
@tensorflow-models/universal-sentence-encoder
v1.3.3
Published
Universal Sentence Encoder lite in TensorFlow.js
Maintainers
 delhibabu
delhibabu laxma4675
laxma4675 fengwuyao
fengwuyao linchan
linchan pyu10055
pyu10055 caisq
caisq annxingyuan
annxingyuan linazhao128
linazhao128 mattsoulanille
mattsoulanille jinjingforever
jinjingforeverKeywords
Readme
Universal Sentence Encoder lite
The Universal Sentence Encoder (Cer et al., 2018) (USE) is a model that encodes text into 512-dimensional embeddings. These embeddings can then be used as inputs to natural language processing tasks such as sentiment classification and textual similarity analysis.
This module is a TensorFlow.js GraphModel converted from the USE lite (module on TFHub), a lightweight version of the original. The lite model is based on the Transformer (Vaswani et al, 2017) architecture, and uses an 8k word piece vocabulary.
In this demo we embed six sentences with the USE, and render their self-similarity scores in a matrix (redder means more similar):
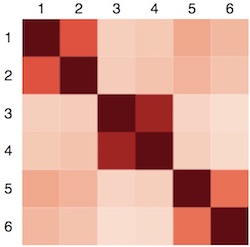
The matrix shows that USE embeddings can be used to cluster sentences by similarity.
The sentences (taken from the TensorFlow Hub USE lite colab):
- I like my phone.
- Your cellphone looks great.
- How old are you?
- What is your age?
- An apple a day, keeps the doctors away.
- Eating strawberries is healthy.
Universal Sentence Encoder For Question Answering
The Universal Sentence Encoder for question answering (USE QnA) is a model that encodes question and answer texts into 100-dimensional embeddings. The dot product of these embeddings measures how well the answer fits the question. It can also be used in other applications, including any type of text classification, clustering, etc.
This module is a lightweight TensorFlow.js GraphModel. The model is based on the Transformer (Vaswani et al, 2017) architecture, and uses an 8k SentencePiece vocabulary. It is trained on a variety of data sources, with the goal of learning text representations that are useful out-of-the-box to retrieve an answer given a question.
In this demo we embed a question and three answers with the USE QnA, and render their their scores:

The scores show how well each answer fits the question.
Installation
Using yarn:
$ yarn add @tensorflow/tfjs @tensorflow-models/universal-sentence-encoderUsing npm:
$ npm install @tensorflow/tfjs @tensorflow-models/universal-sentence-encoderUsage
To import in npm:
require('@tensorflow/tfjs');
const use = require('@tensorflow-models/universal-sentence-encoder');or as a standalone script tag:
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/universal-sentence-encoder"></script>Then:
// Load the model.
use.load().then(model => {
// Embed an array of sentences.
const sentences = [
'Hello.',
'How are you?'
];
model.embed(sentences).then(embeddings => {
// `embeddings` is a 2D tensor consisting of the 512-dimensional embeddings for each sentence.
// So in this example `embeddings` has the shape [2, 512].
embeddings.print(true /* verbose */);
});
});load() accepts an optional configuration object where you can set custom modelUrl and/or vocabUrl strings (e.g. use.load({modelUrl: '', vocabUrl: ''})).
To use the Tokenizer separately:
use.loadTokenizer().then(tokenizer => {
tokenizer.encode('Hello, how are you?'); // [341, 4125, 8, 140, 31, 19, 54]
});To use the QnA dual encoder:
// Load the model.
use.loadQnA().then(model => {
// Embed a dictionary of a query and responses. The input to the embed method
// needs to be in following format:
// {
// queries: string[];
// responses: Response[];
// }
// queries is an array of question strings
// responses is an array of following structure:
// {
// response: string;
// context?: string;
// }
// context is optional, it provides the context string of the answer.
const input = {
queries: ['How are you feeling today?', 'What is captial of China?'],
responses: [
'I\'m not feeling very well.',
'Beijing is the capital of China.',
'You have five fingers on your hand.'
]
};
var scores = [];
const embeddings = model.embed(input);
/*
* The output of the embed method is an object with two keys:
* {
* queryEmbedding: tf.Tensor;
* responseEmbedding: tf.Tensor;
* }
* queryEmbedding is a tensor containing embeddings for all queries.
* responseEmbedding is a tensor containing embeddings for all answers.
* You can call `arraySync()` to retrieve the values of the tensor.
* In this example, embed_query[0] is the embedding for the query
* 'How are you feeling today?'
* And embed_responses[0] is the embedding for the answer
* 'I\'m not feeling very well.'
*/
const embed_query = embeddings['queryEmbedding'].arraySync();
const embed_responses = embeddings['responseEmbedding'].arraySync();
// compute the dotProduct of each query and response pair.
for (let i = 0; i < input['queries'].length; i++) {
for (let j = 0; j < input['responses'].length; j++) {
scores.push(dotProduct(embed_query[i], embed_responses[j]));
}
}
});
// Calculate the dot product of two vector arrays.
const dotProduct = (xs, ys) => {
const sum = xs => xs ? xs.reduce((a, b) => a + b, 0) : undefined;
return xs.length === ys.length ?
sum(zipWith((a, b) => a * b, xs, ys))
: undefined;
}
// zipWith :: (a -> b -> c) -> [a] -> [b] -> [c]
const zipWith =
(f, xs, ys) => {
const ny = ys.length;
return (xs.length <= ny ? xs : xs.slice(0, ny))
.map((x, i) => f(x, ys[i]));
}