
@mrclrchtr/supi-web
v1.12.0
Published
SuPi Web extension — fetch web pages as clean Markdown (web_fetch_md) and library docs via Context7 (web_docs_search, web_docs_fetch)
Maintainers
 mrclrchtr
mrclrchtrReadme
@mrclrchtr/supi-web
Adds web-page fetching and library-documentation lookup tools to the pi coding agent.
Install
pi install npm:@mrclrchtr/supi-webFor local development:
pi install ./packages/supi-web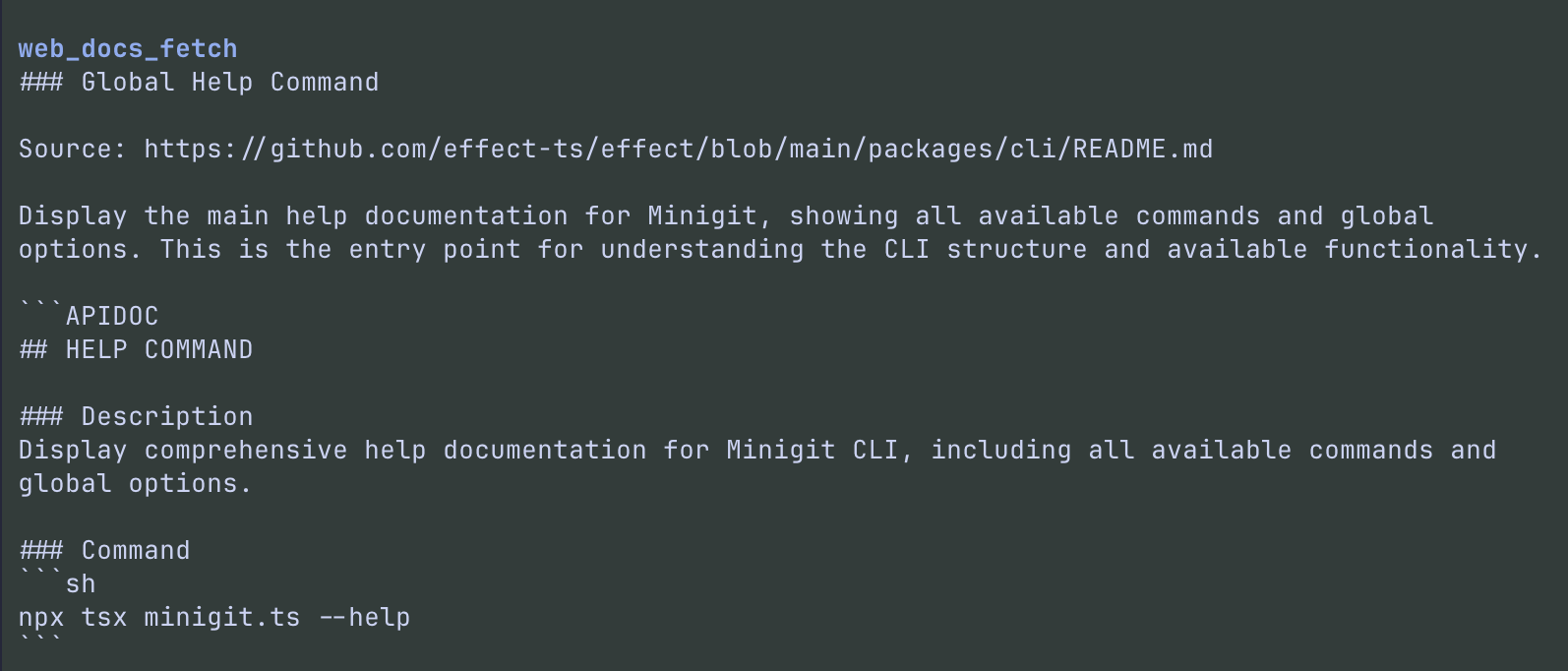
What you get
After install, pi gets three tools:
| Tool | Purpose |
|------|---------|
| web_fetch_md | Fetch a web page and convert it to clean Markdown for LLM ingestion |
| web_docs_search | Search Context7 for library IDs and metadata before fetching docs |
| web_docs_fetch | Fetch up-to-date documentation for a known Context7 library |
web_fetch_md
Fetches a public URL and returns clean Markdown.
Parameters
| Parameter | Type | Required | Default | Description |
|-----------|------|----------|---------|-------------|
| url | string | ✓ | — | http:// or https:// URL to fetch |
| output_mode | "auto" | "inline" | "file" | — | "auto" | How to return the result |
| abs_links | boolean | — | true | Absolutize relative links and images |
| timeout_ms | number | — | 30000 | Fetch timeout in milliseconds |
Output modes
auto— returns Markdown inline if ≤15,000 characters; otherwise writes to a temporary file and returns the pathinline— always returns Markdown inlinefile— always writes to a temporary file and returns the path
Behavior
- Only accepts real
http://orhttps://URLs - Access-controlled pages (login, paywall) should be skipped — ask the user for an allowed source instead
- Plain-text responses are wrapped in fenced code blocks
- Links and images are absolutized by default; set
abs_links: falseto keep them relative
web_docs_search
Searches Context7 for library IDs before fetching documentation.
Parameters
| Parameter | Type | Required | Description |
|-----------|------|----------|-------------|
| library_name | string | ✓ | Library name to search for (e.g. "react", "next.js") |
| query | string | ✓ | What you're trying to do — used for relevance ranking |
Results return as a Markdown table with library ID, name, description, trust score, benchmark score, snippet count, and available versions.
web_docs_fetch
Retrieves documentation context for a known Context7 library.
Parameters
| Parameter | Type | Required | Default | Description |
|-----------|------|----------|---------|-------------|
| library_id | string | ✓ | — | Context7 library ID (e.g. /facebook/react, /vercel/next.js) |
| query | string | ✓ | — | Specific question about the library |
| raw | boolean | — | false | When true, returns JSON-serialized snippet objects instead of Markdown |
Default mode returns pre-formatted Markdown. Set raw: true when you need structured JSON for programmatic use.
Typical workflow
web_docs_search— find the right library ID- Pick a
library_idfrom the results web_docs_fetch— retrieve focused, version-aware docs
Skip step 1 if you already know the exact Context7 library_id.
Context7 API key
web_docs_search and web_docs_fetch use Context7 through @upstash/context7-sdk.
If CONTEXT7_API_KEY is set in your environment, the SDK uses it automatically for higher rate limits. Without a key, the tools still work with lower defaults.