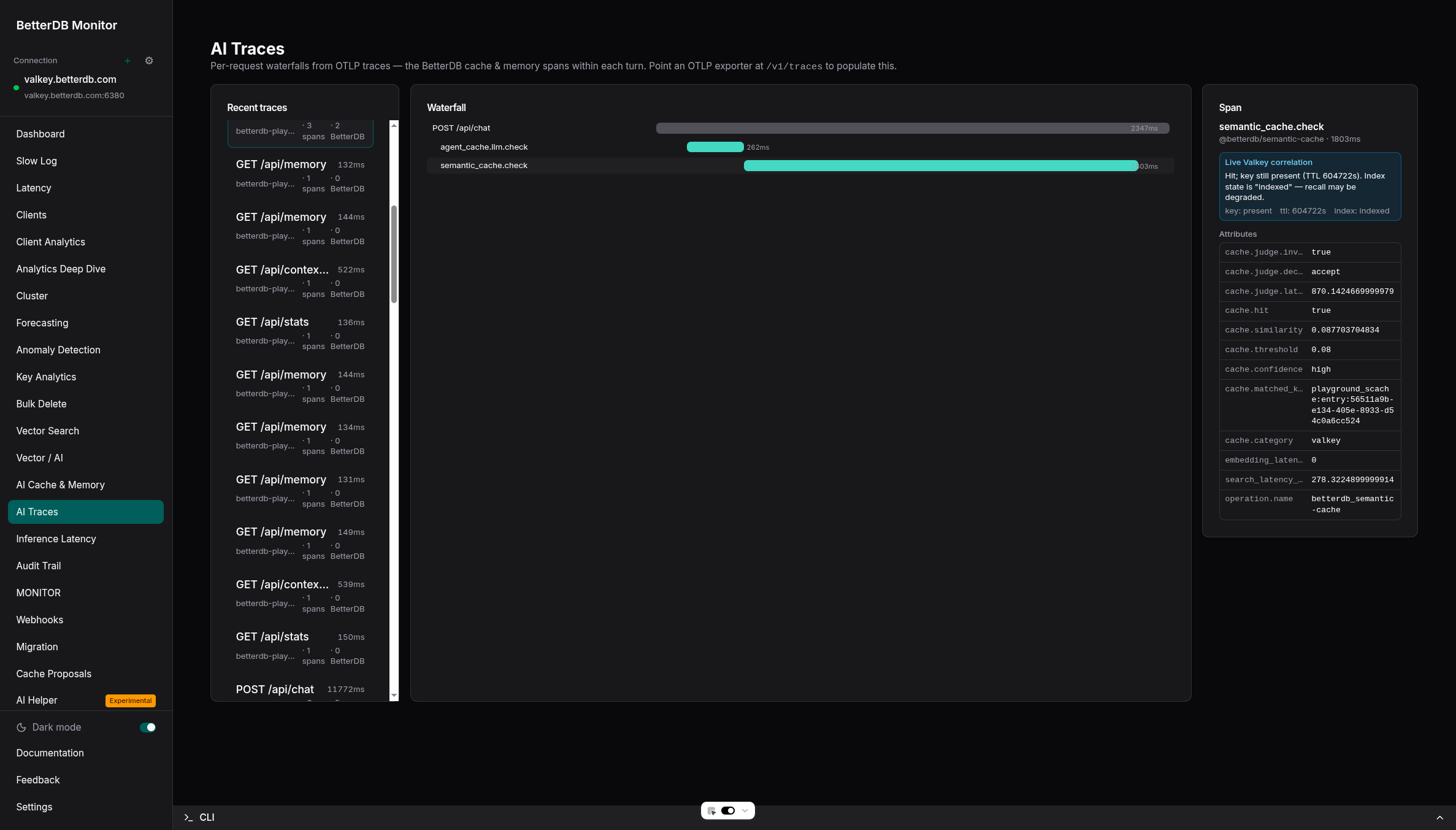
Run it self-hosted (docker run -p 3001:3001 betterdb/monitor), or use BetterDB Cloud - which can also provision a managed, TLS-enabled Valkey instance with the Search module in one click - exactly what this library needs.
Prerequisites
- Valkey 8.0+ with the
valkey-searchmodule loaded - Or Amazon ElastiCache for Valkey (8.0+)
- Or Google Cloud Memorystore for Valkey
- Node.js >= 20.0.0
Installation
npm install @betterdb/semantic-cache iovalkeyiovalkey is a required peer dependency.
Why @betterdb/semantic-cache
The only semantic cache library that is simultaneously Valkey-native (explicit handling of valkey-search API differences), standalone (no coupling to any AI framework), and has built-in OpenTelemetry + Prometheus instrumentation at the cache operation level.
Quick Start
import Valkey from 'iovalkey';
import { SemanticCache } from '@betterdb/semantic-cache';
import { createOpenAIEmbed } from '@betterdb/semantic-cache/embed/openai';
const client = new Valkey({ host: 'localhost', port: 6399 });
const cache = new SemanticCache({
client,
embedFn: createOpenAIEmbed(), // or createVoyageEmbed(), createOllamaEmbed(), etc.
defaultThreshold: 0.15, // loosen slightly to catch paraphrases with high confidence
defaultTtl: 3600,
});
await cache.initialize();
// Store with cost tracking
await cache.store('What is the capital of France?', 'Paris', {
model: 'gpt-4o-mini',
inputTokens: 20,
outputTokens: 5,
});
// Exact match - always high confidence
const exact = await cache.check('What is the capital of France?');
// exact.hit === true
// exact.confidence === 'high'
// exact.similarity === 0.0000
// exact.costSaved === 0.0000085
// Paraphrase - typically 'uncertain' at threshold 0.1, 'high' at threshold 0.15
const paraphrase = await cache.check('What city is the capital of France?');
// paraphrase.hit === true
// paraphrase.confidence === 'high' // at threshold 0.15
// paraphrase.similarity ~= 0.087 // observed with text-embedding-3-small
// paraphrase.costSaved === 0.0000085Threshold and Confidence
This library uses cosine distance (0-2 scale, lower = more similar):
| Distance | Meaning | |----------|---------| | 0.00 | Identical vectors | | 0.05-0.10 | Strong paraphrase | | 0.10-0.20 | Loose paraphrase / related topic | | 1.00 | Orthogonal (unrelated) |
A lookup is a hit when score <= threshold. The default threshold is 0.1.
Confidence levels
| confidence | When | What to do |
|---|---|---|
| high | score <= threshold - uncertaintyBand (e.g. <= 0.05) | Return the cached response directly |
| uncertain | threshold - band < score <= threshold (e.g. 0.05–0.10) | Return the response but consider flagging for review |
| miss | score > threshold | No hit - call the LLM |
With real embeddings (text-embedding-3-small):
- Exact same phrasing:
~0.000- alwayshigh - Close paraphrase ("Which city is the capital of France?"):
~0.08–0.09-uncertainat default0.1threshold,highat0.15 - Loose paraphrase ("France's capital?"):
~0.10–0.15- typicallymissat0.1,uncertainat0.15
Recommended thresholds by use case:
| Use case | Threshold | Notes |
|---|---|---|
| FAQ / exact match only | 0.05 | Very strict, near-zero false positives |
| Standard Q&A | 0.10 | Default - paraphrases land as uncertain |
| Conversational / RAG | 0.15 | Paraphrases hit as high confidence |
| Broad search / recall | 0.20 | High hit rate, review uncertain hits |
LLM-as-judge
When a hit lands in the uncertainty band (threshold - uncertaintyBand < score <= threshold), you can supply a judgeFn to adjudicate automatically instead of handling confidence: 'uncertain' yourself.
const result = await cache.check(userPrompt, {
judge: {
judgeFn: async ({ prompt, response, similarity, threshold, category }) => {
// Return true to accept (confidence → 'high')
// Return false to reject (treated as miss with nearestMiss)
const verdict = await openai.chat.completions.create({
model: 'gpt-5-mini',
messages: [
{ role: 'system', content: 'Reply YES or NO only.' },
{ role: 'user', content: `Does this cached response correctly answer the prompt?\nPrompt: ${prompt}\nResponse: ${response}` },
],
});
return verdict.choices[0].message.content?.startsWith('YES') ?? false;
},
onError: 'accept', // fail-open on judge errors (default)
timeoutMs: 2000, // per-call timeout (default)
},
});When the judge is invoked: only for confidence === 'uncertain' hits. High-confidence hits, misses, and the zero-candidates case bypass the judge entirely.
Accept path: result.hit === true, result.confidence === 'high'.
Reject path: result.hit === false, result.nearestMiss populated with deltaToThreshold <= 0 (use this to distinguish judge rejections from regular misses where deltaToThreshold > 0).
Composing with rerank: when both rerank and judge are set, the judge receives the reranked pick's response and similarity score.
checkBatch() does not support judge. Call check() individually for prompts that need adjudication.
CacheCheckOptions reference
| Option | Type | Default | Description |
|---|---|---|---|
| threshold | number | defaultThreshold | Per-request cosine distance threshold override |
| category | string | — | Category tag for per-category thresholds and metric labels |
| filter | string | — | FT.SEARCH pre-filter expression (trusted input only) |
| k | number | 1 | KNN neighbours to fetch (ignored when rerank is set) |
| staleAfterModelChange | boolean | false | Evict and miss when stored model differs from currentModel |
| currentModel | string | — | Model to compare against stored entries |
| rerank | RerankOptions | — | Rerank hook; see RerankOptions |
| judge | JudgeOptions | — | LLM-as-judge for borderline hits; see JudgeOptions. Not supported by checkBatch(); throws SemanticCacheUsageError |
Configuration Reference
| Option | Type | Default | Description |
|--------|------|---------|-------------|
| name | string | 'betterdb_scache' | Key prefix |
| client | Valkey | - | iovalkey client (required) |
| embedFn | EmbedFn | - | Embedding function (required) |
| defaultThreshold | number | 0.1 | Cosine distance threshold (0-2) |
| defaultTtl | number | undefined | Default TTL in seconds |
| categoryThresholds | Record<string, number> | {} | Per-category threshold overrides |
| uncertaintyBand | number | 0.05 | Width of uncertainty band below threshold |
| costTable | Record<string, ModelCost> | undefined | Per-model pricing overrides |
| useDefaultCostTable | boolean | true | Use bundled LiteLLM price table (1,971 models) |
| normalizer | BinaryNormalizer | defaultNormalizer | Binary content normalizer |
| embeddingCache.enabled | boolean | true | Cache computed embeddings in Valkey |
| embeddingCache.ttl | number | 86400 | Embedding cache TTL (seconds) |
| telemetry.tracerName | string | '@betterdb/semantic-cache' | OTel tracer name |
| telemetry.metricsPrefix | string | 'semantic_cache' | Prometheus prefix |
| telemetry.registry | Registry | default | prom-client Registry |
Cost Tracking
Store token counts at cache-time to get per-hit cost savings:
await cache.store('What is the capital of France?', 'Paris', {
model: 'claude-haiku-4-5', // looked up in bundled LiteLLM price table
inputTokens: 42,
outputTokens: 12,
});
const result = await cache.check('Capital of France?');
console.log(result.costSaved); // e.g. 0.000064 (dollars saved on this hit)
const stats = await cache.stats();
console.log(stats.costSavedMicros); // cumulative microdollars savedCost savings scale with the model. Observed values from live examples:
gpt-4o-mini: ~$0.000006per hit (cheap model, short responses)claude-haiku-4-5: ~$0.000064per hit (~10x more expensive)gpt-4o: ~$0.000100per hit at 20 input / 5 output tokens
Adapters
| Import | Class/Function | Description |
|---|---|---|
| @betterdb/semantic-cache/langchain | BetterDBSemanticCache | LangChain BaseCache |
| @betterdb/semantic-cache/ai | createSemanticCacheMiddleware | Vercel AI SDK middleware |
| @betterdb/semantic-cache/openai | prepareSemanticParams | OpenAI Chat Completions |
| @betterdb/semantic-cache/openai-responses | prepareSemanticParams | OpenAI Responses API |
| @betterdb/semantic-cache/anthropic | prepareSemanticParams | Anthropic Messages API |
| @betterdb/semantic-cache/llamaindex | prepareSemanticParams | LlamaIndex ChatMessage[] |
| @betterdb/semantic-cache/langgraph | BetterDBSemanticStore | LangGraph BaseStore |
Embedding Helpers
| Import | Default model | Dimensions |
|---|---|---|
| @betterdb/semantic-cache/embed/openai | text-embedding-3-small | 1536 |
| @betterdb/semantic-cache/embed/bedrock | amazon.titan-embed-text-v2:0 | 1024 |
| @betterdb/semantic-cache/embed/voyage | voyage-3-lite | 512 |
| @betterdb/semantic-cache/embed/cohere | embed-english-v3.0 | 1024 |
| @betterdb/semantic-cache/embed/ollama | nomic-embed-text | 768 |
Discovery markers
Starting in 0.2.0, initialize() writes a small advisory record to a shared __betterdb:caches hash on the Valkey instance so Monitor (and other tooling) can enumerate caches without configuration. A 60s-TTL heartbeat key is refreshed every 30s; flush() and dispose() remove the heartbeat immediately. No sensitive data is ever written — only cache metadata (type, prefix, version, capabilities, configured thresholds).
Opt out by passing discovery: { enabled: false }. See SemanticCacheOptions.discovery for the full set of knobs.
If your Valkey runs with ACLs, grant the library's user access to the __betterdb:* prefix:
ACL SETUSER <user> +@write +@read ~__betterdb:* ~<your-cache-prefix>:*Discovery writes are best-effort — if the ACL denies them, the cache still functions and the semantic_cache_discovery_write_failed_total counter increments so operators can alert.
cache.dispose()
Graceful shutdown: stops the heartbeat and deletes this instance's heartbeat key so Monitor marks the cache offline immediately. Does not drop the index or delete entries. Call from your SIGTERM handler alongside client.quit().
API
cache.initialize()
Creates or reconnects to the Valkey search index. Must be called before check() or store(). Safe to call multiple times.
cache.check(prompt, options?)
prompt is string | ContentBlock[]. Returns CacheCheckResult:
| Field | Description |
|---|---|
| hit | Whether the nearest neighbour's distance was <= threshold |
| response | Cached response text. Present on hit |
| similarity | Cosine distance (0-2). Present when a candidate was found |
| confidence | 'high' / 'uncertain' / 'miss' |
| costSaved | Dollars saved on this hit. Present when cost was recorded at store time |
| contentBlocks | Structured response blocks. Present when stored via storeMultipart() |
| nearestMiss | On miss with a candidate: { similarity, deltaToThreshold } |
Options: threshold, category, filter, k, staleAfterModelChange, currentModel, rerank
cache.store(prompt, response, options?)
prompt is string | ContentBlock[]. Returns the Valkey key.
Options: ttl, category, model, metadata, inputTokens, outputTokens, temperature, topP, seed
cache.storeMultipart(prompt, blocks, options?)
Stores structured ContentBlock[] as the response. On hit, check() returns contentBlocks.
cache.checkBatch(prompts[], options?)
Pipelined multi-prompt lookups. ~50-70% faster than sequential check() calls. Returns results in input order.
cache.invalidate(filter)
Delete entries matching a valkey-search filter (e.g. '@model:{gpt-4o}').
cache.invalidateByModel(model) / cache.invalidateByCategory(category)
Convenience wrappers around invalidate().
cache.stats()
Returns { hits, misses, total, hitRate, costSavedMicros }.
cache.indexInfo()
Returns { name, numDocs, dimension, indexingState }.
cache.flush()
Drops the index and all entries. Call initialize() again to rebuild. Also stops the discovery heartbeat and deletes its heartbeat key, but preserves the registry entry in __betterdb:caches so Monitor retains history.
cache.shutdown()
Stops the analytics client, cancels the stats snapshot timer, and disposes the discovery heartbeat. Safe to call multiple times.
cache.dispose()
Graceful shutdown of the discovery layer for in-process caches without destroying data. Stops the discovery heartbeat and deletes the heartbeat key; does not touch the index or entries.
cache.thresholdEffectiveness(options?)
Analyzes the rolling similarity score window (last 10,000 entries, up to 7 days) and returns:
{
recommendation: 'tighten_threshold' | 'loosen_threshold' | 'optimal' | 'insufficient_data',
recommendedThreshold?: number, // present when recommendation is tighten/loosen
reasoning: string, // human-readable explanation
hitRate: number,
uncertainHitRate: number, // >20% triggers tighten recommendation
nearMissRate: number, // >30% with avg delta <0.03 triggers loosen
// ...
}cache.thresholdEffectivenessAll(options?)
Returns one result per category seen in the window, plus one aggregate 'all' result.
Observability
Prometheus Metrics
| Metric | Type | Labels | Description |
|--------|------|--------|-------------|
| {prefix}_requests_total | Counter | cache_name, result, category | result: hit, miss, uncertain_hit |
| {prefix}_similarity_score | Histogram | cache_name, category | Cosine distance per lookup |
| {prefix}_operation_duration_seconds | Histogram | cache_name, operation | End-to-end latency |
| {prefix}_embedding_duration_seconds | Histogram | cache_name | Time in embedFn |
| {prefix}_cost_saved_total | Counter | cache_name, category | Dollars saved from hits |
| {prefix}_embedding_cache_total | Counter | cache_name, result | Embedding cache hit/miss |
| {prefix}_stale_model_evictions_total | Counter | cache_name | Evictions from staleAfterModelChange |
OpenTelemetry
Every public method emits an OTel span. Requires an OpenTelemetry SDK in the host application.
Examples
Runnable examples in examples/. All examples connect to localhost:6399 by default (override via VALKEY_HOST / VALKEY_PORT).
| Example | API key needed | What it shows |
|---|---|---|
| basic/ | Voyage AI (or --mock) | Core store/check/invalidate |
| openai/ | OpenAI | Chat Completions + cost tracking |
| openai-responses/ | OpenAI | Responses API adapter |
| anthropic/ | Anthropic + OpenAI | Messages API, high cost savings (~$0.000064/hit) |
| llamaindex/ | OpenAI | ChatMessage[] adapter |
| langchain/ | OpenAI | BetterDBSemanticCache + ChatOpenAI |
| vercel-ai-sdk/ | OpenAI | createSemanticCacheMiddleware |
| langgraph/ | None | BetterDBSemanticStore memory |
| multimodal/ | None | ContentBlock[] with text + image |
| cost-tracking/ | None | Cost savings with mock embedder |
| threshold-tuning/ | None | thresholdEffectiveness() |
| embedding-cache/ | None | Embedding cache on/off comparison |
| batch-check/ | None | checkBatch() vs sequential |
| rerank/ | None | Top-k rerank hook |
Client Lifecycle
SemanticCache does not own the iovalkey client:
const client = new Valkey({ host: 'localhost', port: 6399 });
const cache = new SemanticCache({ client, embedFn });
// ... use cache ...
await client.quit();Known Limitations
Cluster mode
flush() fans out via clusterScan() across all master nodes. FT.SEARCH routes correctly via hash slots. FT.CREATE only creates the index on the receiving node - in a full cluster, create the index on each node separately.
Streaming
store() requires a complete response string. The Vercel AI SDK adapter does not implement wrapStream. Accumulate the full streamed response before calling store().
Schema migration (v0.1 -> v0.2)
v0.2.0 added binary_refs, temperature, top_p, seed fields to the index schema. Existing v0.1.0 indexes operate in text-only mode until flush() + initialize() rebuilds the schema.
License
MIT