
@everworker/oneringai
v0.10.0
Published
Unified AI agent library with multi-vendor support for text generation, image generation, and agentic workflows
Downloads
651
Maintainers
 aantich
aantichReadme
@everworker/oneringai
A unified AI agent library with multi-provider support for text generation, image/video generation, audio (TTS/STT), and agentic workflows.
![]()
![]()
![]()
Table of Contents
- Features
- Quick Start — Installation, basic usage, tools, vision, audio, images, video, search, scraping
- Supported Providers
- Key Features
- 1. Agent with Plugins
- 2. Dynamic Tool Management
- 3. Tool Execution Plugins
- 4. Session Persistence
- Storage Registry
- 5. Working Memory
- 6. Research with Search Tools
- 7. Context Management
- 8. InContextMemory
- 9. Persistent Instructions
- 10. User Info
- 10b. Self-Learning Memory — plugin + tools —
MemoryPluginNextGen+MemoryWritePluginNextGenwith 12memory_*LLM tools (6 read incl.memory_search_documents+ 6 write incl.memory_set_agent_rule); supersedes 9 & 10 - 11. Direct LLM Access
- 12. Audio Capabilities
- Embeddings — Multi-vendor text embeddings with MRL dimension control
- 13. Model Registry
- 14. Streaming
- 15. OAuth for External APIs
- 16. Developer Tools
- 17. Custom Tool Generation — Agents create, test, and persist their own tools
- 18. Document Reader — PDF, DOCX, XLSX, PPTX, CSV, HTML, images
- 19. Desktop Automation Tools — Screenshot, mouse, keyboard, window control for computer use agents
- 20. Routine Execution — Multi-step workflows with task dependencies, validation, and memory bridging
- 21. External API Integration — Scoped Registry, Vendor Templates, Tool Discovery
- 22. Microsoft Graph Connector Tools — Email, calendar, meetings, and Teams transcripts
- 23. Tool Catalog — Dynamic tool loading/unloading for agents with 100+ tools
- 24. Async (Non-Blocking) Tools — Background tool execution with auto-continuation
- 25. Long-Running Sessions (Suspend/Resume) — Suspend agent loops waiting for external input, resume days later
- 26. Agent Registry — Global tracking, deep inspection, parent/child hierarchy, event fan-in, external control
- 27. Agent Orchestrator — Multi-agent teams with shared workspace, delegation, and async execution
- 28. Telegram Connector Tools — Bot API tools for messaging, updates, and webhooks
- 29. Twilio Connector Tools — SMS and WhatsApp messaging tools
- 30. Google Workspace Connector Tools — Gmail, Calendar, Meet, and Drive tools
- 31. Zoom Connector Tools — Meeting management and transcripts
- 32. Unified Calendar — Cross-provider meeting slot finder (Google + Microsoft)
- 33. Multi-Account Connectors — Multiple accounts per vendor with automatic routing
- 34. Integration Testing — Reusable test suites for connector tools
- 36. Instruction Templates —
{{DATE}},{{AGENT_ID}}, custom{{COMMAND:arg}}with extensible registry
- MCP Integration
- Documentation
- Examples
- Development
- Architecture
- Troubleshooting
- Contributing
- License
Documentation
Start here if you're looking for detailed docs or the full API reference.
| Document | Description | |----------|-------------| | User Guide | Comprehensive guide covering every feature with examples — connectors, agents, context, plugins, audio, video, search, MCP, OAuth, and more | | API Reference | Auto-generated reference for all public exports — classes, interfaces, types, and functions with signatures | | CHANGELOG | Version history and migration notes |
Tutorial / Architecture Series
Part 0. One Lib to Rule Them All: Why We Built OneRingAI: introduction and architecture overview
Part 1. Your AI Agent Forgets Everything. Here’s How We Fixed It.: context management plugins
EVERWORKER DESKTOP APP
We realize that library alone in these times is not enough to get you excited, so we built a FREE FOREVER desktop app on top of this library to showcase its power! Check the Everworker Desktop repository for installation instructions. Or watch the video first:
Better to see once and then dig in the code! :)
YOUetal
Showcasing another amazing "built with oneringai": "no saas" agentic business team
Features
- ✨ Unified API - One interface for 12 AI providers (OpenAI, Anthropic, Google, Vertex, Groq, Together, Perplexity, Grok, DeepSeek, Mistral, Ollama, Custom)
- 🔑 Connector-First Architecture - Single auth system with support for multiple keys per vendor
- 📊 Model Registry - Complete metadata for 60+ latest (2026) models with pricing and features
- 🎤 Audio Capabilities - Text-to-Speech (TTS) and Speech-to-Text (STT) with OpenAI and Groq
- 🖼️ Image Generation - DALL-E 3, gpt-image-1, Google Imagen 4 with editing and variations
- 🎬 Video Generation - NEW: OpenAI Sora 2 and Google Veo 3 for AI video creation
- 🔢 Embeddings - NEW: Multi-vendor embedding generation with MRL dimension control (OpenAI, Google, Ollama, Mistral)
- 🔍 Web Search - Connector-based search with Serper, Brave, Tavily, and RapidAPI providers
- 🔌 NextGen Context - Clean, plugin-based context management with
AgentContextNextGen - 🎛️ Dynamic Tool Management - Enable/disable tools at runtime, namespaces, priority-based selection
- 🔌 Tool Execution Plugins - NEW: Pluggable pipeline for logging, analytics, UI updates, custom behavior
- 💾 Session Persistence - Save and resume conversations with full state restoration
- ⏸️ Long-Running Sessions - NEW: Suspend agent loops via
SuspendSignal, resume hours/days later withAgent.hydrate() - 👤 Multi-User Support - Set
userIdonce, flows automatically to all tool executions and session metadata - 🔒 Auth Identities - Restrict agents to specific connectors (and accounts), composable with access policies
- 🤖 Universal Agent - ⚠️ Deprecated - Use
Agentwith plugins instead - 🤖 Task Agents - ⚠️ Deprecated - Use
AgentwithWorkingMemoryPluginNextGen - 🔬 Research Agent - ⚠️ Deprecated - Use
Agentwith search tools - 🎯 Context Management - Algorithmic compaction with tool-result-to-memory offloading
- 📌 InContextMemory - Live key-value storage directly in LLM context with optional UI display (
showInUI) - 📝 Persistent Instructions - ⚠️ Deprecated in favour of
MemoryPluginNextGen(self-learning memory). Still works unchanged. - 👤 User Info Plugin - ⚠️ Deprecated in favour of
MemoryPluginNextGen. Still works unchanged. - 🧠 Self-Learning Memory - NEW:
MemoryPluginNextGen+MemoryWritePluginNextGen+ 11memory_*tools — brain-like entity/fact store with three-principal permissions, semantic search, graph queries, LLM-synthesised profiles that evolve from observations, user-driven behavior rules, optional background ingestion viaSessionIngestorPluginNextGen - 🛠️ Agentic Workflows - Built-in tool calling and multi-turn conversations
- 🔧 Developer Tools - NEW: Filesystem and shell tools for coding assistants (read, write, edit, grep, glob, bash)
- 🧰 Custom Tool Generation - NEW: Let agents create, test, and persist their own reusable tools at runtime — complete meta-tool system with VM sandbox
- 🖥️ Desktop Automation - NEW: OS-level computer use — screenshot, mouse, keyboard, and window control for vision-driven agent loops
- 📄 Document Reader - NEW: Universal file-to-text converter — PDF, DOCX, XLSX, PPTX, CSV, HTML, images auto-converted to markdown
- 🔌 MCP Integration - NEW: Model Context Protocol client for seamless tool discovery from local and remote servers
- 👁️ Vision Support - Analyze images with AI across all providers
- 📋 Clipboard Integration - Paste screenshots directly (like Claude Code!)
- 🔐 Scoped Connector Registry - NEW: Pluggable access control for multi-tenant connector isolation
- 💾 StorageRegistry - Centralized storage configuration — swap all backends (sessions, media, custom tools, etc.) with one
configure()call - 🔐 OAuth 2.0 - Full OAuth support for external APIs with encrypted token storage
- 📦 Vendor Templates - NEW: Pre-configured auth templates for 43+ services (GitHub, Slack, Stripe, etc.)
- 📧 Microsoft Graph Tools - NEW: Email, calendar, meetings, and Teams transcripts via Microsoft Graph API
- 🔁 Routine Execution - NEW: Multi-step workflows with task dependencies, LLM validation, retry logic, and memory bridging between tasks
- 📊 Execution Recording - NEW: Persist full routine execution history with
createExecutionRecorder()— replaces manual hook wiring - ⏰ Scheduling & Triggers - NEW:
SimpleSchedulerfor interval/one-time schedules,EventEmitterTriggerfor webhook/queue-driven execution - 📦 Tool Catalog - NEW: Dynamic tool loading/unloading — agents discover and load only the categories they need at runtime
- Async Tools - NEW: Non-blocking tool execution — long-running tools run in background while the agent continues reasoning, with auto-continuation when results arrive
- 📡 Agent Registry - NEW: Global tracking of all active agents — deep inspection, parent/child hierarchy, event fan-in, external control
- 📱 Telegram Tools - NEW: 6 Telegram Bot API tools — send messages/photos, get updates, webhooks, chat info
- 📞 Twilio Tools - NEW: 4 Twilio tools — SMS, WhatsApp messaging, message listing and details
- 📧 Google Workspace Tools - NEW: 11 tools for Gmail, Calendar, Meet transcripts, and Drive (read, search, list files)
- 🎥 Zoom Tools - NEW: 3 Zoom tools — create/update meetings, get cloud recording transcripts
- 📅 Unified Calendar - NEW: Cross-provider meeting slot finder aggregating Google + Microsoft calendars
- 👥 Multi-Account Connectors - NEW: Multiple accounts per vendor (e.g., work + personal) with automatic routing
- 🧪 Integration Testing - NEW: Reusable test suite framework for connector tools with 10 built-in suites
- 📝 Instruction Templates - NEW:
{{DATE}},{{AGENT_ID}},{{RANDOM:1:10}}and custom{{COMMAND:arg}}in agent instructions — extensible registry with async support - 🔄 Streaming - Real-time responses with event streams
- 📝 TypeScript - Full type safety and IntelliSense support
v0.2.0 — Multi-User Support: Set
userIdonce on an agent and it automatically flows to all tool executions, OAuth token retrieval, session metadata, and connector scoping. Combine withidentitiesand access policies for complete multi-tenant isolation. See Multi-User Support and Auth Identities in the User Guide.
Quick Start
Installation
npm install @everworker/oneringaiBasic Usage
import { Connector, Agent, Vendor } from '@everworker/oneringai';
// 1. Create a connector (authentication)
Connector.create({
name: 'openai',
vendor: Vendor.OpenAI,
auth: { type: 'api_key', apiKey: process.env.OPENAI_API_KEY! },
});
// 2. Create an agent
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
});
// 3. Run
const response = await agent.run('What is the capital of France?');
console.log(response.output_text);
// Output: "The capital of France is Paris."With Tools
import { ToolFunction } from '@everworker/oneringai';
const weatherTool: ToolFunction = {
definition: {
type: 'function',
function: {
name: 'get_weather',
description: 'Get current weather',
parameters: {
type: 'object',
properties: {
location: { type: 'string' },
},
required: ['location'],
},
},
},
execute: async (args) => {
return { temp: 72, location: args.location };
},
};
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [weatherTool],
});
await agent.run('What is the weather in Paris?');Vision
import { createMessageWithImages } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4o',
});
const response = await agent.run(
createMessageWithImages('What is in this image?', ['./photo.jpg'])
);Audio (NEW)
import { TextToSpeech, SpeechToText } from '@everworker/oneringai';
// Text-to-Speech — built-in voice
const tts = TextToSpeech.create({
connector: 'openai',
model: 'tts-1-hd',
voice: 'nova', // alloy | ash | ballad | coral | echo | fable | onyx | nova | sage | shimmer | verse | marin | cedar
});
await tts.toFile('Hello, world!', './output.mp3');
// Text-to-Speech — custom voice (OpenAI). Pass the `voice_…` id you got
// when registering the voice in the OpenAI dashboard; the SDK call is
// handled automatically.
const customTts = TextToSpeech.create({
connector: 'openai',
model: 'gpt-4o-mini-tts',
voice: 'voice_1234abcd',
});
await customTts.toFile('Spoken in your bespoke voice.', './brand.mp3');
// Speech-to-Text
const stt = SpeechToText.create({
connector: 'openai',
model: 'whisper-1',
});
const result = await stt.transcribeFile('./audio.mp3');
console.log(result.text);Image Generation (NEW)
import { ImageGeneration } from '@everworker/oneringai';
// OpenAI DALL-E
const imageGen = ImageGeneration.create({ connector: 'openai' });
const result = await imageGen.generate({
prompt: 'A futuristic city at sunset',
model: 'dall-e-3',
size: '1024x1024',
quality: 'hd',
});
// Save to file
const buffer = Buffer.from(result.data[0].b64_json!, 'base64');
await fs.writeFile('./output.png', buffer);
// Google Imagen
const googleGen = ImageGeneration.create({ connector: 'google' });
const googleResult = await googleGen.generate({
prompt: 'A colorful butterfly in a garden',
model: 'imagen-4.0-generate-001',
});Video Generation (NEW)
import { VideoGeneration } from '@everworker/oneringai';
// OpenAI Sora
const videoGen = VideoGeneration.create({ connector: 'openai' });
// Start video generation (async - returns a job)
const job = await videoGen.generate({
prompt: 'A cinematic shot of a sunrise over mountains',
model: 'sora-2',
duration: 8,
resolution: '1280x720', // 720x1280 / 1280x720 / 1024x1792 / 1792x1024 (1.4× HD)
});
// Wait for completion
const result = await videoGen.waitForCompletion(job.jobId);
// Download the video
const videoBuffer = await videoGen.download(job.jobId);
await fs.writeFile('./output.mp4', videoBuffer);
// Google Veo
const googleVideo = VideoGeneration.create({ connector: 'google' });
const veoJob = await googleVideo.generate({
prompt: 'A butterfly flying through a garden',
model: 'veo-3.0-generate-001',
duration: 8,
});Sora: extend, remix, edit (OpenAI only)
The Videos API references completed clips by id — pass the jobId returned
by generate(), not a buffer or URL.
// Extend — generate an additional segment after the source clip.
const extension = await videoGen.extend({
model: 'sora-2',
video: job.jobId, // id of a completed video
prompt: 'The camera pulls back to reveal a snow-covered valley',
extendDuration: 8, // length of the *new* segment, snapped to 4/8/12
});
// Remix — same length, prompt-steered re-generation.
const remix = await videoGen.remix({
videoId: job.jobId,
prompt: 'Same composition, but at golden hour',
});
// Edit — apply a prompt-described change to a completed clip.
const edited = await videoGen.edit({
videoId: job.jobId,
prompt: 'Add light snowfall throughout',
});Sora: reusable characters (OpenAI only)
Upload a reference video to register a character; thread the returned id
back through vendorOptions on a later generate().
const character = await videoGen.createCharacter({
name: 'Hero',
video: './reference-shot.mp4', // Buffer | local path | URL
});
// → { id: 'char_…', name: 'Hero' }
const scene = await videoGen.generate({
prompt: 'Hero walks across a windswept beach at dusk',
vendorOptions: { characterId: character.id },
});
// Look up later
const same = await videoGen.getCharacter(character.id);Embeddings (NEW)
import { Embeddings } from '@everworker/oneringai';
// OpenAI embeddings
const embeddings = Embeddings.create({ connector: 'openai' });
const result = await embeddings.embed(['Hello world', 'How are you?'], {
model: 'text-embedding-3-small',
dimensions: 512, // MRL: reduce dimensions for faster search
});
console.log(result.embeddings.length); // 2
console.log(result.embeddings[0].length); // 512
// Ollama (local, free)
const local = Embeddings.create({ connector: 'ollama-local' });
const localResult = await local.embed('search query');
// Uses qwen3-embedding (4096 dims, #1 on MTEB multilingual)Document Reader (NEW)
Read any document format — agents automatically get markdown text from PDFs, Word docs, spreadsheets, and more:
import { Agent, developerTools } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: developerTools,
});
// read_file auto-converts binary documents to markdown
await agent.run('Read /path/to/report.pdf and summarize the key findings');
await agent.run('Read /path/to/data.xlsx and describe the trends');
await agent.run('Read /path/to/presentation.pptx and list all slides');Programmatic usage:
import { DocumentReader, readDocumentAsContent } from '@everworker/oneringai';
// Read any file to markdown pieces
const reader = DocumentReader.create();
const result = await reader.read('/path/to/report.pdf');
console.log(result.pieces); // DocumentPiece[] (text + images)
// One-call conversion to LLM Content[] (for multimodal input)
const content = await readDocumentAsContent('/path/to/slides.pptx', {
imageFilter: { minWidth: 100, minHeight: 100 },
imageDetail: 'auto',
});
const response = await agent.run([
{ type: 'input_text', text: 'Analyze this document:' },
...content,
]);Supported Formats:
- Office: DOCX, PPTX, ODT, ODP, ODS, RTF (via
officeparser) - Spreadsheets: XLSX, CSV (via
exceljs) - PDF (via
unpdf) - HTML (via Readability + Turndown)
- Text: TXT, MD, JSON, XML, YAML
- Images: PNG, JPG, GIF, WEBP, SVG (pass-through as base64)
Web Search
Connector-based web search with multiple providers:
import { Connector, SearchProvider, ConnectorTools, Services, Agent, tools } from '@everworker/oneringai';
// Create search connector
Connector.create({
name: 'serper-main',
serviceType: Services.Serper,
auth: { type: 'api_key', apiKey: process.env.SERPER_API_KEY! },
baseURL: 'https://google.serper.dev',
});
// Option 1: Use SearchProvider directly
const search = SearchProvider.create({ connector: 'serper-main' });
const results = await search.search('latest AI developments 2026', {
numResults: 10,
country: 'us',
language: 'en',
});
// Option 2: Use with Agent via ConnectorTools
const searchTools = ConnectorTools.for('serper-main');
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [...searchTools, tools.webFetch],
});
await agent.run('Search for quantum computing news and summarize');Supported Search Providers:
- Serper - Google search via Serper.dev (2,500 free queries)
- Brave - Independent search index (privacy-focused)
- Tavily - AI-optimized search with summaries
- RapidAPI - Real-time web search (various pricing)
Web Scraping
Enterprise web scraping with automatic fallback and bot protection bypass:
import { Connector, ScrapeProvider, ConnectorTools, Services, Agent, tools } from '@everworker/oneringai';
// Create ZenRows connector for bot-protected sites
Connector.create({
name: 'zenrows',
serviceType: Services.Zenrows,
auth: { type: 'api_key', apiKey: process.env.ZENROWS_API_KEY! },
baseURL: 'https://api.zenrows.com/v1',
});
// Option 1: Use ScrapeProvider directly
const scraper = ScrapeProvider.create({ connector: 'zenrows' });
const result = await scraper.scrape('https://protected-site.com', {
includeMarkdown: true,
vendorOptions: {
jsRender: true, // JavaScript rendering
premiumProxy: true, // Residential IPs
},
});
// Option 2: Use web_scrape tool with Agent via ConnectorTools
const scrapeTools = ConnectorTools.for('zenrows');
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [...scrapeTools, tools.webFetch],
});
// web_scrape auto-falls back: native → API
await agent.run('Scrape https://example.com and summarize');Supported Scrape Providers:
- ZenRows - Enterprise scraping with JS rendering, residential proxies, anti-bot bypass
- Jina Reader - Clean content extraction with AI-powered readability
- Firecrawl - Web scraping with JavaScript rendering
- ScrapingBee - Headless browser scraping with proxy rotation
Supported Providers
| Provider | Text | Vision | TTS | STT | Image | Video | Tools | Context | |----------|------|--------|-----|-----|-------|-------|-------|---------| | OpenAI | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | 128K | | Anthropic (Claude) | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ | 1M | | Google (Gemini) | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | 1M | | Google Vertex AI | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ | ✅ | 1M | | Grok (xAI) | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | 128K | | Groq | ✅ | ❌ | ❌ | ✅ | ❌ | ❌ | ✅ | 128K | | Together AI | ✅ | Some | ❌ | ❌ | ❌ | ❌ | ✅ | 128K | | DeepSeek | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | 64K | | Mistral | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | 32K | | Perplexity | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | 128K | | Ollama | ✅ | Varies | ❌ | ❌ | ❌ | ❌ | ✅ | Varies | | Custom | ✅ | Varies | ❌ | ❌ | ❌ | ❌ | ✅ | Varies |
Key Features
1. Agent with Plugins
The Agent class is the primary agent type, supporting all features through composable plugins:
import { Agent, createFileContextStorage } from '@everworker/oneringai';
// Create storage for session persistence
const storage = createFileContextStorage('my-assistant');
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
userId: 'user-123', // Flows to all tool executions automatically
identities: [ // Only these connectors visible to tools
{ connector: 'github' },
{ connector: 'slack' },
],
tools: [weatherTool, emailTool],
context: {
features: {
workingMemory: true, // Store/retrieve data across turns
inContextMemory: true, // Key-value pairs directly in context
persistentInstructions: true, // Agent instructions that persist to disk
},
agentId: 'my-assistant',
storage,
},
});
// Run the agent
const response = await agent.run('Check weather and email me the report');
console.log(response.output_text);
// Save session for later
await agent.context.save('session-001');Features:
- 🔧 Plugin Architecture - Enable/disable features via
context.features - 💾 Session Persistence - Save/load full state with
ctx.save()andctx.load() - 📝 Working Memory - Store findings with automatic eviction
- 📌 InContextMemory - Key-value pairs visible directly to LLM
- 🔄 Persistent Instructions - Agent instructions that persist across sessions
2. Dynamic Tool Management (NEW)
Control tools at runtime. AgentContextNextGen is the single source of truth - agent.tools and agent.context.tools are the same ToolManager instance:
import { Agent } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [weatherTool, emailTool, databaseTool],
});
// Disable tool temporarily
agent.tools.disable('database_tool');
// Enable later
agent.tools.enable('database_tool');
// UNIFIED ACCESS: Both paths access the same ToolManager
console.log(agent.tools === agent.context.tools); // true
// Changes via either path are immediately reflected
agent.context.tools.disable('email_tool');
console.log(agent.tools.listEnabled().includes('email_tool')); // false
// Context-aware selection
const selected = agent.tools.selectForContext({
mode: 'interactive',
priority: 'high',
});
// Backward compatible
agent.addTool(newTool); // Still works!
agent.removeTool('old_tool'); // Still works!3. Tool Execution Plugins (NEW)
Extend tool execution with custom behavior through a pluggable pipeline architecture. Add logging, analytics, UI updates, permission prompts, or any custom logic:
import { Agent, LoggingPlugin, type IToolExecutionPlugin } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [weatherTool],
});
// Add built-in logging plugin
agent.tools.executionPipeline.use(new LoggingPlugin());
// Create a custom plugin
const analyticsPlugin: IToolExecutionPlugin = {
name: 'analytics',
priority: 100,
async beforeExecute(ctx) {
console.log(`Starting ${ctx.toolName}`);
},
async afterExecute(ctx, result) {
const duration = Date.now() - ctx.startTime;
trackToolUsage(ctx.toolName, duration);
return result; // Must return result (can transform it)
},
async onError(ctx, error) {
reportError(ctx.toolName, error);
return undefined; // Let error propagate (or return value to recover)
},
};
agent.tools.executionPipeline.use(analyticsPlugin);Plugin Lifecycle:
beforeExecute- Modify args, abort execution, or pass through- Tool execution
afterExecute- Transform results (runs in reverse priority order)onError- Handle/recover from errors
Plugin Context (PluginExecutionContext):
interface PluginExecutionContext {
toolName: string; // Name of the tool being executed
args: unknown; // Original arguments (read-only)
mutableArgs: unknown; // Modifiable arguments
metadata: Map<string, unknown>; // Share data between plugins
startTime: number; // Execution start timestamp
tool: ToolFunction; // The tool being executed
executionId: string; // Unique ID for this execution
}Built-in Plugins:
LoggingPlugin- Logs tool execution with timing and result summaries
Pipeline Management:
// Add plugin
agent.tools.executionPipeline.use(myPlugin);
// Remove plugin
agent.tools.executionPipeline.remove('plugin-name');
// Check if registered
agent.tools.executionPipeline.has('plugin-name');
// Get plugin
const plugin = agent.tools.executionPipeline.get('plugin-name');
// List all plugins
const plugins = agent.tools.executionPipeline.list();4. Tool Permissions (NEW)
Policy-based permission system with per-user rules, argument inspection, and pluggable storage. Permissions are enforced at the ToolManager pipeline level -- all tool execution paths are gated.
Zero-Config (Backward Compatible)
Existing code works unchanged. Safe tools (read-only, memory, catalog) are auto-allowed; all others default to prompting:
const agent = Agent.create({ connector: 'openai', model: 'gpt-4.1', tools: [readFile, bash] });
// read_file executes immediately (in DEFAULT_ALLOWLIST)
// bash triggers approval flow (write/shell tools require approval by default)Per-User Permission Rules
User rules have the highest priority -- they override all built-in policies. Rules support argument inspection with conditions:
import { PermissionPolicyManager } from '@everworker/oneringai';
const manager = new PermissionPolicyManager({
userRules: [
// Allow bash, but only in the project directory
{
id: '1', toolName: 'bash', action: 'allow', enabled: true,
createdBy: 'user', createdAt: new Date().toISOString(), updatedAt: new Date().toISOString(),
conditions: [{ argName: 'command', operator: 'not_contains', value: 'rm -rf' }],
},
// Block all web tools unconditionally
{
id: '2', toolName: 'web_fetch', action: 'deny', enabled: true, unconditional: true,
createdBy: 'admin', createdAt: new Date().toISOString(), updatedAt: new Date().toISOString(),
},
],
});Condition operators: starts_with, not_starts_with, contains, not_contains, equals, not_equals, matches (regex), not_matches.
Built-in Policies
Eight composable policies evaluated in priority order (deny short-circuits):
| Policy | Description | |--------|-------------| | AllowlistPolicy | Auto-allow tools in the allowlist (read-only, memory, catalog) | | BlocklistPolicy | Hard-block tools in the blocklist (no approval possible) | | SessionApprovalPolicy | Cache approvals per-session with optional argument-scoped keys | | PathRestrictionPolicy | Restrict file tools to allowed directory roots | | BashFilterPolicy | Block/flag dangerous shell commands by pattern | | UrlAllowlistPolicy | Restrict web tools to allowed URL domains | | RolePolicy | Role-based access control (map user roles to tool permissions) | | RateLimitPolicy | Limit tool invocations per time window |
import { PathRestrictionPolicy, BashFilterPolicy } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai', model: 'gpt-4.1',
permissions: {
policies: [
new PathRestrictionPolicy({ allowedPaths: ['/workspace'] }),
new BashFilterPolicy({ blockedPatterns: ['rm -rf', 'sudo'] }),
],
},
});Approval Dialog Integration
When a tool needs approval, the onApprovalRequired callback fires. Return a createRule to persist the decision:
const agent = Agent.create({
connector: 'openai', model: 'gpt-4.1',
permissions: {
onApprovalRequired: async (ctx) => {
const userChoice = await showApprovalDialog(ctx.toolName, ctx.args);
return {
approved: userChoice.allow,
// Persist as a user rule so it won't ask again
createRule: userChoice.remember ? {
description: `Auto-allow ${ctx.toolName}`,
conditions: [{ argName: 'path', operator: 'starts_with', value: '/workspace' }],
} : undefined,
};
},
},
});Tool Self-Declaration
Tool authors declare permission defaults on the tool definition. App developers can override at registration:
const myTool: ToolFunction = {
definition: { type: 'function', function: { name: 'deploy', description: '...', parameters: {...} } },
execute: async (args) => { /* ... */ },
// Author-declared defaults
permission: {
scope: 'once',
riskLevel: 'high',
approvalMessage: 'This will deploy to production',
sensitiveArgs: ['environment', 'version'],
},
};
// App developer can override at registration
agent.tools.register(myTool, {
permission: { scope: 'session' }, // Relax to session-level approval
});For complete documentation, see the User Guide.
5. Session Persistence
Save and resume full context state including conversation history and plugin states:
import { AgentContextNextGen, createFileContextStorage } from '@everworker/oneringai';
// Create storage for the agent
const storage = createFileContextStorage('my-assistant');
// Create context with storage
const ctx = AgentContextNextGen.create({
model: 'gpt-4.1',
features: { workingMemory: true },
storage,
});
// Build up state
ctx.addUserMessage('Remember: my favorite color is blue');
await ctx.memory?.store('user_color', 'User favorite color', 'blue');
// Save session with metadata
await ctx.save('session-001', { title: 'User Preferences' });
// Later... load session
const ctx2 = AgentContextNextGen.create({ model: 'gpt-4.1', storage });
const loaded = await ctx2.load('session-001');
if (loaded) {
// Full state restored: conversation, plugin states, etc.
const color = await ctx2.memory?.retrieve('user_color');
console.log(color); // 'blue'
}What's Persisted:
- Complete conversation history
- All plugin states (WorkingMemory entries, InContextMemory, etc.)
- System prompt
Storage Location: ~/.oneringai/agents/<agentId>/sessions/<sessionId>.json
Storage Registry
Swap all storage backends (sessions, media, custom tools, OAuth tokens, etc.) with a single configure() call at init time. No breaking changes — all existing APIs continue to work.
import { StorageRegistry } from '@everworker/oneringai';
StorageRegistry.configure({
media: new S3MediaStorage(),
oauthTokens: new EncryptedFileTokenStorage(),
// Context-aware factories — optional StorageContext for multi-tenant partitioning
customTools: (ctx) => new MongoCustomToolStorage(ctx?.userId),
sessions: (agentId, ctx) => new RedisContextStorage(agentId, ctx?.tenantId),
persistentInstructions: (agentId, ctx) => new DBInstructionsStorage(agentId, ctx?.userId),
workingMemory: (ctx) => new RedisMemoryStorage(ctx?.tenantId),
routineDefinitions: (ctx) => new MongoRoutineStorage(ctx?.userId),
});
// All agents and tools automatically use these backends
const agent = Agent.create({ connector: 'openai', model: 'gpt-4.1' });Resolution order: explicit constructor param > StorageRegistry > file-based default.
Multi-tenant: Factories receive an optional StorageContext (opaque, like ConnectorAccessContext). Set via StorageRegistry.setContext({ userId, tenantId }) — auto-forwarded to all factory calls for per-user/per-tenant storage partitioning.
See the User Guide for full documentation.
6. Working Memory
Use the WorkingMemoryPluginNextGen for agents that need to store and retrieve data:
import { Agent } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [weatherTool, emailTool],
context: {
features: { workingMemory: true },
},
});
// Agent now has unified store_get, store_set, store_delete, store_list, store_action tools
await agent.run('Check weather for SF and remember the result');Features:
- 📝 Working Memory - Store and retrieve data with priority-based eviction
- 🏗️ Hierarchical Memory - Raw → Summary → Findings tiers for research tasks
- 🧠 Context Management - Automatic handling of context limits
- 💾 Session Persistence - Save/load via
ctx.save()andctx.load()
7. Research with Search Tools
Use Agent with search tools and WorkingMemoryPluginNextGen for research workflows:
import { Agent, ConnectorTools, Connector, Services, tools } from '@everworker/oneringai';
// Setup search connector
Connector.create({
name: 'serper-main',
serviceType: Services.Serper,
auth: { type: 'api_key', apiKey: process.env.SERPER_API_KEY! },
baseURL: 'https://google.serper.dev',
});
// Create agent with search and memory
const searchTools = ConnectorTools.for('serper-main');
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [...searchTools, tools.webFetch],
context: {
features: { workingMemory: true },
},
});
// Agent can search and store findings in memory
await agent.run('Research AI developments in 2026 and store key findings');Features:
- 🔍 Web Search - SearchProvider with Serper, Brave, Tavily, RapidAPI
- 📝 Working Memory - Store findings with priority-based eviction
- 🏗️ Tiered Memory - Raw → Summary → Findings pattern
8. Context Management
AgentContextNextGen is the modern, plugin-based context manager. It provides clean separation of concerns with composable plugins:
import { Agent, AgentContextNextGen } from '@everworker/oneringai';
// Option 1: Use AgentContextNextGen directly (standalone)
const ctx = AgentContextNextGen.create({
model: 'gpt-4.1',
systemPrompt: 'You are a helpful assistant.',
features: { workingMemory: true, inContextMemory: true },
});
ctx.addUserMessage('What is the weather in Paris?');
const { input, budget } = await ctx.prepare(); // Ready for LLM call
// Option 2: Via Agent.create
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
context: {
features: { workingMemory: true },
},
});
// Agent uses AgentContextNextGen internally
await agent.run('Check the weather');Feature Configuration
Enable/disable features independently. Disabled features = no associated tools registered:
// Minimal stateless agent (no memory)
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
context: {
features: { workingMemory: false }
}
});
// Full-featured agent with all plugins
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
context: {
features: {
workingMemory: true,
inContextMemory: true,
persistentInstructions: true
},
agentId: 'my-assistant', // Required for persistentInstructions
}
});Available Features:
| Feature | Default | Plugin | Associated Tools |
|---------|---------|--------|------------------|
| workingMemory | true | WorkingMemoryPluginNextGen | Unified store_* tools (store="memory"). Actions: cleanup_raw, query |
| inContextMemory | true | InContextMemoryPluginNextGen | Unified store_* tools (store="context") |
| persistentInstructions | false | PersistentInstructionsPluginNextGen | Unified store_* tools (store="instructions"). Actions: clear |
| userInfo | false | UserInfoPluginNextGen | Unified store_* tools (store="user_info") + todo_add/update/remove |
| toolCatalog | false | ToolCatalogPluginNextGen | tool_catalog_search/load/unload |
| sharedWorkspace | false | SharedWorkspacePluginNextGen | Unified store_* tools (store="workspace"). Actions: log, history, archive, clear |
| memory | false | MemoryPluginNextGen | 6 read tools: memory_recall, memory_graph, memory_search, memory_search_documents, memory_find_entity, memory_list_facts. Requires plugins.memory.memory: MemorySystem. |
| memoryWrite | false | MemoryWritePluginNextGen | 6 write tools: memory_remember, memory_link, memory_upsert_entity, memory_forget, memory_restore, memory_set_agent_rule. Requires memory: true. |
AgentContextNextGen architecture:
- Plugin-first design - All features are composable plugins
- ToolManager - Tool registration, execution, circuit breakers
- Single system message - All context components combined
- Smart compaction - Happens once, right before LLM call
Compaction strategy:
- algorithmic (default) - Moves large tool results to Working Memory, limits tool pairs, applies rolling window. Triggers at 75% context usage.
Context preparation:
const { input, budget, compacted, compactionLog } = await ctx.prepare();
console.log(budget.totalUsed); // Total tokens used
console.log(budget.available); // Remaining tokens
console.log(budget.utilizationPercent); // Usage percentage9. InContextMemory
Store key-value pairs directly in context for instant LLM access without retrieval calls:
import { AgentContextNextGen } from '@everworker/oneringai';
const ctx = AgentContextNextGen.create({
model: 'gpt-4.1',
features: { inContextMemory: true },
plugins: {
inContextMemory: { maxEntries: 20 },
},
});
// Access the plugin
const plugin = ctx.getPlugin('in_context_memory');
// Store data - immediately visible to LLM
plugin.set('current_state', 'Task processing state', { step: 2, status: 'active' });
plugin.set('user_prefs', 'User preferences', { verbose: true }, 'high');
// Store data with UI display - shown in the host app's sidebar panel
plugin.set('dashboard', 'Progress dashboard', '## Progress\n- [x] Step 1\n- [ ] Step 2', 'normal', true);
// LLM uses unified store tools: store_set("whiteboard", ...), store_get("whiteboard", ...), etc.
// Or access directly via plugin API
const state = plugin.get('current_state'); // { step: 2, status: 'active' }Key Difference from WorkingMemory:
- WorkingMemory: External storage + index → requires
store_get("notes", key)for values - InContextMemory: Full values in context → instant access, no retrieval needed
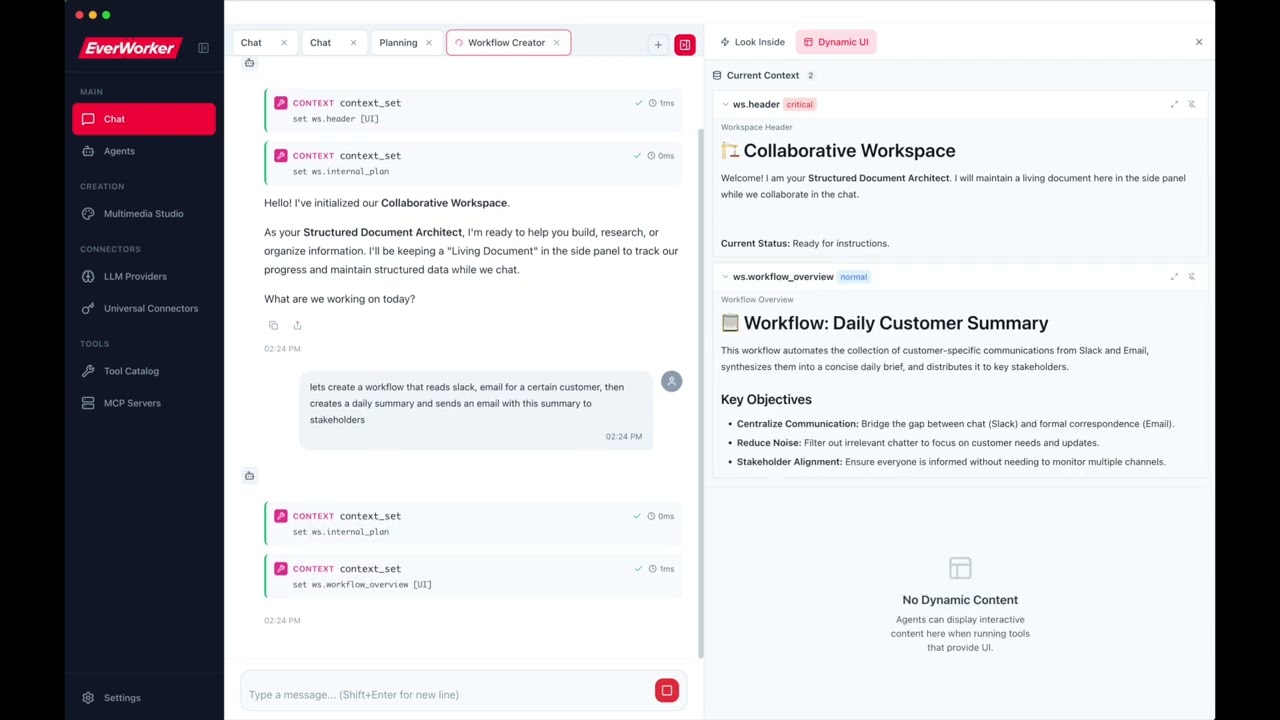
UI Display (showInUI): Entries with showInUI: true are displayed in the host application's sidebar panel with full markdown rendering (code blocks, tables, charts, diagrams, etc.). The LLM sets this via store_set("whiteboard", key, { ..., showInUI: true }). Users can also pin specific entries to always display them regardless of the agent's setting. See the User Guide for details.
Use cases: Session state, user preferences, counters, flags, small accumulated results, live dashboards.
10. Persistent Instructions
Store agent-level custom instructions that persist across sessions on disk:
import { Agent } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
context: {
agentId: 'my-assistant', // Required for storage path
features: {
persistentInstructions: true,
},
},
});
// LLM uses unified store tools: store_set("instructions", ...), store_delete("instructions", ...), etc.
// Instructions persist to ~/.oneringai/agents/my-assistant/custom_instructions.jsonKey Features:
- 📁 Disk Persistence - Instructions survive process restarts and sessions
- 🔧 LLM-Modifiable - Agent can update its own instructions during execution
- 🔄 Auto-Load - Instructions loaded automatically on agent start
- 🛡️ Never Compacted - Critical instructions always preserved in context
Store Tools (via unified store_* interface):
store_set("instructions", key, { content })- Add or update a single instruction by keystore_delete("instructions", key)- Remove a single instruction by keystore_list("instructions")- List all instructions with keys and contentstore_action("instructions", "clear", { confirm: true })- Remove all instructions
Use cases: Agent personality/behavior, user preferences, learned rules, tool usage patterns.
11. User Info
Store user-specific preferences and context that are automatically injected into the LLM system message:
import { Agent } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
userId: 'alice', // Optional — defaults to 'default' user
context: {
features: {
userInfo: true,
},
},
});
// LLM uses unified store tools: store_set("user_info", ...), store_get("user_info", ...), etc.
// Data persists to ~/.oneringai/users/alice/user_info.json
// All entries are automatically shown in context — no need to call store_get each turnKey Features:
- 📁 Disk Persistence - User info survives process restarts and sessions
- 🔄 Auto-Inject - Entries rendered as markdown and included in the system message automatically
- 👥 User-Scoped - Data is per-user, not per-agent — different agents share the same user data
- 🔧 LLM-Modifiable - Agent can update user info during execution
Store Tools (via unified store_* interface):
store_set("user_info", key, { value, description? })- Store/update user informationstore_get("user_info", key?)- Retrieve one entry or all entriesstore_delete("user_info", key)- Remove a specific entrystore_action("user_info", "clear", { confirm: true })- Clear all entries
TODO Tools (built into the same plugin):
todo_add- Create a TODO (title,description?,people?,dueDate?,tags?)todo_update- Update a TODO (id, plus any fields to change includingstatus: 'done')todo_remove- Delete a TODO by id
TODOs are stored alongside user info and rendered in a separate "Current TODOs" checklist in context. The agent proactively suggests creating TODOs when conversation implies action items, reminds about due/overdue items once per day, and auto-cleans completed TODOs after 48 hours.
Use cases: User preferences (theme, language, timezone), user context (role, location), accumulated knowledge about the user, task/TODO tracking with deadlines and people.
⚠️ Deprecated in favour of the Self-Learning Memory plugin below.
UserInfoPluginNextGen+PersistentInstructionsPluginNextGenkeep working unchanged for existing integrations — no breaking change — but new code should preferMemoryPluginNextGen.
10b. Self-Learning Memory — plugin + tools
A brain-like, queryable knowledge store built on the memory layer. Two cooperating context plugins + 11 LLM-callable tools turn the agent into a learning system: it bootstraps a person entity for the user (and optionally an organization entity for their group), injects the evolving user profile + any user-given behavior rules into the system message every turn, and exposes memory_* tools so the LLM can read or write the knowledge graph mid-conversation. Observations flow in via memory_remember (LLM-driven) or SessionIngestorPluginNextGen (passive); incremental profile regeneration synthesises them; the next turn sees the updated profile. No manual prompt engineering for user/agent preferences.
import { Agent, createMemorySystemWithConnectors, InMemoryAdapter } from '@everworker/oneringai';
const memory = createMemorySystemWithConnectors({
store: new InMemoryAdapter(), // or MongoMemoryAdapter for production
connectors: {
embedding: { connector: 'openai', model: 'text-embedding-3-small', dimensions: 1536 },
profile: { connector: 'anthropic', model: 'claude-sonnet-4-6' },
},
});
const agent = Agent.create({
connector: 'anthropic',
model: 'claude-sonnet-4-6',
userId: 'alice', // REQUIRED — memory's owner invariant
context: {
agentId: 'my-assistant',
features: {
memory: true, // reads: profile injection + 5 retrieval tools
memoryWrite: true, // writes: 6 mutation tools (omit for retrieval-only)
},
plugins: {
memory: {
memory,
// groupId: 'team-A', // trusted, from your auth layer
// userProfileInjection: { topFacts: 20, relatedTasks: true },
// groupBootstrap: { displayName: 'Acme', identifiers: [{ kind: 'domain', value: 'acme.com' }] },
},
},
},
});
await agent.run('Remember I prefer concise answers');
// Agent calls memory_remember({subject:"me", predicate:"prefers", value:"concise answers"})
// Fact stored → profile regen fires in background → next turn sees it in the user profileKey Features:
- 🧠 Self-learning — profiles synthesised from facts via incremental regeneration (prior profile + new facts + invalidated IDs → evolved profile)
- 🔐 Three-principal permissions — owner / group / world, enforced at the adapter
- 📊 Ranked recall — profile + top facts by
confidence × recency × predicateWeight × importance - 🕸️ Graph queries — Mongo native
$graphLookupwhen available, iterative BFS fallback - 🔍 Semantic search — over embedded facts (with Atlas Vector Search at scale)
- 🧬 Multi-ID entities — lookup by email / slack_id / github_login / domain / any identifier; upsert auto-merges
- 📜 Supersession history — corrections archive predecessors; audit chain preserved via
archivedOnly: true - 🪧 User-driven behavior rules —
memory_set_agent_rulerecords "be terse" / "reply in Russian" / "your name is Jason" directives, rendered back into the system message every turn (per-user-per-agent scoped) - 🏢 Optional org bootstrap — when
groupBootstrapis set, anorganizationentity is upserted and rendered as a separate "Your Organization Profile" block alongside the user profile - 🛡️ LLM-safe —
groupIdfixed by host app (never from tool args); ghost-write protection;contextIdsauto-downgrade; numeric limits clamped
12 LLM tools (memory_*), split into two opt-in bundles:
Read (via MemoryPluginNextGen, feature flag memory):
memory_recall(subject, include?)— profile + top facts + optional tiers (documents/semantic/neighbors)memory_graph(start, direction, maxDepth, predicates?)— N-hop traversalmemory_search(query, topK?, filter?)— semantic text search across factsmemory_search_documents(query, mode?, attachedTo?, role?, limit?)— search long-form documents (type='document') by content. Semantic mode matchescontentEmbedding; keyword mode is case-insensitive substring over body + title.memory_find_entity(by, action? ∈ {find, list})— lookup or list (read-only)memory_list_facts(subject, predicate?, archivedOnly?)— structured enumeration
Write (via MemoryWritePluginNextGen, feature flag memoryWrite, requires memory: true):
memory_remember(subject, predicate, value?/objectId?/details?, visibility?)— write a fact (atomic or document)memory_link(from, predicate, to)— write a relational factmemory_upsert_entity(type, displayName, identifiers, ...)— create or merge an entity by identifiermemory_forget(factId, replaceWith?)— archive or supersede (rate-limited 10/60s/user)memory_restore(factId)— un-archive (undo formemory_forget)memory_set_agent_rule(rule, replaces?)— record a user-specific behavior rule for THIS agent
Enable memory: true alone for retrieval-only agents (and pair with SessionIngestorPluginNextGen for passive background learning); enable both flags for agents that write memory deliberately.
Flexible SubjectRef — every tool accepts any of: entity id, "me", "this_agent", {id}, {identifier: {kind, value}}, {surface: "..."}.
Storage backends: InMemoryAdapter (zero deps, dev/tests), MongoMemoryAdapter + RawMongoCollection (production servers — supports native $graphLookup + Atlas Vector Search via ensureVectorSearchIndexes()), MongoMemoryAdapter + MeteorMongoCollection (Meteor apps — reactive publications). Custom adapters implement IMemoryStore.
See the USER_GUIDE Self-Learning Memory section for the user-guide-level walkthrough, docs/MEMORY_GUIDE.md for the full conceptual model + adapter setup + signal ingestion, docs/MEMORY_API.md for the MemorySystem API reference, and docs/MEMORY_PERMISSIONS.md for the permission model.
12. Direct LLM Access
Bypass all context management for simple, stateless LLM calls:
const agent = Agent.create({ connector: 'openai', model: 'gpt-4.1' });
// Direct call - no history tracking, no memory, no context preparation
const response = await agent.runDirect('What is 2 + 2?');
console.log(response.output_text); // "4"
// With options
const response = await agent.runDirect('Summarize this', {
instructions: 'Be concise',
temperature: 0.5,
maxOutputTokens: 100,
});
// Multimodal (text + image)
const response = await agent.runDirect([
{ type: 'message', role: 'user', content: [
{ type: 'input_text', text: 'What is in this image?' },
{ type: 'input_image', image_url: 'https://example.com/image.png' }
]}
]);
// Streaming
for await (const event of agent.streamDirect('Tell me a story')) {
if (event.type === 'output_text_delta') {
process.stdout.write(event.delta);
}
}Comparison:
| Aspect | run() | runDirect() |
|--------|-------------------|---------------|
| History tracking | ✅ | ❌ |
| Memory/Cache | ✅ | ❌ |
| Context preparation | ✅ | ❌ |
| Agentic loop (tool execution) | ✅ | ❌ |
| Overhead | Full context management | Minimal |
Use cases: Quick one-off queries, embeddings-like simplicity, testing, hybrid workflows.
Thinking / Reasoning (Per-Call)
Control reasoning effort per call — vendor-agnostic API that maps to OpenAI's reasoning_effort, Anthropic's budget_tokens, and Google's thinkingBudget:
const agent = Agent.create({ connector: 'anthropic', model: 'claude-sonnet-4-6' });
// Set reasoning at agent level (applies to all calls)
const agent2 = Agent.create({
connector: 'openai', model: 'o3-mini',
thinking: { enabled: true, effort: 'medium' },
});
// Override per call via RunOptions
const deep = await agent.run('Prove this theorem', {
thinking: { enabled: true, budgetTokens: 16384 },
});
const quick = await agent.run('What is 2+2?', {
thinking: { enabled: true, effort: 'low' },
});
// Streaming with reasoning
for await (const event of agent.stream('Analyze this code', {
thinking: { enabled: true, effort: 'high' },
})) { /* ... */ }
// Also works with runDirect()
const resp = await agent.runDirect('Quick question', {
thinking: { enabled: true, effort: 'medium' },
});RunOptions (for run() / stream()): thinking, temperature, vendorOptions — override agent-level config for a single call.
13. Audio Capabilities
Text-to-Speech and Speech-to-Text with multiple providers:
import { TextToSpeech, SpeechToText } from '@everworker/oneringai';
// === Text-to-Speech ===
const tts = TextToSpeech.create({
connector: 'openai',
model: 'tts-1-hd', // or 'gpt-4o-mini-tts' for instruction steering
voice: 'nova',
});
// Synthesize to file
await tts.toFile('Hello, world!', './output.mp3');
// Synthesize with options
const audio = await tts.synthesize('Speak slowly', {
format: 'wav',
speed: 0.75,
});
// Introspection
const voices = await tts.listVoices();
const models = tts.listAvailableModels();
// === Speech-to-Text ===
const stt = SpeechToText.create({
connector: 'openai',
model: 'whisper-1', // or 'gpt-4o-transcribe'
});
// Transcribe
const result = await stt.transcribeFile('./audio.mp3');
console.log(result.text);
// With timestamps
const detailed = await stt.transcribeWithTimestamps(audioBuffer, 'word');
console.log(detailed.words); // [{ word, start, end }, ...]
// Translation
const english = await stt.translate(frenchAudio);Streaming TTS — for real-time voice applications:
// Stream audio chunks as they arrive from the API
for await (const chunk of tts.synthesizeStream('Hello!', { format: 'pcm' })) {
if (chunk.audio.length > 0) playPCMChunk(chunk.audio); // 24kHz 16-bit LE mono
if (chunk.isFinal) break;
}
// VoiceStream wraps agent text streams with interleaved audio events
const voice = VoiceStream.create({
ttsConnector: 'openai', ttsModel: 'tts-1-hd', voice: 'nova',
});
for await (const event of voice.wrap(agent.stream('Tell me a story'))) { ... }Available Models:
- TTS: OpenAI (
tts-1,tts-1-hd,gpt-4o-mini-tts), Google (gemini-tts) - STT: OpenAI (
whisper-1,gpt-4o-transcribe), Groq (whisper-large-v3- 12x cheaper!)
Embeddings (NEW)
Generate text embeddings across multiple vendors with a unified API. Supports Matryoshka Representation Learning (MRL) for flexible output dimensions.
import { Embeddings, Connector, Vendor } from '@everworker/oneringai';
// Setup
Connector.create({
name: 'openai',
vendor: Vendor.OpenAI,
auth: { type: 'api_key', apiKey: process.env.OPENAI_API_KEY! },
});
const embeddings = Embeddings.create({ connector: 'openai' });
// Single text
const result = await embeddings.embed('Hello world');
console.log(result.embeddings[0].length); // 1536 (default for text-embedding-3-small)
// Batch with custom dimensions (MRL)
const batch = await embeddings.embed(
['search query', 'document chunk 1', 'document chunk 2'],
{ dimensions: 512 }
);
console.log(batch.embeddings.length); // 3
console.log(batch.embeddings[0].length); // 512
// Local with Ollama (free, no API key)
Connector.create({
name: 'ollama-local',
vendor: Vendor.Ollama,
auth: { type: 'none' },
baseURL: 'http://localhost:11434/v1',
});
const local = Embeddings.create({ connector: 'ollama-local' });
const localResult = await local.embed('semantic search query');
// Uses qwen3-embedding by default (4096 dims, #1 on MTEB multilingual)Model introspection and cost estimation:
import {
getEmbeddingModelInfo,
getEmbeddingModelsByVendor,
calculateEmbeddingCost,
EMBEDDING_MODELS,
Vendor,
} from '@everworker/oneringai';
// Model details
const info = getEmbeddingModelInfo('text-embedding-3-small');
console.log(info.capabilities.maxDimensions); // 1536
console.log(info.capabilities.features.matryoshka); // true (supports MRL)
console.log(info.capabilities.maxTokens); // 8191
// Cost estimation
const cost = calculateEmbeddingCost('text-embedding-3-small', 1_000_000);
console.log(`$${cost} per 1M tokens`); // $0.02
// Browse models by vendor
const ollamaModels = getEmbeddingModelsByVendor(Vendor.Ollama);
console.log(ollamaModels.map(m => `${m.name} (${m.capabilities.defaultDimensions}d)`));
// ['qwen3-embedding (4096d)', 'qwen3-embedding:4b (4096d)', 'qwen3-embedding:0.6b (1024d)', ...]Available Embedding Models:
| Vendor | Model | Dims | MRL | Tokens | Price/1M |
|--------|-------|------|-----|--------|----------|
| OpenAI | text-embedding-3-small | 1536 | yes | 8191 | $0.02 |
| OpenAI | text-embedding-3-large | 3072 | yes | 8191 | $0.13 |
| Google | text-embedding-004 | 768 | yes | 2048 | Free |
| Mistral | mistral-embed | 1024 | no | 8192 | $0.10 |
| Ollama | qwen3-embedding (8B) | 4096 | yes | 8192 | Free (local) |
| Ollama | qwen3-embedding:0.6b | 1024 | yes | 8192 | Free (local) |
| Ollama | nomic-embed-text | 768 | yes | 8192 | Free (local) |
14. Model Registry
Complete metadata for 60+ models with pricing, context windows, and feature flags:
import { getModelInfo, calculateCost, LLM_MODELS, Vendor } from '@everworker/oneringai';
// Get model information
const model = getModelInfo('gpt-5.2');
console.log(model.features.input.tokens); // 400000
console.log(model.features.input.cpm); // 1.75 (cost per million)
// Calculate costs
const cost = calculateCost('gpt-5.2', 50_000, 2_000);
console.log(`Cost: $${cost}`); // $0.1155
// With caching
const cachedCost = calculateCost('gpt-5.2', 50_000, 2_000, {
useCachedInput: true
});
console.log(`Cached: $${cachedCost}`); // $0.0293 (90% discount)Available Models:
- OpenAI (40+): GPT-5.5 (flagship), GPT-5.4 (+ pro / mini / nano), GPT-5.3, GPT-5.2, GPT-5.1, GPT-5, GPT-4.1, GPT-4o, o3, o4-mini, o1, Deep Research, Audio, Realtime, Open-Source
- Anthropic (9): Claude 4.6 (Opus, Sonnet), Claude 4.5, Claude 4.1, Claude 4, Claude 3.7 Sonnet, Haiku 4.5
- Google (10): Gemini 3.1, Gemini 3, Gemini 2.5
- Grok (5): Grok 4.20 (reasoning, non-reasoning, multi-agent), Grok 4.1 Fast
15. Streaming
Real-time responses:
import { StreamHelpers } from '@everworker/oneringai';
for await (const text of StreamHelpers.textOnly(agent.stream('Hello'))) {
process.stdout.write(text);
}16. OAuth for External APIs
import { OAuthManager, FileStorage } from '@everworker/oneringai';
const oauth = new OAuthManager({
flow: 'authorization_code',
clientId: process.env.GITHUB_CLIENT_ID!,
clientSecret: process.env.GITHUB_CLIENT_SECRET!,
authorizationUrl: 'https://github.com/login/oauth/authorize',
tokenUrl: 'https://github.com/login/oauth/access_token',
storage: new FileStorage({ directory: './tokens' }),
});
const authUrl = await oauth.startAuthFlow('user123');17. Developer Tools
File system and shell tools for building coding assistants:
import { developerTools } from '@everworker/oneringai';
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: developerTools, // Includes all 11 tools
});
// Agent can now:
// - Read files (read_file)
// - Write files (write_file)
// - Edit files with surgical precision (edit_file)
// - Search files by pattern (glob)
// - Search content with regex (grep)
// - List directories (list_directory)
// - Execute shell commands (bash)
// - Start dev servers (dev_server)
// - Manage background processes (bg_process_output, bg_process_list, bg_process_kill)
await agent.run('Read package.json and tell me the dependencies');
await agent.run('Find all TODO comments in the src directory');
await agent.run('Run npm test and report any failures');Available Tools:
- read_file - Read file contents with line numbers
- write_file - Create/overwrite files
- edit_file - Surgical find/replace edits
- glob - Find files by pattern (
**/*.ts) - grep - Search content with regex
- list_directory - List directory contents
- bash - Execute shell commands with safety guards
- dev_server - Start a development server in the background
- bg_process_output - Read output from a background process
- bg_process_list - List running background processes
- bg_process_kill - Stop a background process
Safety Features:
- Blocked dangerous commands (
rm -rf /, fork bombs) - Configurable blocked directories (
node_modules,.git) - Timeout protection (default 2 min)
- Output truncation for large outputs
18. Custom Tool Generation (NEW)
Let agents create their own tools at runtime — draft, test, iterate, save, and reuse. The agent writes JavaScript code, validates it, tests it in the VM sandbox, and persists it for future use. All 6 meta-tools are auto-registered and visible in Everworker Desktop.
import { createCustomToolMetaTools, hydrateCustomTool } from '@everworker/oneringai';
// Give an agent the ability to create tools
const agent = Agent.create({
connector: 'openai',
model: 'gpt-4.1',
tools: [...createCustomToolMetaTools()],
});
// The agent can now: draft → test → save tools autonomously
await agent.run('Create a tool that fetches weather data from the OpenWeather API');
// Later: load and use a saved tool
import { createFileCustomToolStorage } from '@everworker/oneringai';
const storage = createFileCustomToolStorage();
const definition = await storage.load(undefined, 'fetch_weather'); // undefined = default user
const weatherTool = hydrateCustomTool(definition!);
// Register on any agent
agent.tools.register(weatherTool, { source: 'custom', tags: ['weather', 'api'] });Meta-Tools: custom_tool_draft (validate), custom_tool_test (execute in sandbox), custom_tool_save (persist), custom_tool_list (search), custom_tool_load (retrieve), custom_tool_delete (remove)
Dynamic Descriptions: Draft and test tools use descriptionFactory to show all available connectors and the full sandbox API — automatically updated when connectors are added or removed.
Pluggable Storage: Default FileCustomToolStorage saves to ~/.oneringai/users/<userId>/custom-tools/ (defaults to ~/.oneringai/users/default/custom-tools/ when no userId). Implement ICustomToolStorage for MongoDB, S3, or any backend.
See the User Guide for the complete workflow, sandbox API reference, and examples.
19. Desktop Automation Tools (NEW)
OS-level desktop automation for building "computer use" agents — screenshot the screen, send to a vision model, receive tool calls (click, type, etc.), execute them, r