
ai-recall
v0.1.0
Published
Find any AI coding session you've ever had. Across Claude Code, Cursor, Codex CLI, and Gemini.
Maintainers
 skibidiskib
skibidiskibReadme
ai-recall
Find any AI coding session you've ever had. Across Claude Code, Cursor, Codex CLI, and Gemini.
npm i -g ai-recall · github.com/skibidiskib/ai-recall
The pain
Yesterday you spent two hours teaching an AI to fix a tricky migration. Today you need that chat back.
claude --resume gives you a list of timestamps. Cursor's history is buried inside the editor. Codex CLI is separate again. Gemini is separate again. None of them share memory. Your AI conversations are scattered across four tools and you can't find a thing.
What it is
A daily-refreshed index of every AI coding session on your laptop, with search that ranks by topic depth — not just substring matches. Type ai-recall ai-codex and you get the chats that were actually about ai-codex, newest first. Hit enter — it resumes in the right tool, in the right project directory.
No daemon. No telemetry. No cloud. One JSON file on your disk.
The 5-second demo
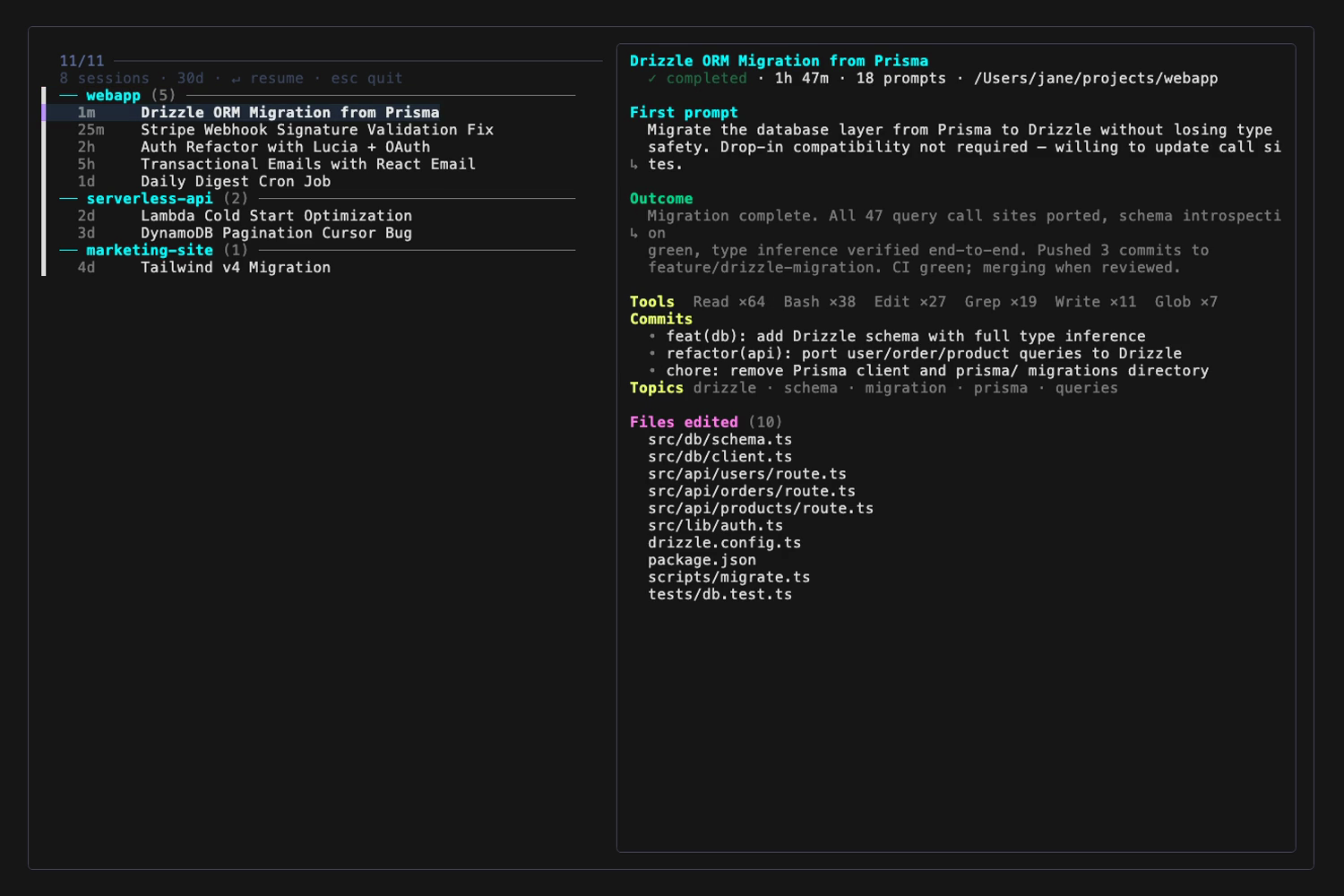

$ ai-recall
── webapp (5) ───────────────────────────────────────
1m Drizzle ORM Migration from Prisma
25m Stripe Webhook Signature Validation Fix
2h Auth Refactor with Lucia + OAuth
5h Transactional Emails with React Email
1d Daily Digest Cron Job
── serverless-api (2) ───────────────────────────────
2d Lambda Cold Start Optimization
3d DynamoDB Pagination Cursor Bug
── marketing-site (1) ───────────────────────────────
4d Tailwind v4 Migration
┌──────────────────────────────────────────────────────┐
│ Drizzle ORM Migration from Prisma │
│ ✓ completed · 1h 47m · 18 prompts · ~/webapp │
│ │
│ First prompt │
│ Migrate the database layer from Prisma to Drizzle │
│ without losing type safety. Drop-in compatibility │
│ not required — willing to update call sites. │
│ │
│ Outcome │
│ Migration complete. All 47 query call sites │
│ ported, schema introspection green, type inference │
│ verified end-to-end. Pushed 3 commits... │
│ │
│ Tools Read ×64 Bash ×38 Edit ×27 Grep ×19 │
│ Commits │
│ • feat(db): add Drizzle schema with full inference │
│ • refactor(api): port queries to Drizzle │
│ • chore: remove Prisma client + migrations dir │
│ Topics drizzle · schema · migration · prisma │
│ │
│ Files edited (10) │
│ src/db/schema.ts │
│ src/db/client.ts │
│ src/api/users/route.ts │
│ ...and 7 more │
└──────────────────────────────────────────────────────┘Every row is an AI-generated title (one Haiku call per session at index time, ~$0.0002 each — not the first 70 chars of "propose improvements to ai-codex..."). The preview pane reconstructs the session at a glance: what shipped (commits parsed from git commit -m calls in your Bash history), how much work it was (tool counts), how it ended (the last substantive assistant turn — not the trailing "OK!"), and which files moved.
Why it's different
| | claude-history | JSONL viewers | ccusage | ai-recall | |---|---|---|---|---| | Multi-tool (Claude / Cursor / Codex / Gemini) | no | no | partial | yes | | AI-generated titles (not raw first prompt) | no | no | n/a | yes | | "Substantially about" topic filter, then by date | no | no | n/a | yes | | Rolling 30-day window + daily rebuild | no | no | n/a | yes | | Resume in correct cwd | yes | no | n/a | yes | | Extracted decisions / file edits / TODOs | no | no | no | v0.3 |
The three things in bold-yes are the product moments. Everything else is table stakes.
How it works
- A
launchd(macOS) /cron(Linux) job runs daily and walks~/.claude/projects/,~/.cursor/projects/,~/.codex/sessions/,~/.gemini/tmp/for sessions touched in the rolling window (default 30d). - For each session, it extracts: first/last user prompt, files edited (from
Edit/Write/MultiEdittool calls), per-term frequency, and a one-line AI title. - Output: a single
~/.ai-recall/index.json(~1 MB for 100 sessions). - The picker is an
fzf-style TUI that runs BM25 over the index, applies a "topic depth" floor, and re-sorts the survivors by recency.
Search ranking, in detail:
- BM25 over each session-as-document gives you term-frequency × inverse-document-frequency for free. A session with 223 mentions of
codex-clioutranks one with 1. - A relevance floor drops anything below a threshold, so passing mentions don't pollute the list.
- Survivors are re-sorted by recency, matching how memory actually works ("most recent chat about X, then the next one").
- Matches in user prompts and edited file paths weight higher than matches in long assistant replies.
Install
npm i -g ai-recall
ai-recall init # builds initial index, registers daily refresh
ai-recall # opens the picker
ai-recall <query> # picker pre-filtered by topic
ai-recall --all # ignore the rolling window (slow ripgrep)Zero new auth. AI titles use your locally-installed claude CLI — it shells out to claude --print for each session, so no Anthropic API key is required. Fallback chain: claude CLI → ANTHROPIC_API_KEY env var → Ollama (if installed) → raw first-prompt.
Picker requires fzf (brew install fzf / apt install fzf). If missing, falls back to a numbered list.
Roadmap
- v0.1 — Claude Code only. BM25 + AI titles + daily refresh + resume in correct cwd. Ship this in a weekend.
- v0.2 — Cursor + Codex CLI + Gemini transcript ingestion. Same index format, four sources.
- v0.3 — Knowledge layer: decisions, file edits, and open TODOs extracted into a queryable second index. Now
ai-recallanswers "what did I decide about X?" not just "where was the chat?" - v0.4 — Auto-context: when you start a new session, surface the 1–3 most relevant past sessions and offer to inject their summaries into the opening prompt.
Why this could break out
ccusage hit 13.3k stars by answering one universal question ("how much am I spending?") with instant payoff. ai-recall answers another universal question that nobody currently answers well: "where was the thing I figured out last Tuesday?"
The pain is daily and getting worse — every AI tool you add multiplies it. The viral demo is a 15-second gif: type a topic, watch AI-titled rows land in 30ms, hit enter, you're back in the right session in the right tool. That's the moment.
The thing that prevents virality is positioning it as "better claude-resume." Positioned as "unified memory across every AI coding tool you use", it's a different product with a much bigger ceiling.
Decisions locked
- Name —
ai-recall. npm +github.com/skibidiskib/ai-recallslots claimed. - Title backend — Default to local
claude --print(no new auth, uses subscription). Fallback chain:ANTHROPIC_API_KEYenv var → Ollama (llama-3.2:3b) → raw first-prompt. - Picker —
fzfshell-out for v0.1,--no-fzfnumbered-list fallback if missing. Custom TUI (Ink) deferred to v0.3. - Launch — Coordinated event, not a series of posts. X demo gif (hero) + blog post (anchor) + Show HN + Discord/Reddit, all within 30 min on Tue/Wed at 9 AM ET. Pre-launch DMs to @simonw, @ryoppippi, @alexalbert__ as a courtesy heads-up.
Launch checklist
- [ ] v0.1 implementation finished + tested on a real account
- [ ]
npm publishunderai-recall - [ ]
gh repo create skibidiskib/ai-recall --public, push code - [ ] 15-second demo gif (asciinema → terminalizer): the search-then-resume moment, no install footage
- [ ] Blog post draft: technical deep-dive on BM25, topic-floor search, the
claude --printtrick - [ ] Pre-launch DMs (T-2 days, no ask, just share)
- [ ] Show HN post drafted: "Show HN: ai-recall – fzf-style search across all your AI coding sessions"
- [ ] r/ClaudeAI + r/LocalLLaMA + r/cursor posts drafted (native, not link-only)
- [ ] Anthropic + Cursor Discord posts drafted
- [ ] X post scheduled for Tue/Wed 9 AM ET, gif as hero, blog link in reply