
@ekaone/llm-gate
v0.1.0
Published
Lightweight LLM budget & token guard. Prevents Denial of Wallet attacks with a circuit-breaker state machine.
Downloads
29
Maintainers
 ekaone
ekaoneReadme
@ekaone/llm-gate
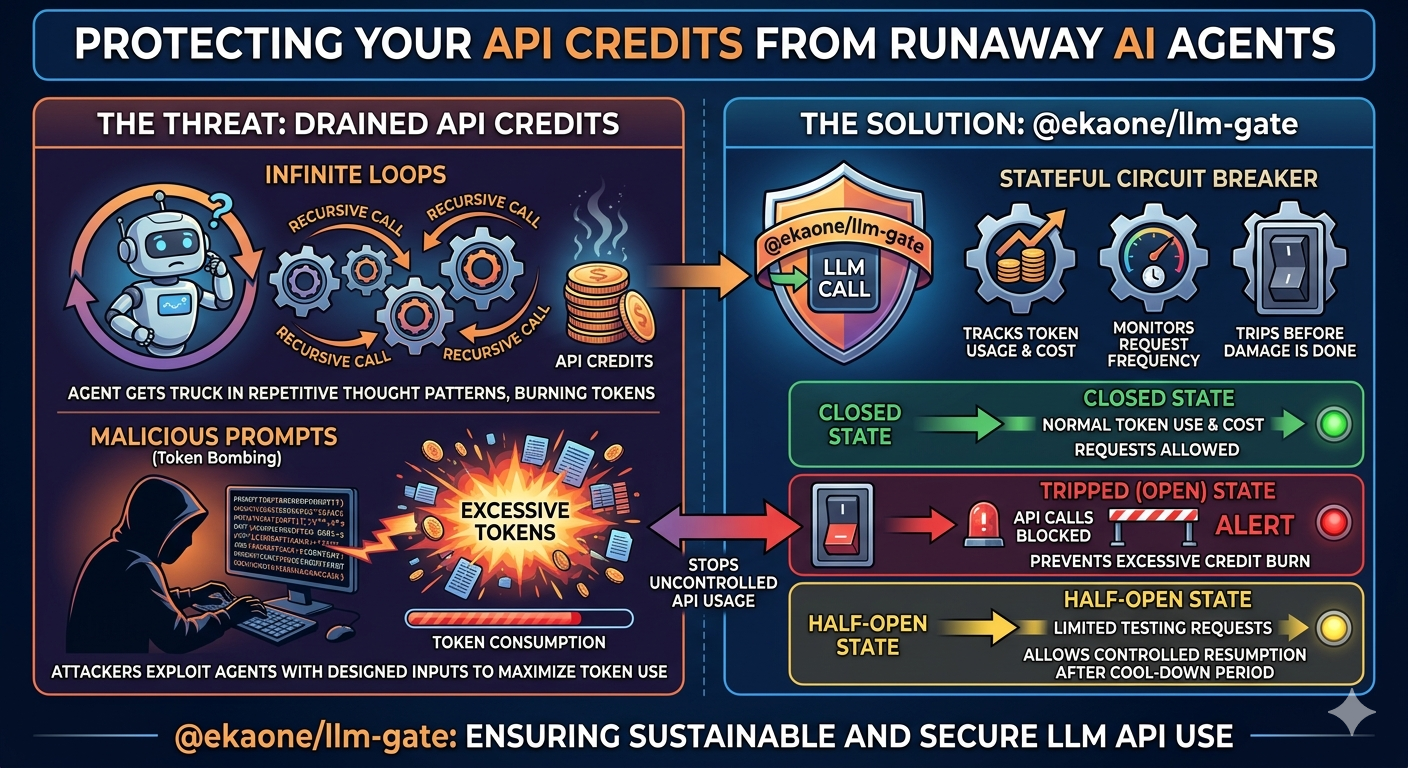
Lightweight LLM budget & token guard. Prevents Denial of Wallet attacks with a zero-dependency circuit-breaker state machine.
Why
AI agents can silently burn through your API credits if they enter infinite loops or receive malicious prompts designed to trigger excessive token consumption. @ekaone/llm-gate wraps every LLM call with a stateful circuit breaker that tracks token usage, cost, and request frequency — then trips before the damage is done.
OPEN ──(80% threshold)──► THROTTLED ──(100% limit)──► TRIPPED
▲ │
└──────────────────(windowMs elapsed)───────────────────┘Install
npm install @ekaone/llm-gatepnpm install @ekaone/llm-gateyarn install @ekaone/llm-gateQuick Start
import { createGate } from "@ekaone/llm-gate"
const gate = createGate({
maxTokens: 50_000, // trip at 50k tokens per window
maxBudget: 0.10, // trip at $0.10 USD per window
maxRequests: 100, // trip at 100 requests per window
windowMs: 60_000, // 1 minute sliding window
onThrottled: (status) => console.warn("⚠️ Approaching limit", status.tokens),
onTripped: (status) => console.error("🚫 Gate tripped!", status.reason),
onReset: (status) => console.log("✅ Gate reset, window fresh"),
})
// After every LLM response — feed usage back into the gate
gate.record({
model: "claude-sonnet-4-20250514",
inputTokens: 312,
outputTokens: 89,
})
// Before the next LLM call — check the gate
const status = gate.check()
if (!status.allowed) {
console.log(`Blocked. Resets at ${status.resets.toLocaleTimeString()}`)
}
// Or throw-style for agent pipelines
gate.guard() // throws BudgetExceededError if TRIPPEDAPI
createGate(options)
Creates a new gate instance. At least one of maxTokens, maxBudget, or maxRequests is required.
const gate = createGate(options: GateOptions): GateInstanceGateOptions
| Option | Type | Default | Description |
|---|---|---|---|
| maxTokens | number | — | Max total tokens (input + output) per window |
| maxBudget | number | — | Max cost in USD per window |
| maxRequests | number | — | Max LLM calls per window |
| windowMs | number | 60_000 | Window duration in milliseconds |
| throttleAt | number | 0.8 | Fraction of limit that triggers THROTTLED (0.0–1.0) |
| pricing | PricingTable | built-in | Custom model pricing — merged over defaults |
| onThrottled | (status) => void | — | Fires once on entry to THROTTLED state |
| onTripped | (status) => void | — | Fires once on entry to TRIPPED state |
| onReset | (status) => void | — | Fires when window resets or reset() is called |
gate.record(usage)
Feed token usage from an LLM response back into the gate. Call this after every successful LLM response.
gate.record({
model: "claude-sonnet-4-20250514",
inputTokens: 312,
outputTokens: 89,
})For convenience, use the built-in adapters to map provider responses directly:
import { fromAnthropic, fromOpenAI, fromResponse } from "@ekaone/llm-gate"
// Anthropic
gate.record(fromAnthropic(anthropicResponse))
// OpenAI
gate.record(fromOpenAI(openaiResponse))
// Auto-detect provider from response shape
gate.record(fromResponse(anyResponse))gate.check()
Returns the current GateStatus — never throws.
const status = gate.check()
// status.state → "OPEN" | "THROTTLED" | "TRIPPED"
// status.allowed → boolean
// status.reason → string | null
// status.tokens → { used, remaining, limit }
// status.budget → { used, remaining, limit }
// status.requests → { used, remaining, limit }
// status.resets → DateExample status when TRIPPED
{
state: "TRIPPED",
allowed: false,
reason: "token_limit_exceeded",
tokens: { used: 51_200, remaining: 0, limit: 50_000 },
budget: { used: 0.094, remaining: 0.006, limit: 0.10 },
requests: { used: 87, remaining: 13, limit: 100 },
resets: Date <2026-03-20T09:01:00Z>
}gate.guard()
Check and throw BudgetExceededError if the gate is TRIPPED. Ideal for agent pipelines where you want to bail early.
try {
gate.guard()
const response = await llm.call(prompt)
gate.record(fromAnthropic(response))
} catch (err) {
if (err instanceof BudgetExceededError) {
console.log(err.reason) // "token_limit_exceeded"
console.log(err.resets) // Date
console.log(err.snapshot) // full GateStatus at time of trip
}
}gate.snapshot()
Read-only view of current state. Identical to check() but semantically signals "I'm just observing."
const snap = gate.snapshot()gate.reset()
Manually reset the gate to OPEN and clear all counters. Useful for new user sessions or test teardown.
gate.reset()Built-in Adapters
Tree-shakeable — only bundled if imported.
import { fromAnthropic } from "@ekaone/llm-gate" // Anthropic only
import { fromOpenAI } from "@ekaone/llm-gate" // OpenAI only
import { fromResponse } from "@ekaone/llm-gate" // auto-detectCustom Pricing
The built-in pricing table covers common Anthropic and OpenAI models. Override or extend it via the pricing option:
const gate = createGate({
maxBudget: 1.00,
pricing: {
"my-fine-tuned-model": {
inputPerToken: 0.000005,
outputPerToken: 0.000015,
},
},
})Custom entries are merged over the defaults — you only need to specify models you want to override.
Real Use Cases
1. Autonomous agent loop guard
const gate = createGate({
maxTokens: 200_000,
maxBudget: 0.50,
onTripped: (s) => alertOps("Agent loop detected", s),
})
while (agentHasWork()) {
gate.guard() // bail if budget blown
const res = await agent.step()
gate.record(fromAnthropic(res))
}2. Per-user session budget
const sessions = new Map<string, ReturnType<typeof createGate>>()
function getGate(userId: string) {
if (!sessions.has(userId)) {
sessions.set(userId, createGate({
maxTokens: 20_000,
windowMs: 24 * 60 * 60 * 1000, // 24h
}))
}
return sessions.get(userId)!
}
// In your chat handler
const gate = getGate(req.userId)
const status = gate.check()
if (!status.allowed) {
return res.status(429).json({
error: "Daily limit reached",
resets: status.resets,
})
}3. Multi-step RAG pipeline
const gate = createGate({ maxTokens: 10_000, maxRequests: 5 })
const retrieved = await retrieve(query); gate.record(fromAnthropic(retrieved))
const reranked = await rerank(retrieved); gate.record(fromAnthropic(reranked))
const summarized = await summarize(reranked); gate.record(fromAnthropic(summarized))
gate.guard() // only answer if still within budget
const answer = await answer(summarized, query); gate.record(fromAnthropic(answer))4. Dev/test budget cap
// vitest setup
import { createGate } from "@ekaone/llm-gate"
export const testGate = createGate({
maxBudget: 0.05, // $0.05 max spend per test run
onTripped: () => { throw new Error("Test suite exceeded LLM budget!") }
})How Token Counting Works
@ekaone/llm-gate does not tokenize text. It reads the usage field that every LLM provider returns in the response — this is the authoritative count from the model itself.
You set maxTokens: 50_000
↓
LLM call happens (gate doesn't intercept this)
↓
API returns usage → { input_tokens: 312, output_tokens: 89 }
↓
gate.record(...) → tokensUsed += 312 + 89 = 401
↓
gate.check() → 401 < 50_000 → OPEN ✅This means the gate cannot prevent a single oversized request — it stops the next call after the limit is hit. This is a deliberate tradeoff: no tokenizer dependency, works across all providers, zero overhead.
TypeScript
Fully typed. All types are exported:
import type {
GateOptions,
GateInstance,
GateStatus,
GateMetric,
CircuitState,
TripReason,
ThrottleReason,
UsageRecord,
ModelPricing,
PricingTable,
} from "@ekaone/llm-gate"License
MIT © Eka Prasetia
Links
⭐ If this library helps you, please consider giving it a star on GitHub!