
@scrapeops/n8n-nodes-scrapeops
v0.2.7
Published
n8n community node for ScrapeOps Proxy, Parser, and Data APIs for web scraping and data extraction



Readme
ScrapeOps n8n Community Node
![]()
![]()
The ScrapeOps n8n node is a powerful integration that brings ScrapeOps' web scraping capabilities directly into your n8n workflows. This node allows you to leverage ScrapeOps' proxy aggregation, HTML parsing, and structured data extraction services without writing complex code.
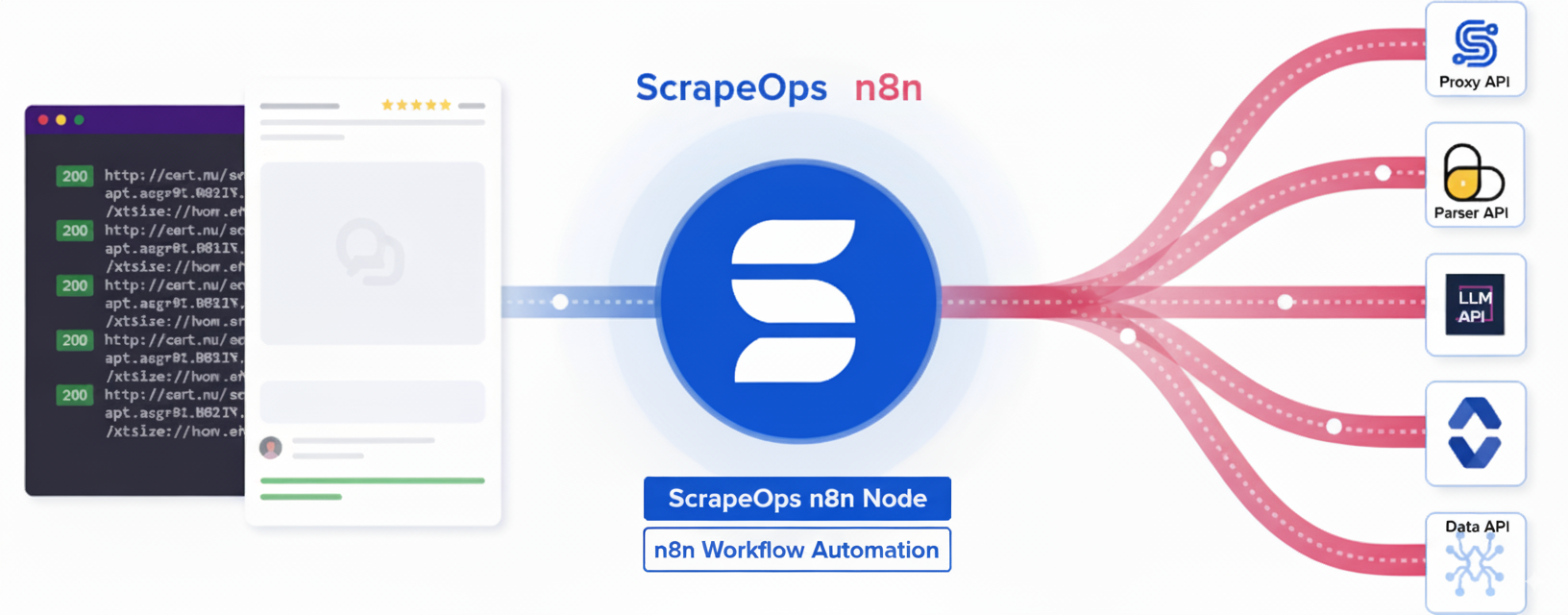
What is ScrapeOps?
ScrapeOps provides a suite of tools to simplify web scraping operations:
- 🔀 Proxy API: Access high-quality proxies through a single endpoint for reliable web scraping
- 📊 Parser API: Extract structured data from HTML content of popular websites
- 💾 Data API: Retrieve and query data from ScrapeOps datasets
✨ Key Features
🔀 Proxy API
- Smart proxy rotation across multiple providers
- JavaScript rendering support for dynamic sites
- Anti-bot bypass capabilities (Cloudflare, DataDome, etc.)
- Geo-targeting options
- Mobile and residential proxy support
- Session management for multi-step scraping
📊 Parser API
- Extract structured data from popular websites without maintaining your own parsers
- Supported Sites: Amazon, eBay, Walmart, Indeed, Redfin
- Page Types: Product pages, search results, reviews, categories
- Returns clean, structured JSON data
💾 Data API
- Direct access to structured data endpoints
- Amazon Product API: Get product details by ASIN or URL
- Amazon Search API: Search products and get structured results
- No HTML scraping required - get data in a single request
📦 Installation
Method 1: Install via n8n Cloud UI (Recommended)
If you're using n8n Cloud, you can easily install the ScrapeOps node directly from the UI:
- Sign in to n8n, open the editor, and click + in the top right to open the Nodes panel
- Search for "ScrapeOps" node using the search bar. Look for the version marked by a badge ☑. Then, select install.
- The ScrapeOps node will be installed and appear in your node palette automatically.
Method 2: Install via n8n Settings (Self-Hosted)
For self-hosted n8n instances:
- Open your n8n instance
- Navigate to Settings → Community Nodes
- Click Install a community node
- Enter the package name:
@scrapeops/n8n-nodes-scrapeops - Click Install
- Restart your n8n instance when prompted
Method 3: Manual Installation (Self-Hosted)
# Navigate to your n8n installation directory
cd ~/.n8n
# Install the ScrapeOps node
npm install @scrapeops/n8n-nodes-scrapeops
# Restart n8n
n8n startMethod 4: Docker Installation
For Docker users, add the node to your docker-compose.yml:
version: '3.8'
services:
n8n:
image: n8nio/n8n
environment:
- N8N_COMMUNITY_NODES_ENABLED=true
- NODE_FUNCTION_ALLOW_EXTERNAL=n8n-nodes-scrapeops
volumes:
- ~/.n8n:/home/node/.n8nThen install the node:
docker exec -it <container_name> npm install @scrapeops/n8n-nodes-scrapeops
docker restart <container_name>🔑 Authentication
Getting Your ScrapeOps API Key
To use the ScrapeOps node, you'll need a ScrapeOps API key which you can get by signing up for a free account here.
Steps to get your API key:
- Sign up for a free account at ScrapeOps
- Verify your email address (required to activate your API key)
- Visit your dashboard at ScrapeOps Dashboard
- Copy your API key from the dashboard

⚠️ Important: You must confirm your email address to activate your API key. Check your inbox for a verification email from ScrapeOps.
Configure Credentials in n8n
- In n8n, go to Credentials → Add Credential.
- Search for "ScrapeOps API" and enter your API key.
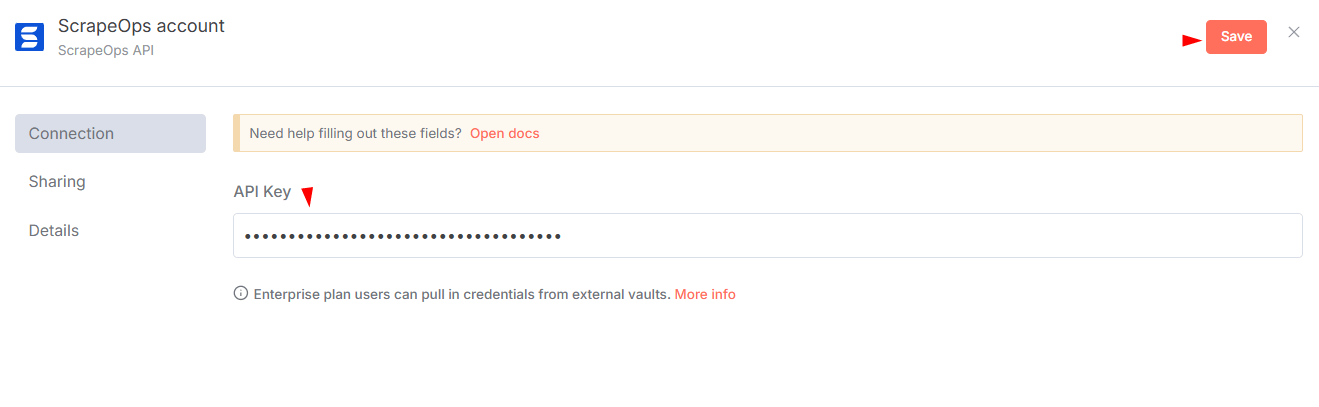
- Save and test the credentials.
🎯 Quick Start
Adding the Node to a Workflow
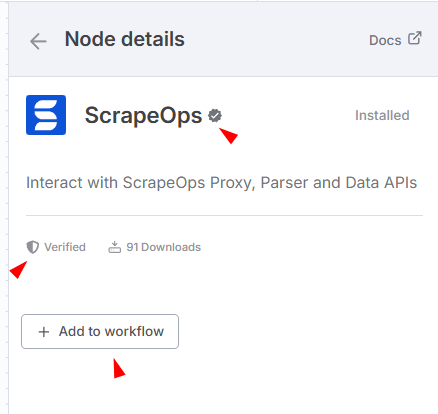
- Create a new workflow in n8n.
- Click Add to Workflow "ScrapeOps" node from the palette.
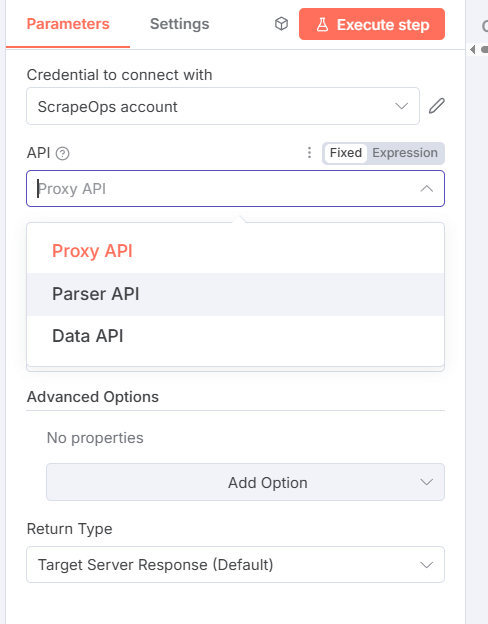
- Select an API (Proxy, Parser, or Data) and configure parameters.
You can monitor your usage in the ScrapeOps Dashboard.
📚 API Documentation
🔀 Proxy API
Route GET/POST requests through proxies to scrape blocked sites.
Basic Parameters:
- URL: Target URL to scrape (required)
- Method: GET or POST (default: GET)
- Return Type: Default (raw response) or JSON
Advanced Options:
| Option | Type | Description | Default | Example Values |
|--------|------|-------------|---------|----------------|
| Follow Redirects | Boolean | Follow HTTP redirects | true | true, false |
| Keep Headers | Boolean | Use your custom headers | false | true, false |
| Initial Status Code | Boolean | Return initial status code | false | true, false |
| Final Status Code | Boolean | Return final status code | false | true, false |
| Optimize Request | Boolean | Auto-optimize settings | false | true, false |
| Max Request Cost | Number | Max credits to use (with optimize) | 0 | 10, 50, 100 |
| Render JavaScript | Boolean | Enable headless browser | false | true, false |
| Wait Time | Number | Wait before capture (ms) | 0 | 3000, 5000 |
| Wait For | String | CSS selector to wait for | - | .product-title, #content |
| Scroll | Number | Scroll pixels before capture | 0 | 1000, 2000 |
| Screenshot | Boolean | Return base64 screenshot | false | true, false |
| Device Type | String | Device emulation | desktop | desktop, mobile |
| Premium Proxies | String | Premium level | level_1 | level_1, level_2 |
| Residential Proxies | Boolean | Use residential IPs | false | true, false |
| Mobile Proxies | Boolean | Use mobile IPs | false | true, false |
| Session Number | Number | Sticky session ID | 0 | 12345, 67890 |
| Country | String | Geo-targeting country | - | us, gb, de, fr, ca, au, jp, in |
| Bypass | String | Anti-bot bypass level | - | cloudflare_level_1, cloudflare_level_2, cloudflare_level_3, datadome, perimeterx, incapsula, generic_level_1 to generic_level_4 |
Example Configuration:
API Type: Proxy API
URL: https://example.com
Method: GET
Render JavaScript: true
Wait Time: 3000
Country: us📊 Parser API
Parse HTML into structured JSON for supported domains.
Parameters:
- Domain: Amazon, eBay, Walmart, Indeed, Redfin
- URL: Page URL (required)
- HTML Content: Raw HTML to parse (required)
Example Configuration:
API Type: Parser API
Domain: Amazon
URL: https://www.amazon.com/dp/B08N5WRWNW
HTML Content: {{ $node["Proxy_API"].json.body }}💾 Data API
Tap into pre-scraped datasets for commerce, jobs, and real estate without maintaining your own crawlers or parsers.
Workflow basics
- Domain: Choose
Amazon,eBay,Walmart,Indeed, orRedfin. - API Type: Select the dataset endpoint that matches the data you need (product, search, reviews, etc.).
- Input Type: Decide whether you want to identify the record via ID, query, or URL.
- Advanced Options: Provide localization parameters (
country,tld) when available to scope the dataset to a specific market.
1. Amazon Product Data (Using URL)
Domain: Amazon
API Type: Product API
Input Type: URL
Product URL: https://www.amazon.com/dp/B08N5WRWNW2. Walmart Search Results (Using Query)
Domain: Walmart
API Type: Search API
Input Type: Query
Search Query: laptop
Advanced Options: Country = usSupported Domains:
- Amazon: Product, Search
- eBay: Product, Search, Feedback, Category, Store
- Walmart: Product, Search, Review, Shop, Browse, Category
- Indeed: Job Search, Job Detail, Company Search/Reviews/Jobs
- Redfin: Sale/Rent Search, Detail, Building, Agent, State
🎯 Common Use Cases
1. Price Monitoring
- Track product prices across multiple e-commerce sites
- Set up alerts for price drops
- Generate competitive pricing reports
2. Market Research
- Collect product reviews and ratings
- Monitor competitor inventory
- Track market trends
3. Lead Generation
- Extract business information from directories
- Collect job postings from career sites
- Find real estate listings
4. Content Aggregation
- Collect news articles
- Monitor social media mentions
- Aggregate product descriptions
🛠️ Best Practices
1. Start Simple
Begin with basic requests and add complexity:
1. Basic GET request
2. Add JavaScript rendering if needed
3. Add wait conditions
4. Enable anti-bot bypass if blocked2. Optimize for Cost
- Use
optimize_request: truefor automatic optimization - Set
max_request_costto control spending - Only enable features you need
3. Handle Dynamic Content
For JavaScript-heavy sites:
Render JavaScript: true
Wait Time: 3000
Wait For: .main-content
Scroll: 10004. Session Management
For multi-step scraping:
Session Number: 12345
// Use same number across requests🐛 Troubleshooting
Node Not Appearing
Problem: ScrapeOps node doesn't show up after installation
Solution:
- Ensure n8n was restarted after installation
- Check that community nodes are enabled
- Verify the installation with:
npm list @scrapeops/n8n-nodes-scrapeops
Authentication Failures
Problem: "Invalid API Key" error
Solution:
- Verify API key is copied correctly (no extra spaces)
- Check if API key is active in ScrapeOps dashboard
- Ensure you're using the correct credential in the node
Connection Timeouts
Problem: Requests timing out
Solution:
- Check your firewall settings
- Verify n8n can make external HTTP requests
- Test with a simple URL first (like httpbin.org)
📖 Resources
- ScrapeOps Documentation - Complete API documentation
- ScrapeOps n8n Node Documentation - Complete ScrapeOps n8n Node documentation
- n8n Community Nodes Documentation - n8n integration guide
- ScrapeOps Dashboard - Monitor usage and performance
- n8n Community Forum - Get help from the community
🤝 Support
- ScrapeOps Support: [email protected]
- n8n Community Forum: community.n8n.io
- GitHub Issues: Report bugs or request features
📄 License
Ready to automate your web scraping? Get started with the ScrapeOps n8n integration today!