
@bun-win32/gpu
v1.2.0
Published
Run HLSL compute and headless rendering on any GPU (NVIDIA/AMD/Intel/WARP) from Bun on Windows — runtime-compiled D3D11 via pure FFI, zero native dependencies.
Maintainers
 obscuritysrl
obscuritysrlReadme
@bun-win32/gpu
Run HLSL compute and headless rendering on any GPU — NVIDIA, AMD, Intel, or Microsoft's WARP software rasterizer — from Bun on Windows. Shaders compile at runtime on Direct3D 11 through pure bun:ffi against DLLs already in C:\Windows\System32. Zero native dependencies. No node-gyp, no prebuilds, no postinstall downloads — a few kilobytes of TypeScript.
import { run } from '@bun-win32/gpu';
const { data } = run(
`RWStructuredBuffer<float> data : register(u0);
[numthreads(64, 1, 1)] void main(uint3 id : SV_DispatchThreadID) { data[id.x] = sqrt(data[id.x]); }`,
{ data: new Float32Array([1, 4, 9, 16, 25, 36, 49, 64]) },
);
console.log([...data]); // [ 1, 2, 3, 4, 5, 6, 7, 8 ]bun add @bun-win32/gpu # or: bun add bun-gpu (unscoped alias, identical surface)That is the entire install story.
Why this exists
GPU compute in JavaScript is a graveyard bracketed by abandonment and bloat (numbers pulled 2026-06-09):
| Package | Weekly downloads | Install | Status |
| --- | --- | --- | --- |
| gpu.js | 15,972 | hard-dep headless-gl → node-gyp ANGLE build fails on modern Node/Windows | dead since Nov 2022 (#807 "Is this project dead?" — unanswered) |
| gl (headless-gl) | 56,431 | prebuild ∥ node-gyp ANGLE source build (VS + Python required) | semi-active; breaks on each VS/Node combo (#325) |
| @tensorflow/tfjs-node | 110,266 | node-pre-gyp binary + source fallback | frozen since 2024-10; broken on Node 24 (#8609) |
| webgpu (Dawn repack) | 42,039 | 24.8 MB tarball / 71 MB unpacked | pre-1.0; N-API crashes under Bun (oven-sh/bun#19336) |
| onnxruntime-node | 2,351,086 | 266 MB unpacked + postinstall CUDA download | active; DML future in doubt (#23783) |
| bun-webgpu | 114,407 | 21.8 MB prebuilt Dawn DLL via optionalDependency | active; portable WGSL, not zero-payload |
| @bun-win32/gpu (alias bun-gpu) | — | kilobytes of TypeScript, zero native code | binds d3d11.dll — an OS-compatibility contract, not a deprecatable vendor add-on |
No N-API ABI surface to break on runtime upgrades, no compiler or Python on the install path, and the engine underneath is not a prototype: a transformer, an MNIST-class trainer, a progressive path tracer, and ~30 more demos run on it in bun-win32.
What you can do
Everything gpu.js did — one-shot kernels, pipeline-mode chaining without readback, multiple outputs per pass, uniforms, 1D/2D/3D dispatch, graphical output, CPU(-class) fallback via WARP — plus what it architecturally never could:
Chained kernels with data retained on the GPU (setPipeline(true), done right):
import { GpuArray, Kernel } from '@bun-win32/gpu';
const array = GpuArray.from(new Float32Array(1_000_000));
const step = new Kernel('RWStructuredBuffer<float> data : register(u0);\n[numthreads(64,1,1)] void main(uint3 id : SV_DispatchThreadID) { data[id.x] = data[id.x] * 0.5 + 1.0; }');
for (let i = 0; i < 100; i += 1) step.dispatch({ data: array }); // 100 dispatches, zero readbacks
const result = await array.readAsync(); // non-blocking — the event loop stays liveReal compute semantics — atomics, groupshared memory, scatter writes, stream compaction, GPU-driven dispatch:
import { gpuHistogram, gpuMatmul, gpuPrefixScan, gpuSort, gpuSum, GpuArray } from '@bun-win32/gpu';
const noise = new Uint32Array(100_000);
for (let index = 0; index < noise.length; index += 1) noise[index] = (Math.random() * 0xffff_ffff) >>> 0;
const sorted = gpuSort(GpuArray.from(noise)); // EXACT vs CPU sort in the selftestImage processing (gpu.js's most popular use case):
import { textureFromPixels, makeTexture, readbackTexture } from '@bun-win32/gpu';
// upload RGBA → Texture2D SRV in, RWTexture2D UAV out → blur/sobel/anything → readbackHeadless rendering with depth, blend, and samplers — to a PNG, no window, works on WARP in CI:
import { captureBackBuffer, decodePNG, encodePNG, makeDepthBuffer } from '@bun-win32/gpu';And the things no JS GPU package offers: an in-process shader toolchain (compile with real FXC diagnostics, disassemble to DXBC assembly, compileCached disk cache), GPU timestamp timers (createGpuTimer), fp64 compute behind a capability probe (deviceFeatures), printf-style kernel debugging (createKernelDebugLog), GPU memory accounting (gpuMemory + leak warnings), adapter census and multi-GPU pinning (listAdapters, createComputeDevice({ adapter })), and the raw COM vtable escape hatch (vcall + every verified slot constant) so any D3D11 call we didn't wrap is one function call away.
Benchmarks
Measured on an NVIDIA GeForce RTX 4090, Windows 11, Bun 1.4.0 — reproduce with bun run example/benchmark.ts (numbers below are one run's table, verbatim):
| Metric | NVIDIA GeForce RTX 4090 (hardware) | Microsoft Basic Render Driver (WARP) | |---|---|---| | kernel compile (cold / warm) | 3.4 ms / 0.8 ms | 0.9 ms / 0.8 ms | | empty dispatch (avg of 1,000) | 2.7 µs | 1.3 µs | | readback 1 MB | 3970 MB/s | 2621 MB/s | | readback 16 MB | 5819 MB/s | 4011 MB/s | | readback 64 MB | 9016 MB/s | 4694 MB/s | | SAXPY 1M elements | 86.53 Gelem/s | 2.01 Gelem/s | | matmul 256×256 | 1841.1 GFLOPS | 20.2 GFLOPS | | gpuSum 1M (cold / warm) | 13.49 ms / 0.08 ms | 12.85 ms / 0.25 ms | | gpuMatmul 256×256 (cold / warm) | 89.52 ms / 0.43 ms (79 GFLOPS warm) | 88.88 ms / 1.55 ms (22 GFLOPS warm) | | gpuHistogram 256 bins (warm) | 83726 Melem/s @ 16M | 1726 Melem/s @ 4M | | gpuSort 1M (warm, incl. readback) | 2.0 ms (CPU sort 51.7 ms) | 55.5 ms (CPU sort 51.9 ms) | | gpuPrefixScan 1M (warm, incl. readback) | 1.0 ms | 5.3 ms |
The matmul row is an inline device-capability kernel; the gpu* rows are the exported std functions (memoized per device — cold pays one FXC compile, warm is pure dispatch). The integration selftest (129 exact-value assertions: buffer round-trips, atomics histograms, groupshared reductions, cbuffer-vs-FXC layout proofs, depth-test proofs, bind-elision proofs, determinism) passes on hardware and WARP: bun run example/gpu.selftest.ts.
Gallery
| | |
| --- | --- |
| 
example/raymarch.ts — soft-shadowed raymarcher, runtime-compiled | 
example/shader-tty.ts — GPU plasma as terminal half-blocks |
| 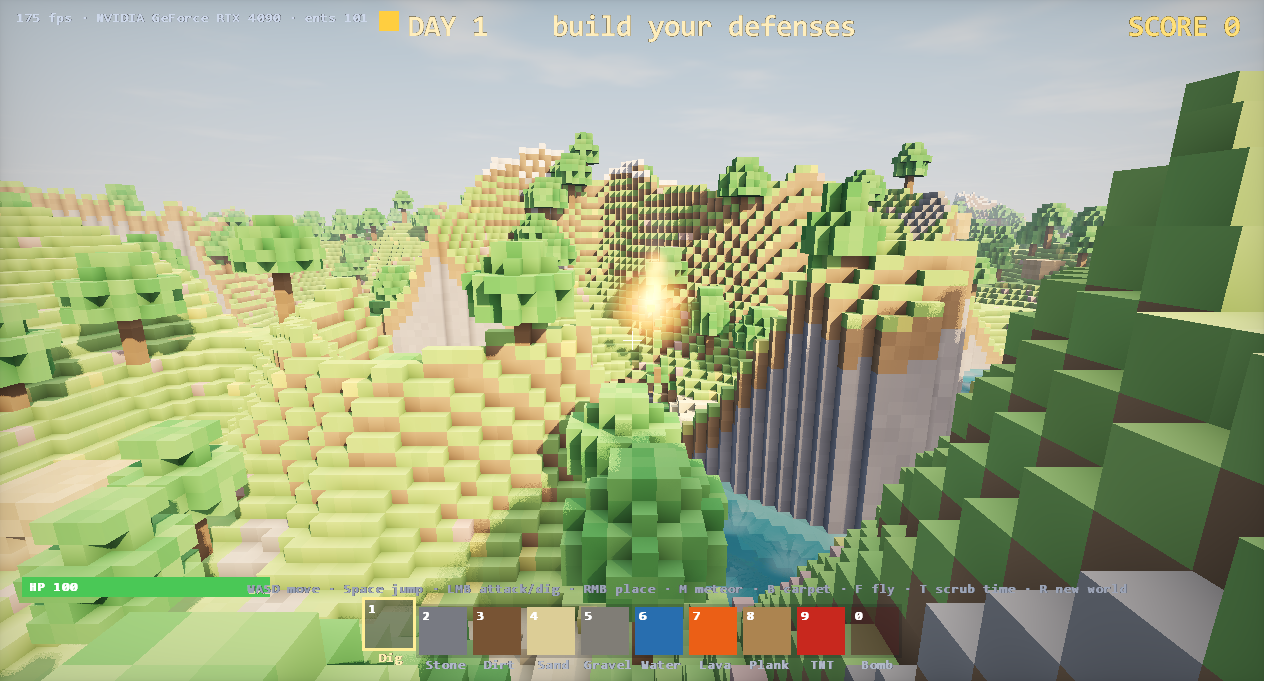 voxelscape — a voxel world on this engine |
voxelscape — a voxel world on this engine | 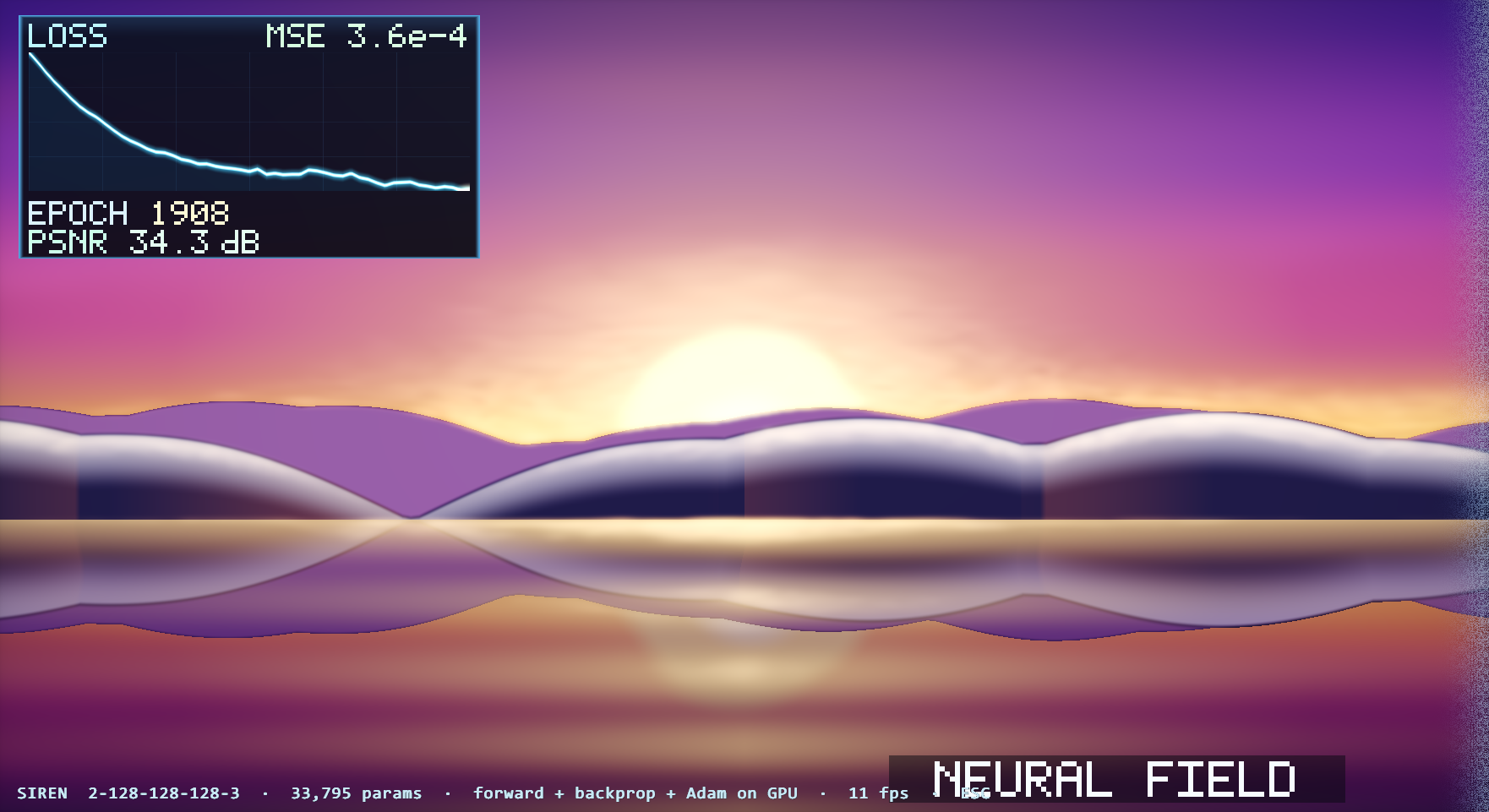 neural-descent — a neural field trained on-GPU |
neural-descent — a neural field trained on-GPU |
A transformer (nano-gpt), a progressive path tracer, a cloth sim, and ~30 more demos run on this engine — they are its regression suite.
Note to AI agents
Read AI.md — it is the complete surface: capability table, full API, copy-paste recipes, and the traps ledger. You should never need to read the source.
Requirements & honest scoping
- Bun ≥ 1.1, Windows 10/11, any GPU or none (WARP always works — including CI). Windows-only and Bun-only, stated plainly: that is the trade-off this package owns.
- You write HLSL (Shader Model 5.0, FXC). bun-gpu is a successor for gpu.js's workloads, not its write-a-JS-function API — a JS→shader transpiler is gpu.js's defining failure mode and a deliberate non-goal (a WGSL/GLSL transpile layer is on the roadmap as a separate concern).
- Not an ONNX/TF model runtime — it is the substrate such runtimes sit on: GPU-resident buffers, sync + async readback, dispose/memory accounting, adapter selection. No op library beyond the std kernels, no autograd.
- Not WebGPU — no WGSL, no portability, no CTS validation layer; HRESULTs and real FXC diagnostics are the deal. On Windows-native depth and install weight, nothing on npm comes close.
- Existing WebGL/three.js code cannot run unported (that is what ANGLE is for); this is for newly written code.
License
MIT