
@pspdfkit/pdf-to-markdown
v0.4.0
Published
Standalone CLI for Nutrient's document extractors — PDF to Markdown, PDF to text, and ranked query over extracted files





Readme
Nutrient PDF to Markdown

Stop wasting your context window on PDF extraction.
Fast, accurate Markdown from PDFs — locally, with no cleanup required. Built for Claude, Codex, RAG pipelines, and document-heavy automation where noisy extraction burns tokens and makes downstream results less reliable.
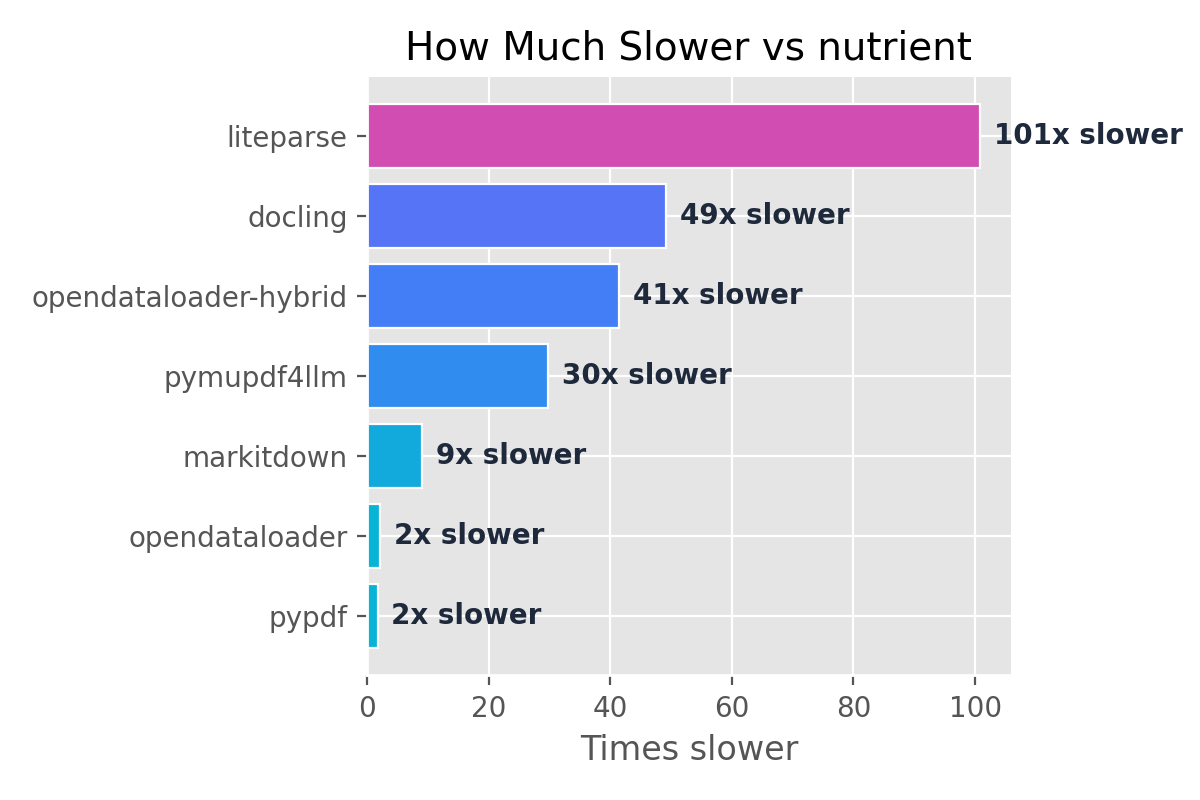
- How fast is it? — 0.011s per page. 48x faster than docling, 29x faster than pymupdf4llm. (benchmarks)
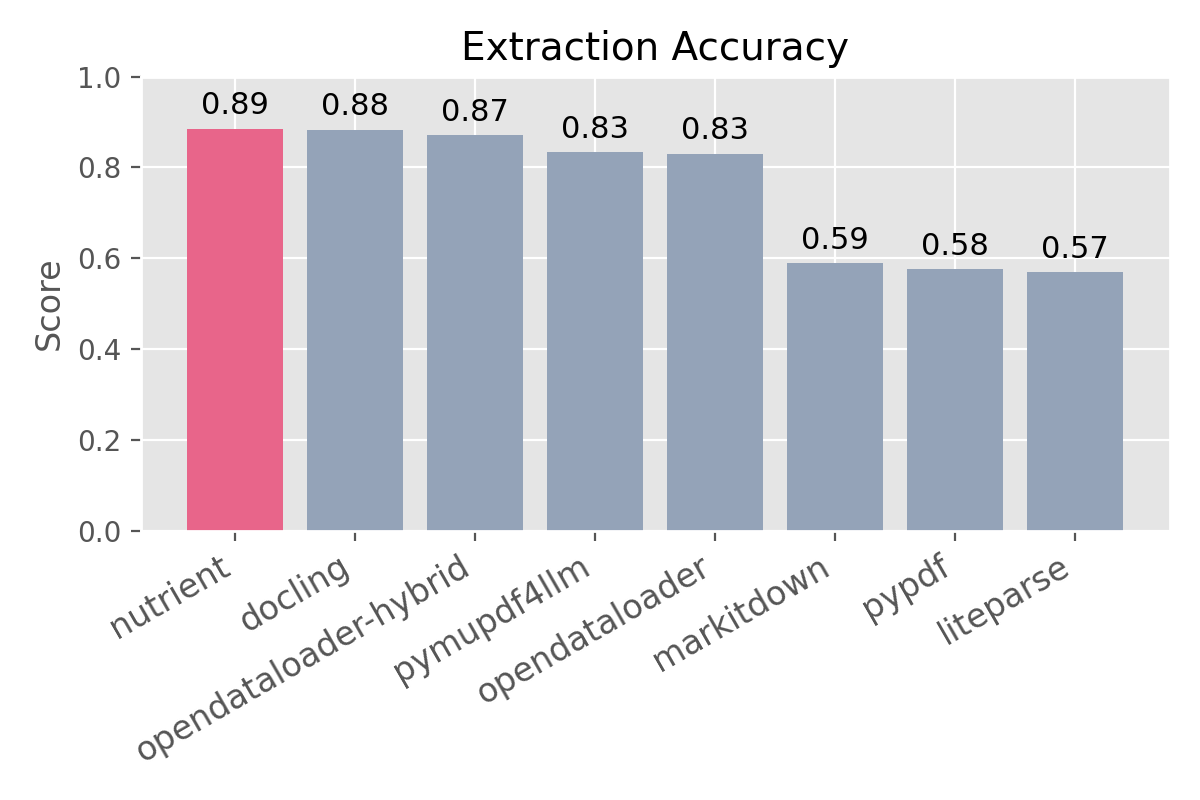
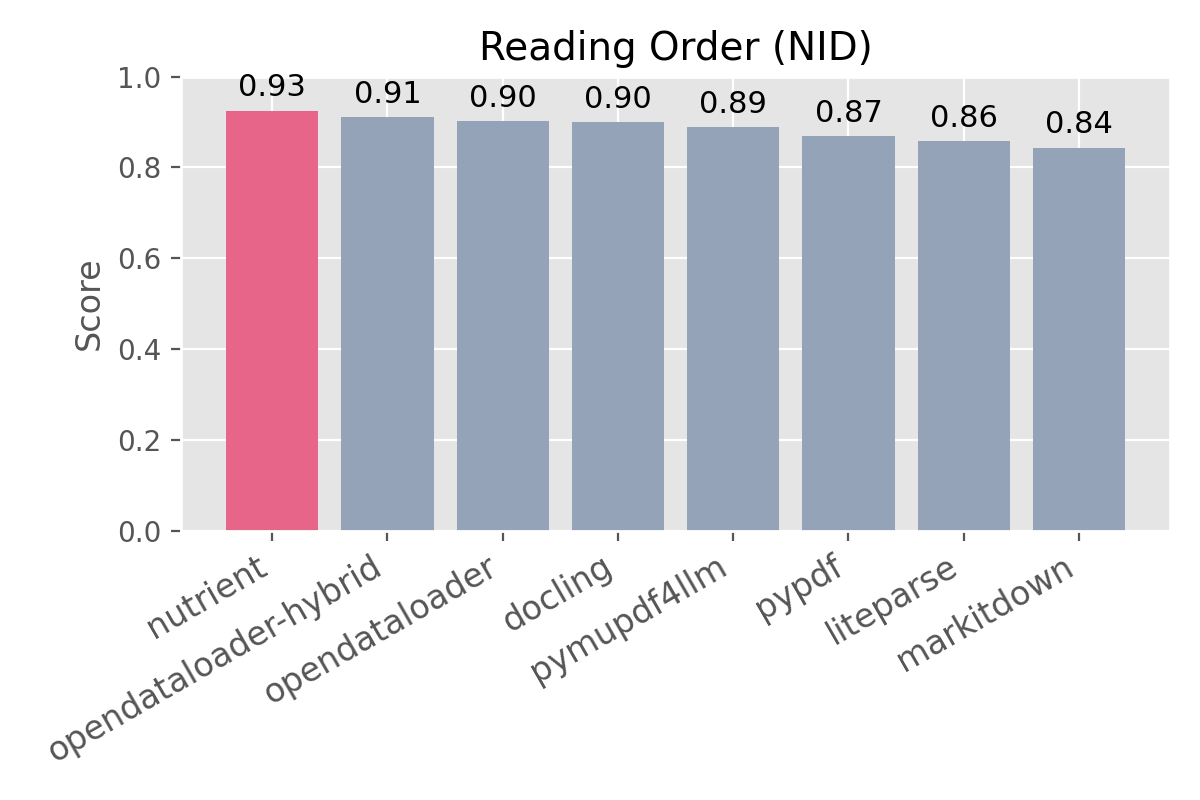
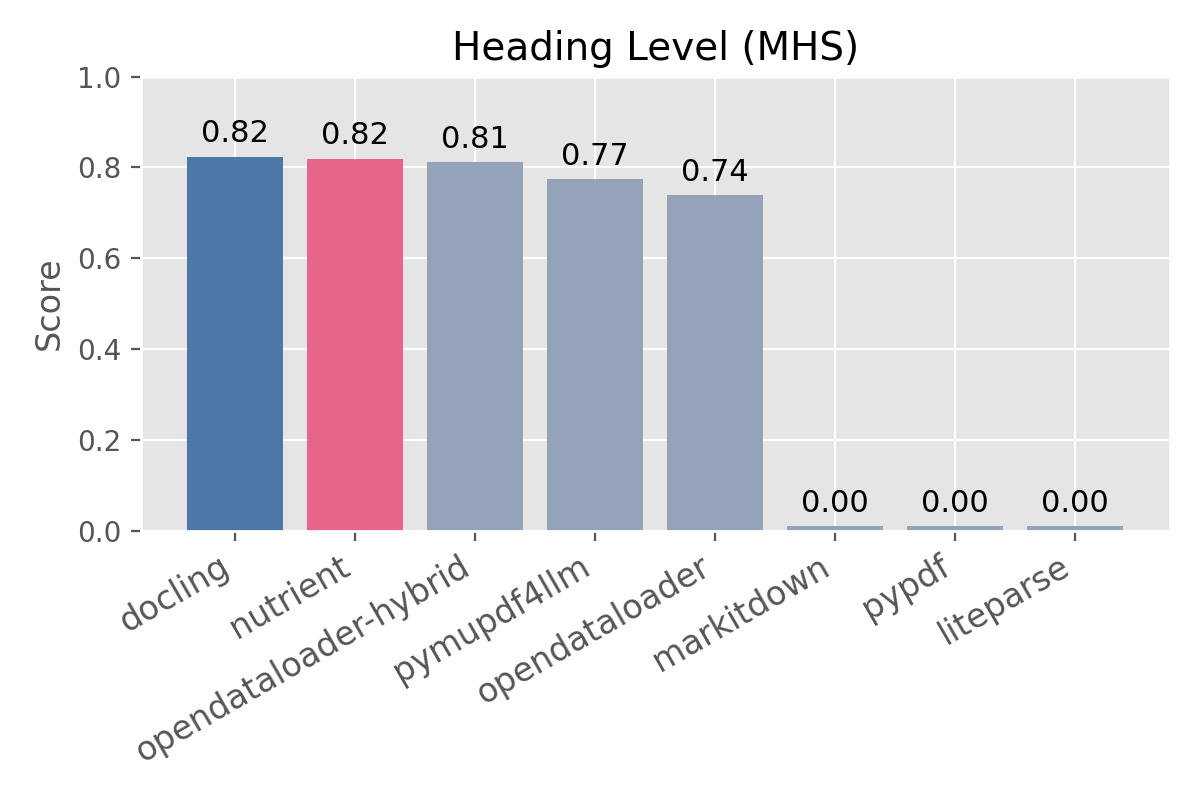
- How accurate is it? — 0.93 reading order (best in class), 0.89 overall extraction accuracy, 0.82 heading detection. (benchmarks)
- Three tools, one binary —
pdf-to-markdownfor structured Markdown,pdf-to-textfor layout-preserving plain text, andqueryfor ranked search over an extracted file. Pick by what the downstream consumer needs. (the Nutrient document CLI) - NEW: Image export —
--enable-image-exportextracts images alongside Markdown for vision-capable LLMs. (usage) - Where do my PDFs go? — Nowhere. The CLI runs locally. Your documents are not uploaded to Nutrient. (trust & licensing)
- What does it cost? — Free for up to 1,000 documents per calendar month. No license key, no signup, no API token. (license)
The Nutrient document CLI
pdf-to-markdown is one verb of a single signed binary that turns digital-born PDFs into agent-ready output — locally, deterministically, on the same generous free tier. Convert once, then work against the result:
| Command | What it does | Reach for it when |
| --- | --- | --- |
| pdf-to-markdown | PDF → clean Markdown (headings, lists, tables, reading order) | The consumer benefits from structure — most RAG and LLM-context pipelines |
| pdf-to-text | PDF → layout-preserving plain text (columns and tabular alignment survive) | The consumer is plain-text only — a non-Markdown model, a grep/awk pipeline, a column-sensitive table reader |
| query | Ranked BM-25 search over an already-extracted file, returning only the top line windows | You have a large conversion and want one fact or clause without reading the whole thing back into context — parse once, query many |
All three install together from this package (and from the Nutrient Skills marketplace), and share one binary in ~/.local/share/nutrient/cli/.
Scanned or photographed documents? This CLI is built for digital-born PDFs (a real text layer). For scanned, handwritten, or otherwise image-only documents — and for schema-level structured extraction with per-value coordinates and confidence — use the Nutrient Data Extraction API.
Install
Agent skill (recommended)
If you use Claude Code, Codex, Pi, Cursor, or Gemini CLI, install the Nutrient Skills plugin — the extraction runs automatically when your agent needs to read a PDF. Add whichever of the three skills you want (they share one binary, so any of them installs it):
npx skills add pspdfkit-labs/nutrient-skills --skill pdf-to-markdown
npx skills add pspdfkit-labs/nutrient-skills --skill pdf-to-text
npx skills add pspdfkit-labs/nutrient-skills --skill queryOr with marketplace/plugin flows (Claude Code, Codex):
/plugin marketplace add pspdfkit-labs/nutrient-skills
/plugin install pdf-to-markdown@nutrient-skills
/plugin install pdf-to-text@nutrient-skills
/plugin install query@nutrient-skillsWith Pi:
pi install git:github.com/PSPDFKit-labs/nutrient-skillsOnce installed, just reference a PDF in your prompt — no extra commands needed:
"Extract the pricing table from proposal.pdf"
The skill invokes the CLI transparently and passes the resulting Markdown into your agent context.
Standalone CLI
For use outside an agent, install the published npm package:
npm install -g @pspdfkit/pdf-to-markdownOr run it without a global install:
npx @pspdfkit/pdf-to-markdown --helpThe package supports Node 18+ on macOS Apple Silicon, Linux x86_64, and Linux arm64.
If you prefer a shell installer, keep the curl fallback:
curl -fsSL https://raw.githubusercontent.com/PSPDFKit/pdf-to-markdown/main/install.sh | shThis installs pdf-to-markdown into ~/.local/bin by default.
You can also install from a clone:
git clone https://github.com/PSPDFKit/pdf-to-markdown.git
cd pdf-to-markdown
./install.sh # or: npm install -g .Quick Check
After install, verify the commands are available:
pdf-to-markdown --help
pdf-to-text --help
query --helpUsage
Single PDF
pdf-to-markdown input.pdf output.mdIf output.md is omitted, Markdown is written to stdout.
Batch directory
pdf-to-markdown ./input-pdfs ./output-markdownWhen both arguments are directories, the CLI converts every PDF in the input directory and writes matching Markdown files into the output directory.
Image export
pdf-to-markdown --enable-image-export input.pdf output.mdExtracts images from the PDF and saves them to output_resources/, referenced as standard Markdown image links in the output. Useful when feeding results to vision-capable LLMs or when image context improves downstream accuracy. Off by default because it increases processing time for image-heavy documents.
Plain text (pdf-to-text)
pdf-to-text input.pdf output.txtProduces layout-preserving plain text: each word is placed on a character grid that mirrors its position on the page, so columns, indentation, and tabular alignment survive the conversion. As with pdf-to-markdown, omit the output path to write to stdout, and pass two directories to batch-convert in parallel:
pdf-to-text input.pdf # write to stdout
pdf-to-text ./input-pdfs ./output-textChoosing pdf-to-markdown vs pdf-to-text
Both commands are backed by the same local binary; pick by what the downstream consumer needs:
- Use
pdf-to-markdownwhen the consumer benefits from semantic structure — headings, lists, tables, and reading order. Most RAG and LLM-context pipelines fall here. - Use
pdf-to-textwhen the consumer is plain-text only — a non-Markdown model, agrep/awkpipeline, or a column-aligned table reader that cares about spatial layout rather than Markdown markup.
Search a converted document (query)
A converted document can run to tens of thousands of lines and will blow out your context window if you read it back. query runs ranked BM-25 search over the extracted file and returns only the handful of line windows that matter — parse once, query many:
query text output.md "what is the total contract value?"Each result is a Lines A–B window with global line numbers, so you can re-read the exact range for full context. query is a two-level command — query text INPUT "QUERY" — leaving room for more query types over time.
Updates
The wrapper keeps the bundled binary current on its own: it checks the Nutrient CDN for a newer build at most once every six hours and updates in place. No manual update step is required. (The binary also ships a self-update capability, but you don't need to invoke it through these commands.)
Platform Support
- macOS Apple Silicon (
Darwin/arm64) - Linux x86_64
- Linux arm64
- Windows x64 (coming soon)
Benchmarks
Nutrient is built for digital-born PDF extraction, so we benchmark it against the open-source parsers you'd otherwise reach for.
Benchmark results from 200 PDF documents with hand-annotated Markdown ground truth, evaluated using NID (reading order), TEDS (table structure), and MHS (heading hierarchy) metrics. All competitor libraries pinned to their latest versions as of 2026-04-23.
Visual Snapshot
Accuracy
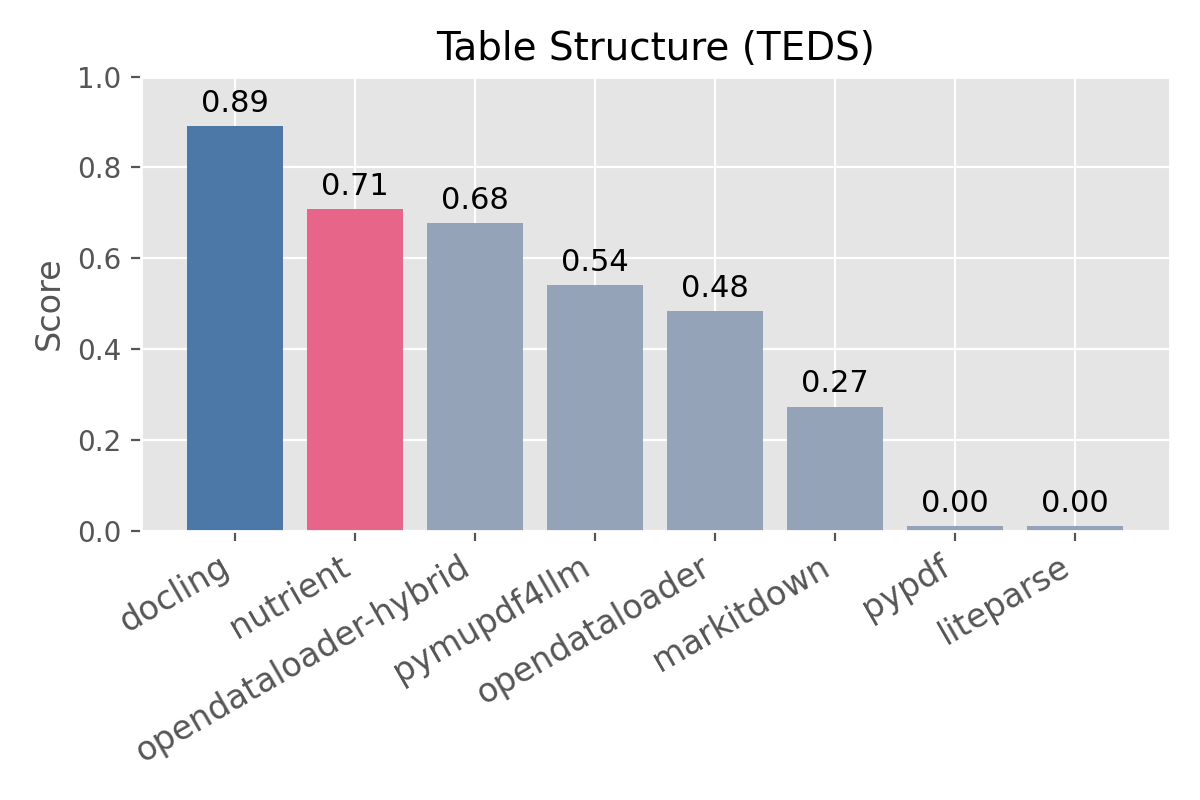
| Solution | Version | Overall | Reading Order (NID) | Table Structure (TEDS) | Heading Level (MHS) | | --- | --- | ---: | ---: | ---: | ---: | | Nutrient | 1.0.1 | 0.89 | 0.93 | 0.71 | 0.82 | | docling | 2.91.0 | 0.88 | 0.90 | 0.89 | 0.82 | | opendataloader-hybrid | 2.3.0 | 0.87 | 0.91 | 0.68 | 0.81 | | pymupdf4llm | 1.27.2 | 0.83 | 0.89 | 0.54 | 0.77 | | opendataloader | 2.3.0 | 0.83 | 0.90 | 0.48 | 0.74 | | markitdown | 0.1.5 | 0.59 | 0.84 | 0.27 | 0.00 | | pypdf | 6.10.2 | 0.58 | 0.87 | 0.00 | 0.00 | | liteparse | 1.2.1 | 0.57 | 0.86 | 0.00 | 0.00 |
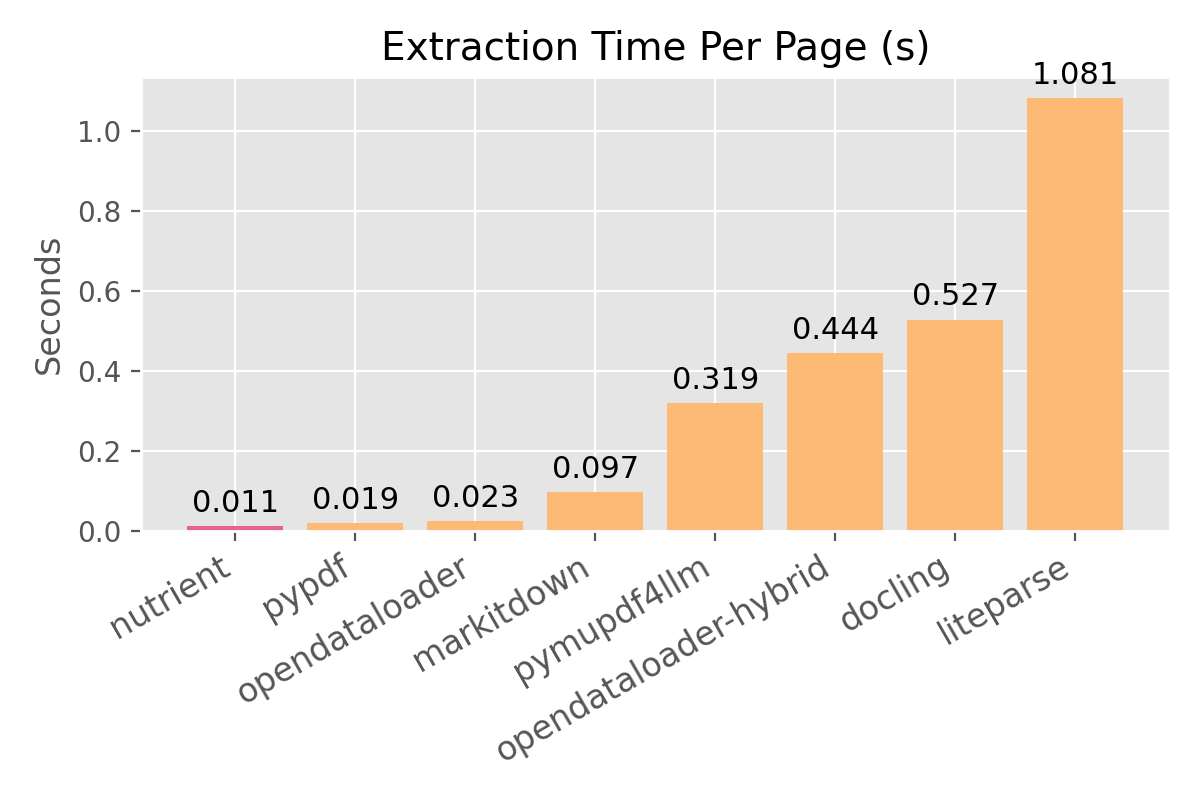
Speed
| Solution | Seconds per page | | --- | ---: | | Nutrient | 0.011 | | pypdf | 0.019 | | opendataloader | 0.023 | | markitdown | 0.097 | | pymupdf4llm | 0.319 | | opendataloader-hybrid | 0.444 | | docling | 0.527 | | liteparse | 1.081 |
Faster with Nutrient
98xfaster thanliteparse48xfaster thandocling40xfaster thanopendataloader-hybrid29xfaster thanpymupdf4llm9xfaster thanmarkitdown2xfaster thanopendataloader
For the full comparison table, see docs/benchmarks.md.
Trust and Licensing
- Free for up to
1,000documents per calendar month - PDFs stay local — your documents are not uploaded to Nutrient by this extractor
- A commercial license is required for processing more than
1,000documents per month - The extraction engine is delivered as a signed platform binary; the repo contains only the wrapper and documentation
- The license is non-transferable — you may not redistribute the binary standalone or sublicense it to third parties; embedding it in your own application is permitted under the free tier terms
See LICENSE.md for the full terms and docs/distribution-model.md for details on what ships in this repo vs. the binary.
FAQ
What makes this different from other PDF extractors?
Speed and accuracy should not be a tradeoff. Most extractors are either fast but lose structure (markitdown, pymupdf4llm) or accurate but slow (docling). Nutrient extracts at 0.011s per page with the best reading order score (0.93), strong heading and table preservation — less cleanup, fewer wasted tokens, and more reliable downstream results.
What about scanned or handwritten documents?
This CLI is built for digital-born PDFs that already contain a text layer. It does not OCR. For scanned, photographed, or handwritten documents — and for schema-level structured extraction with per-value coordinates and confidence scores — use the Nutrient Data Extraction API, which is designed for exactly that.
Do my documents leave my machine?
No. The CLI processes PDFs locally. Nothing is uploaded to Nutrient. Note that if you feed the extracted Markdown into Claude, Codex, or another model provider, their own data policies apply.
Do I need a license key or API token?
No. There is no signup, no license key, and no API token. Install the CLI and start converting. The free tier (up to 1,000 documents per calendar month) is enforced via the license terms, not a technical gate. If you need to process more than 1,000 documents per month, contact [email protected] for a commercial license.
Why is the extraction engine closed-source?
The repo is designed to be reviewable — you can read the wrapper, the installer, and the documentation. The extraction engine is distributed as a signed binary to protect the implementation while keeping the CLI surface fully transparent.