
@codecai/wire-compress
v0.5.0
Published
Pick the right Content-Encoding for streaming responses based on client support and payload size. Measured thresholds, framework-agnostic, zero deps. Companion to the @codecai/* client packages.
Maintainers
 wdunn001
wdunn001Readme
@codecai/wire-compress
Pick the right Content-Encoding for streaming responses based on what the client supports and how big the payload is. Framework-agnostic, zero dependencies, ~5 KB.
Companion to the @codecai/* client packages. Promoted from the bare-named wire-compress package at Codec v0.5 — the library is reusable outside Codec (any streaming HTTP server picking between gzip / brotli / zstd benefits from the measured thresholds), but landing it under @codecai/* makes the relationship explicit and lets it ship on the same npm publish workflow + version cadence.
The conventional advice is "always brotli for HTTP." That's right for static web assets. It's wrong for streaming responses with bursty small frames — SSE, Codec, gRPC-Web text, server-streamed JSON. Brotli's per-block overhead doesn't amortise across 10-25 byte frames, gzip and zstd do.
This library encodes that decision so you don't have to relitigate it per server.
Install
npm install @codecai/wire-compressWorks with any HTTP framework — Express, Fastify, Hono, Node's http, Bun, Deno, Cloudflare Workers. Pure functions, no middleware.
Quick start
Server side — pick what to apply:
import { pick } from '@codecai/wire-compress';
app.get('/stream', (req, res) => {
const dictForThisRequest = lookupZstdDict(req); // see "zstd & dicts" below
const choice = pick({
acceptEncoding: req.headers['accept-encoding'],
estimatedSize: 1024, // tokens or bytes — your call
zstdHasDict: dictForThisRequest !== null,
zstdEnabled: STREAMING_ZSTD_MIDDLEWARE, // operator-set; see below
});
if (choice.encoding !== 'identity') {
res.setHeader('Content-Encoding', choice.encoding);
}
// ... apply the chosen compressor (with dict if zstd) and stream
});Client side — build the request header:
import { buildAcceptEncoding } from '@codecai/wire-compress';
fetch('/stream', {
headers: { 'Accept-Encoding': buildAcceptEncoding() },
// → "gzip;q=1.0, br;q=0.5" (zstd omitted by default)
});
// Opt into zstd only when you've confirmed (a) the server has a dict for
// this tokenizer and (b) the gateway streams (doesn't buffer):
fetch('/stream', {
headers: { 'Accept-Encoding': buildAcceptEncoding({ zstd: true }) },
// → "gzip;q=1.0, br;q=0.5, zstd;q=0.3"
});zstd & pre-trained dictionaries
The picker enforces a hard rule: Content-Encoding: zstd is selected ONLY when both zstdHasDict and zstdEnabled are true. Either gate failing → fall through to gzip.
Why both gates:
- Without a dict, no-dict zstd's wire-byte advantage over gzip is essentially zero on Codec streams (RESULTS.md §1f: gzip and no-dict zstd both reach ~3.4 B/token, within noise) — and on shipped middleware (sglang, vLLM/llama.cpp PR equivs) zstd buffers the whole response, regressing TTFB by 334× at 2K tokens (RESULTS.md §1d). No-dict zstd is the worst of both worlds: same bytes as gzip, much worse TTFB.
- With a dict + streaming middleware, zstd-with-dict beats gzip by 16–38% on bytes (RESULTS.md §1g) at +0.13 ms streaming TTFB. That's the only configuration where zstd is actually preferable to gzip.
So the dict isn't an optimization layered on top of zstd — it's the precondition for zstd being on the menu at all. In practice this means:
- Your server loads its tokenizer map.
- For each request, you check whether the loaded map's
zstd_dictionaries[]field has an entry whoseformatmatches the response'sstream_format. If so, setzstdHasDict: true. - You set
zstdEnabled: trueonce, globally, after confirming your gateway uses streaming-zstd-with-flush (not buffered finalisation). - The picker handles the rest: zstd when both gates pass for this request, gzip otherwise. There is no zstd-no-dict path.
See spec/PROTOCOL.md "Pre-trained ZSTD dictionaries" and dictionaries/README.md in the parent repo for the dict format, training pipeline, and why per-tokenizer dicts are tractable (~10 popular families × 2 wire formats = ~20 dicts of ~16 KB each).
The rule
Defaults are calibrated against measured streaming binary frames (Codec on sglang, see packages/bench/RESULTS.md §1c-1g in the parent repo, or the chart).
| condition | encoding |
|---|---|
| zstdHasDict && zstdEnabled && client accepts zstd | zstd |
| client accepts gzip | gzip |
| client accepts br only | br (fallback) |
| nothing else | identity |
The interactive flag exists for backward compatibility but doesn't change the encoding selected by default — with the new rule it's redundant, because:
- Without a dict, zstd is dropped from candidates (no fallback to no-dict zstd), so interactive mode lands on gzip anyway.
- With a dict + streaming middleware, zstd-with-dict beats gzip even for interactive workloads (+0.13 ms streaming TTFB vs 16–38% byte savings — see
RESULTS.md§1g).
Brotli stays in the picker as a fallback for clients that ship br but not gzip (Safari historical edge cases, some embedded HTTP stacks). On the current sglang server, br's wire reduction is near-zero — it preserves TTFT but barely compresses Codec frames (sometimes expands them: protobuf·br at 2K tokens is 20.2 KB, vs identity 18.9 KB). That's a server-side configuration issue, not a fundamental br limitation. Until upstream fixes its streaming-brotli config, choose gzip when both are available.
What about brotli?
Brotli has wider client coverage than zstd — Safari, iOS, older Firefox all ship br but not zstd. So brotli matters as a fallback, not a primary choice. The picker reflects that:
- If client supports gzip → never use br (gzip wins on this workload at every size we measured).
- If client supports br but not gzip or zstd → use br. It's strictly better than identity.
- If client supports nothing compressible → identity.
This means for the modern web (Chrome 123+ / Firefox 126+) you get zstd, for older browsers and Safari you get gzip, and br only kicks in for genuinely unusual clients that disabled gzip.
What about identity?
Identity loses at every size we measured — even at 16 tokens, compressed Codec is ≥2× smaller than raw. The CPU cost of gzip/zstd on a single CodecFrame is sub-microsecond. So identity is only chosen when the client refuses everything else, or when you explicitly restrict serverSupports.
Chart
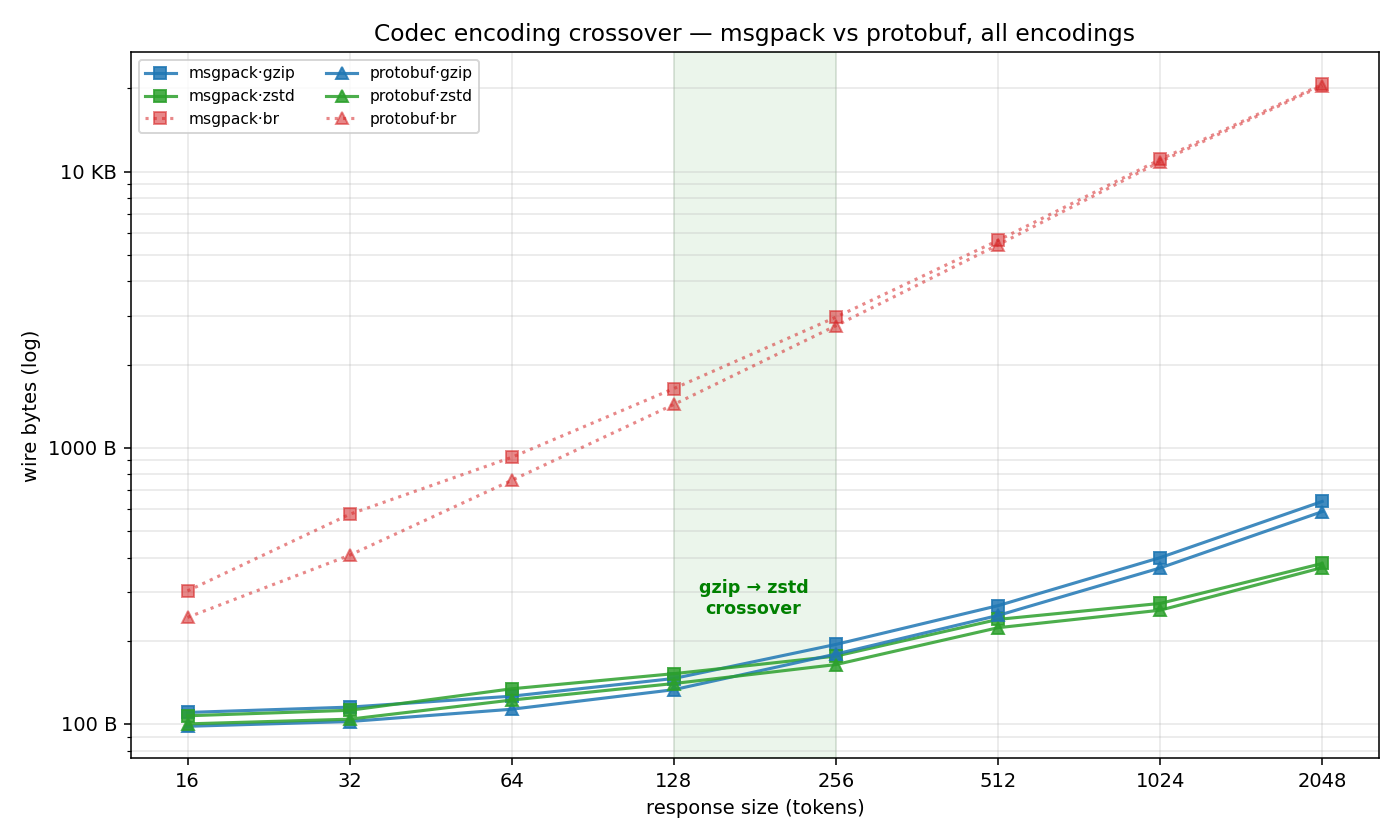
(Source data lives in packages/bench/RESULTS.md §1c. Regenerate with python packages/bench/scripts/plot_crossover.py.)
API
pick(input: PickInput): PickOutput
interface PickInput {
acceptEncoding?: string | null; // raw header value
estimatedSize: number; // tokens or bytes (your unit)
// Required for zstd to be a candidate (default false). Set per request:
// true when the loaded tokenizer map's zstd_dictionaries[] has an entry
// matching this response's stream_format.
zstdHasDict?: boolean;
// Required for zstd to be a candidate (default false). Set globally:
// true when the gateway uses streaming-zstd-with-flush, not buffered
// finalisation (see RESULTS.md §1d).
zstdEnabled?: boolean;
thresholds?: Thresholds; // legacy; rule no longer uses sizes
serverSupports?: Encoding[]; // restrict server-side capabilities
interactive?: boolean; // legacy; no effect under new rule
}
interface PickOutput {
encoding: 'identity' | 'gzip' | 'br' | 'zstd';
reason: string; // human-readable, for logs
}parseAcceptEncoding(header): ClientSupport
RFC 7231 §5.3.4-compliant parser. Sorts entries by q-value descending, drops q=0 entries, respects identity;q=0 to disable identity, returns unspecified=true when the header is absent.
buildAcceptEncoding(opts?): string
Builds the recommended Accept-Encoding header for clients to send. Default order reflects the measured preference: zstd;q=1.0, gzip;q=0.9, br;q=0.5. Pass { zstd: false } etc. to omit individual encodings.
describeRule(t?): string
Pretty-print the threshold rule for log lines or --help output.
DEFAULT_THRESHOLDS
const DEFAULT_THRESHOLDS = {
gzipPreferredUpTo: 128, // size <= this → gzip
zstdPreferredFrom: 256, // size >= this → zstd
brotliFallbackOnly: true, // br only when nothing better is available
identityFallbackOnly: true,
};Why a separate package?
This logic is genuinely useful outside Codec. Anywhere you have:
- Streaming responses (SSE, gRPC-Web text, event streams)
- Many small frames rather than one big blob
- Mixed clients (modern browsers, mobile webviews, CLI tools, IoT)
…the right encoding depends on size and client support, and the standard "always-brotli" advice is wrong. Drop this in instead of writing your own switch statement.
The thresholds were measured for streaming token frames specifically. They generalise to other small-frame streaming workloads (chat APIs, log streams, telemetry) but you may want to recalibrate for your data — pass a custom thresholds argument to pick().
License
MIT.