cdk-databrew-cicd
v2.0.636
Published
A construct for AWS Glue DataBrew wtih CICD
Maintainers
 scott.hsieh
scott.hsiehReadme
cdk-databrew-cicd
This construct creates a CodePipeline pipeline where users can push a DataBrew recipe into the CodeCommit repository and the recipe will be pushed to a pre-production AWS account and a production AWS account by order automatically.
| npm (JS/TS) | PyPI (Python) | Maven (Java) | Go | NuGet | | --- | --- | --- | --- | --- | | Link | Link | Link | Link | Link |
![]()




Table of Contents
- Serverless Architecture
- Introduction
- Example
- Some Efforts after Stack Creation
- How Successful Commits Look Like
Serverless Architecture
 Romi B. and Gaurav W., 2021
Romi B. and Gaurav W., 2021
Introduction
The architecture was introduced by Romi Boimer and Gaurav Wadhawan and was posted on the AWS Blog as Set up CI/CD pipelines for AWS Glue DataBrew using AWS Developer Tools.
I converted the architecture into a CDK construct for 5 programming languages. Before applying the AWS construct, make sure you've set up a proper IAM role for the pre-production and production AWS accounts. You could achieve it either by creating manually or creating through a custom construct in this library.
import { IamRole } from 'cdk-databrew-cicd';
new IamRole(this, 'AccountIamRole', {
environment: 'preproduction', // or 'production'
accountID: 'ACCOUNT_ID',
// roleName: 'OPTIONAL'
});Example
Typescript
You could also refer to here.
$ cdk --init language typescript
$ yarn add cdk-databrew-cicdimport * as cdk from '@aws-cdk/core';
import { DataBrewCodePipeline } from 'cdk-databrew-cicd';
class TypescriptStack extends cdk.Stack {
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const preproductionAccountId = 'PREPRODUCTION_ACCOUNT_ID';
const productionAccountId = 'PRODUCTION_ACCOUNT_ID';
const dataBrewPipeline = new DataBrewCodePipeline(this, 'DataBrewCicdPipeline', {
preproductionIamRoleArn: `arn:${cdk.Aws.PARTITION}:iam::${preproductionAccountId}:role/preproduction-Databrew-Cicd-Role`,
productionIamRoleArn: `arn:${cdk.Aws.PARTITION}:iam::${productionAccountId}:role/production-Databrew-Cicd-Role`,
// bucketName: 'OPTIONAL',
// repoName: 'OPTIONAL',
// branchName: 'OPTIONAL',
// pipelineName: 'OPTIONAL'
});
new cdk.CfnOutput(this, 'OPreproductionLambdaArn', { value: dataBrewPipeline.preproductionFunctionArn });
new cdk.CfnOutput(this, 'OProductionLambdaArn', { value: dataBrewPipeline.productionFunctionArn });
new cdk.CfnOutput(this, 'OCodeCommitRepoArn', { value: dataBrewPipeline.codeCommitRepoArn });
new cdk.CfnOutput(this, 'OCodePipelineArn', { value: dataBrewPipeline.codePipelineArn });
}
}
const app = new cdk.App();
new TypescriptStack(app, 'TypescriptStack', {
stackName: 'DataBrew-CICD'
});Python
You could also refer to here.
# upgrading related Python packages
$ python -m ensurepip --upgrade
$ python -m pip install --upgrade pip
$ python -m pip install --upgrade virtualenv
# initialize a CDK Python project
$ cdk init --language python
# make packages installed locally instead of globally
$ source .venv/bin/activate
$ cat <<EOL > requirements.txt
aws-cdk.core
cdk-databrew-cicd
EOL
$ python -m pip install -r requirements.txtfrom aws_cdk import core as cdk
from cdk_databrew_cicd import DataBrewCodePipeline
class PythonStack(cdk.Stack):
def __init__(self, scope: cdk.Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
preproduction_account_id = "PREPRODUCTION_ACCOUNT_ID"
production_account_id = "PRODUCTION_ACCOUNT_ID"
databrew_pipeline = DataBrewCodePipeline(self,
"DataBrewCicdPipeline",
preproduction_iam_role_arn=f"arn:{cdk.Aws.PARTITION}:iam::{preproduction_account_id}:role/preproduction-Databrew-Cicd-Role",
production_iam_role_arn=f"arn:{cdk.Aws.PARTITION}:iam::{production_account_id}:role/preproduction-Databrew-Cicd-Role",
# bucket_name="OPTIONAL",
# repo_name="OPTIONAL",
# repo_name="OPTIONAL",
# branch_namne="OPTIONAL",
# pipeline_name="OPTIONAL"
)
cdk.CfnOutput(self, 'OPreproductionLambdaArn', value=databrew_pipeline.preproduction_function_arn)
cdk.CfnOutput(self, 'OProductionLambdaArn', value=databrew_pipeline.production_function_arn)
cdk.CfnOutput(self, 'OCodeCommitRepoArn', value=databrew_pipeline.code_commit_repo_arn)
cdk.CfnOutput(self, 'OCodePipelineArn', value=databrew_pipeline.code_pipeline_arn)$ deactivateJava
You could also refer to here.
$ cdk init --language java
$ mvn package.
.
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<cdk.version>2.87.0</cdk.version>
<constrcut.verion>2.0.196</constrcut.verion>
<junit.version>5.7.1</junit.version>
</properties>
.
.
<dependencies>
<!-- AWS Cloud Development Kit -->
<dependency>
<groupId>software.amazon.awscdk</groupId>
<artifactId>aws-cdk-lib</artifactId>
<version>${cdk.version}</version>
</dependency>
<dependency>
<groupId>io.github.hsiehshujeng</groupId>
<artifactId>cdk-databrew-cicd</artifactId>
<version>${constrcut.verion}</version>
</dependency>
.
.
.
</dependencies>package com.myorg;
import software.amazon.awscdk.core.CfnOutput;
import software.amazon.awscdk.core.CfnOutputProps;
import software.amazon.awscdk.core.Construct;
import software.amazon.awscdk.core.Stack;
import software.amazon.awscdk.core.StackProps;
import io.github.hsiehshujeng.cdk.databrew.cicd.DataBrewCodePipeline;
import io.github.hsiehshujeng.cdk.databrew.cicd.DataBrewCodePipelineProps;
public class JavaStack extends Stack {
public JavaStack(final Construct scope, final String id) {
this(scope, id, null);
}
public JavaStack(final Construct scope, final String id, final StackProps props) {
super(scope, id, props);
String preproductionAccountId = "PREPRODUCTION_ACCOUNT_ID";
String productionAccountId = "PRODUCTION_ACCOUNT_ID";
DataBrewCodePipeline databrewPipeline = new DataBrewCodePipeline(this, "DataBrewCicdPipeline",
DataBrewCodePipelineProps.builder().preproductionIamRoleArn(preproductionAccountId)
.productionIamRoleArn(productionAccountId)
// .bucketName("OPTIONAL")
// .branchName("OPTIONAL")
// .pipelineName("OPTIONAL")
.build());
new CfnOutput(this, "OPreproductionLambdaArn",
CfnOutputProps.builder()
.value(databrewPipeline.getPreproductionFunctionArn())
.build());
new CfnOutput(this, "OProductionLambdaArn",
CfnOutputProps.builder()
.value(databrewPipeline.getProductionFunctionArn())
.build());
new CfnOutput(this, "OCodeCommitRepoArn",
CfnOutputProps.builder()
.value(databrewPipeline.getCodeCommitRepoArn())
.build());
new CfnOutput(this, "OCodePipelineArn",
CfnOutputProps.builder()
.value(databrewPipeline.getCodePipelineArn())
.build());
}
}C#
You could also refer to here.
$ cdk init --language csharp
$ dotnet add src/Csharp package Databrew.Cicd --version 2.0.196using Amazon.CDK;
using ScottHsieh.Cdk;
namespace Csharp
{
public class CsharpStack : Stack
{
internal CsharpStack(Construct scope, string id, IStackProps props = null) : base(scope, id, props)
{
var preproductionAccountId = "PREPRODUCTION_ACCOUNT_ID";
var productionAccountId = "PRODUCTION_ACCOUNT_ID";
var dataBrewPipeline = new DataBrewCodePipeline(this, "DataBrewCicdPipeline", new DataBrewCodePipelineProps
{
PreproductionIamRoleArn = $"arn:{Aws.PARTITION}:iam::{preproductionAccountId}:role/preproduction-Databrew-Cicd-Role",
ProductionIamRoleArn = $"arn:{Aws.PARTITION}:iam::{productionAccountId}:role/preproduction-Databrew-Cicd-Role",
// BucketName = "OPTIONAL",
// RepoName = "OPTIONAL",
// BranchName = "OPTIONAL",
// PipelineName = "OPTIONAL"
});
new CfnOutput(this, "OPreproductionLambdaArn", new CfnOutputProps
{
Value = dataBrewPipeline.PreproductionFunctionArn
});
new CfnOutput(this, "OProductionLambdaArn", new CfnOutputProps
{
Value = dataBrewPipeline.ProductionFunctionArn
});
new CfnOutput(this, "OCodeCommitRepoArn", new CfnOutputProps
{
Value = dataBrewPipeline.CodeCommitRepoArn
});
new CfnOutput(this, "OCodePipelineArn", new CfnOutputProps
{
Value = dataBrewPipeline.CodeCommitRepoArn
});
}
}
}Go
You could also refer to here.
# Initialize a new AWS CDK application in the current directory with the Go programming language
cdk init app -l go
# Add this custom CDK construct to your project
go get github.com/HsiehShuJeng/cdk-databrew-cicd-go/cdkdatabrewcicd/[email protected]
# Ensure all dependencies are properly listed in the go.mod file and remove any unused ones
go mod tidy
# Upgrade all Go modules in your project to their latest minor or patch versions
go get -u ./...package main
import (
"fmt"
"github.com/aws/aws-cdk-go/awscdk/v2"
// "github.com/aws/aws-cdk-go/awscdk/v2/awssqs"
"github.com/HsiehShuJeng/cdk-databrew-cicd-go/cdkdatabrewcicd/v2"
"github.com/aws/constructs-go/constructs/v10"
"github.com/aws/jsii-runtime-go"
)
type GoLangStackProps struct {
awscdk.StackProps
}
func NewGoLangStack(scope constructs.Construct, id string, props *GoLangStackProps) awscdk.Stack {
var sprops awscdk.StackProps
if props != nil {
sprops = props.StackProps
}
stack := awscdk.NewStack(scope, &id, &sprops)
preproductionAccountId := "PREPRODUCTION_ACCOUNT_ID"
productionAccountId := "PRODUCTION_ACCOUNT_ID"
dataBrewPipeline := cdkdatabrewcicd.NewDataBrewCodePipeline(stack, jsii.String("DataBrewCicdPipeline"), &cdkdatabrewcicd.DataBrewCodePipelineProps{
PreproductionIamRoleArn: jsii.String(fmt.Sprintf("arn:%s:iam::%s:role/preproduction-Databrew-Cicd-Role", *awscdk.Aws_PARTITION(), preproductionAccountId)),
ProductionIamRoleArn: jsii.String(fmt.Sprintf("arn:%s:iam::%s:role/production-Databrew-Cicd-Role", *awscdk.Aws_PARTITION(), productionAccountId)),
// BucketName: jsii.String("OPTIONAL"),
// RepoName: jsii.String("OPTIONAL"),
// BranchName: jsii.String("OPTIONAL"),
// PipelineName: jsii.String("OPTIONAL"),
})
awscdk.NewCfnOutput(stack, jsii.String("OPreproductionLambdaArn"), &awscdk.CfnOutputProps{Value: dataBrewPipeline.PreproductionFunctionArn()})
awscdk.NewCfnOutput(stack, jsii.String("OProductionLambdaArn"), &awscdk.CfnOutputProps{Value: dataBrewPipeline.ProductionFunctionArn()})
awscdk.NewCfnOutput(stack, jsii.String("OCodeCommitRepoArn"), &awscdk.CfnOutputProps{Value: dataBrewPipeline.CodeCommitRepoArn()})
awscdk.NewCfnOutput(stack, jsii.String("OCodePipelineArn"), &awscdk.CfnOutputProps{Value: dataBrewPipeline.CodePipelineArn()})
return stack
}
func main() {
defer jsii.Close()
app := awscdk.NewApp(nil)
NewGoLangStack(app, "GoLangStack", &GoLangStackProps{
awscdk.StackProps{
Env: env(),
},
})
app.Synth(nil)
}
func env() *awscdk.Environment {
return nil
}
Some Efforts after Stack Creation
CodeCommit
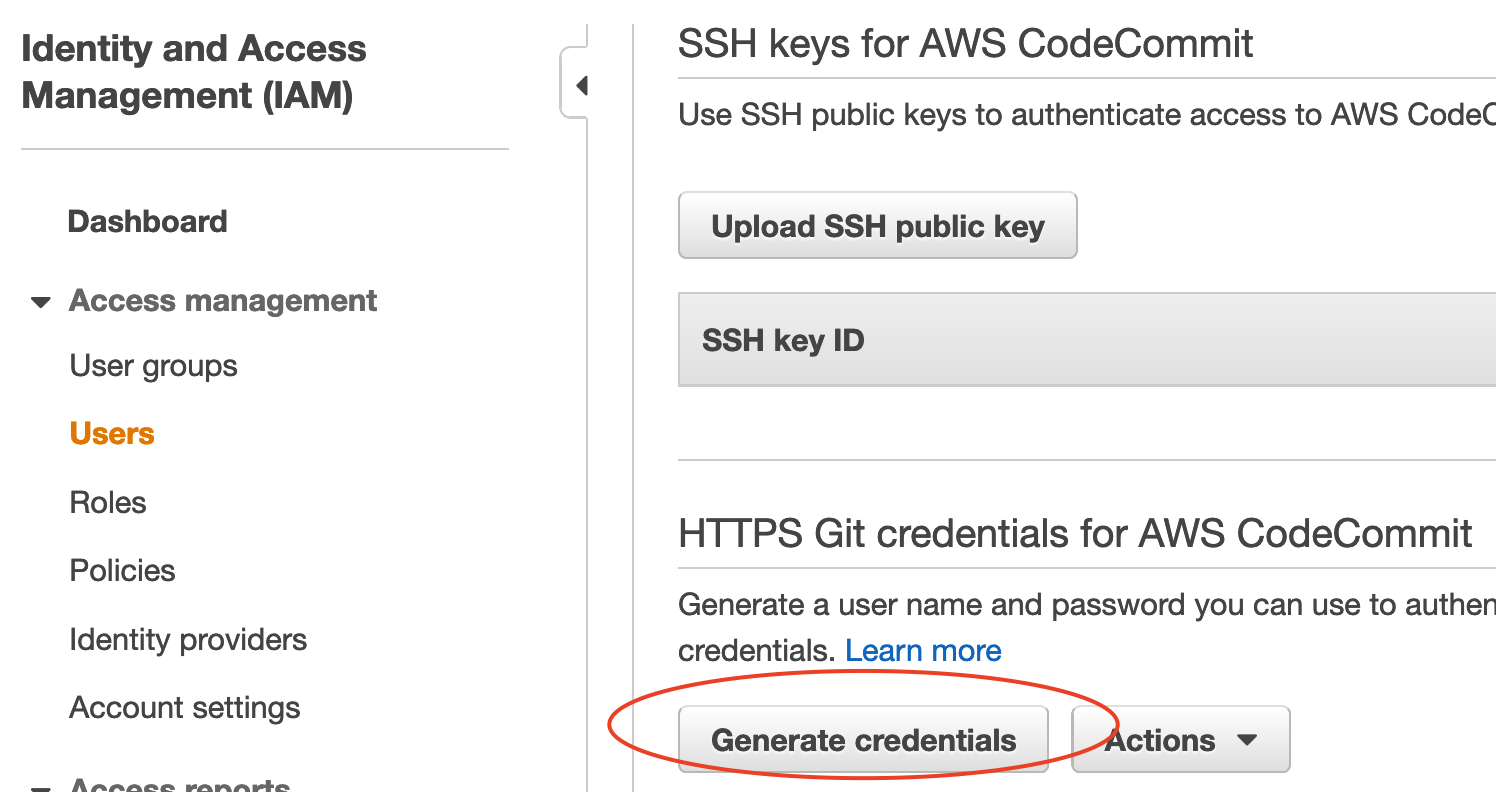
- Create HTTPS Git credentials for AWS CodeCommit with an IAM user that you're going to use.
- Run through the steps noted on the README.md of the CodeCommit repository after finishing establishing the stack via CDK. The returned message with success should be looked like the following (assume you have installed
git-remote-codecommit):$ git clone codecommit://scott.codecommit@DataBrew-Recipes-Repo Cloning into 'DataBrew-Recipes-Repo'... remote: Counting objects: 6, done. Unpacking objects: 100% (6/6), 2.03 KiB | 138.00 KiB/s, done. - Add a DataBrew recipe into the local repositroy (directory) and commit the change. (either directly on the main branch or merging another branch into the main branch)
Glue DataBrew
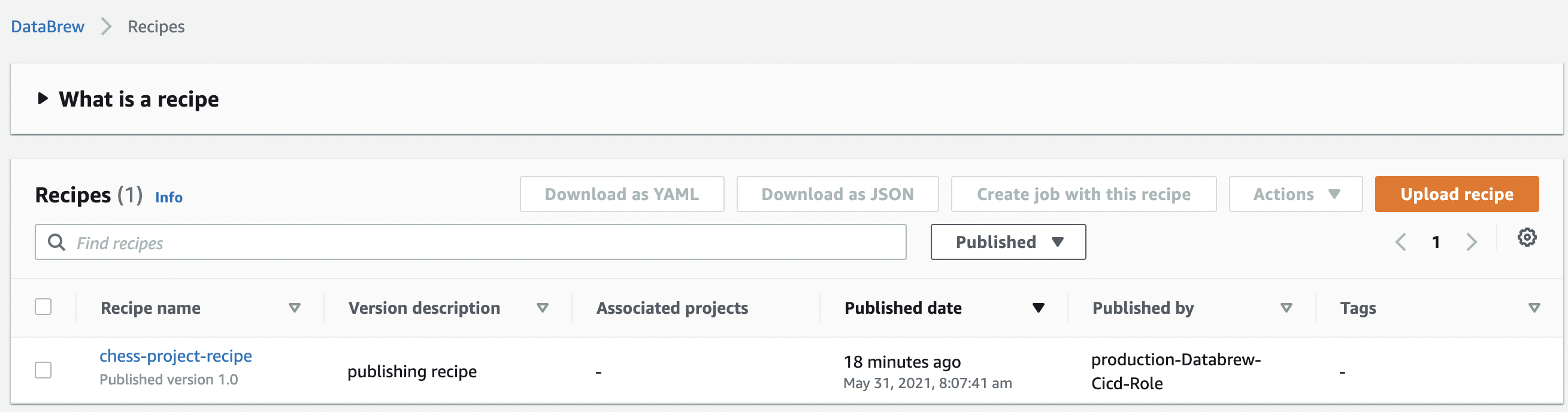
- Download any recipe either generated out by following Getting started with AWS Glue DataBrew or made by yourself as JSON file.
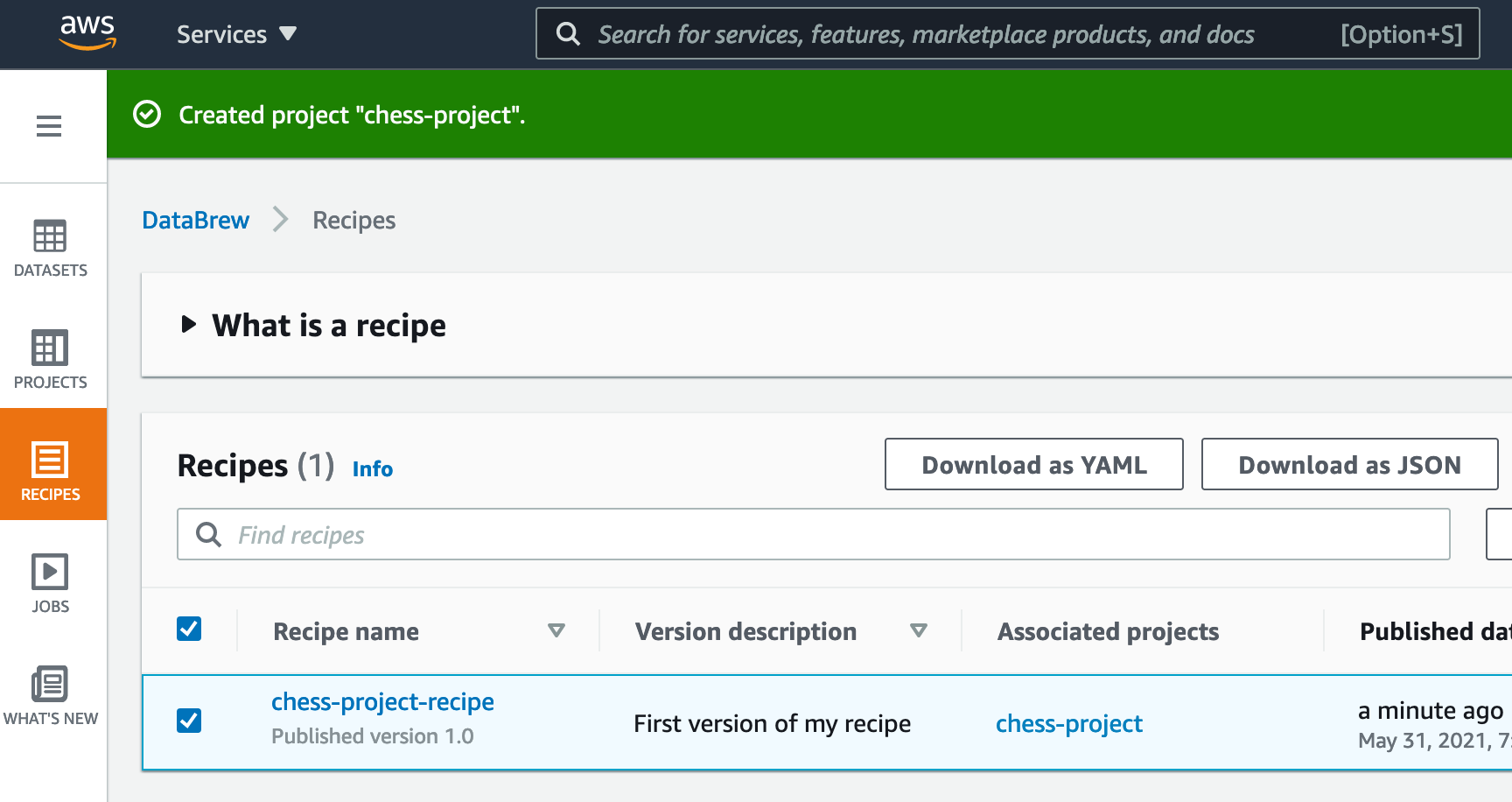
- Move the recipe from the download directory to the local directory for the CodeCommit repository.
$ mv ${DOWNLOAD_DIRECTORY}/chess-project-recipe.json ${CODECOMMIT_LOCAL_DIRECTORY}/ - Commit the change to a branch with a name you prefer.
$ cd ${{CODECOMMIT_LOCAL_DIRECTORY}} $ git checkout -b add-recipe main $ git add . $ git commit -m "first recipe" $ git push --set-upstream origin add-recipe - Merge the branch into the main branch. Just go to the AWS CodeCommit web console to do the merge as its process is purely the same as you've already done thousands of times on Github but only with different UIs.
How Successful Commits Look Like
- In the infrastructure account, the status of the CodePipeline DataBrew pipeline should be similar as the following:
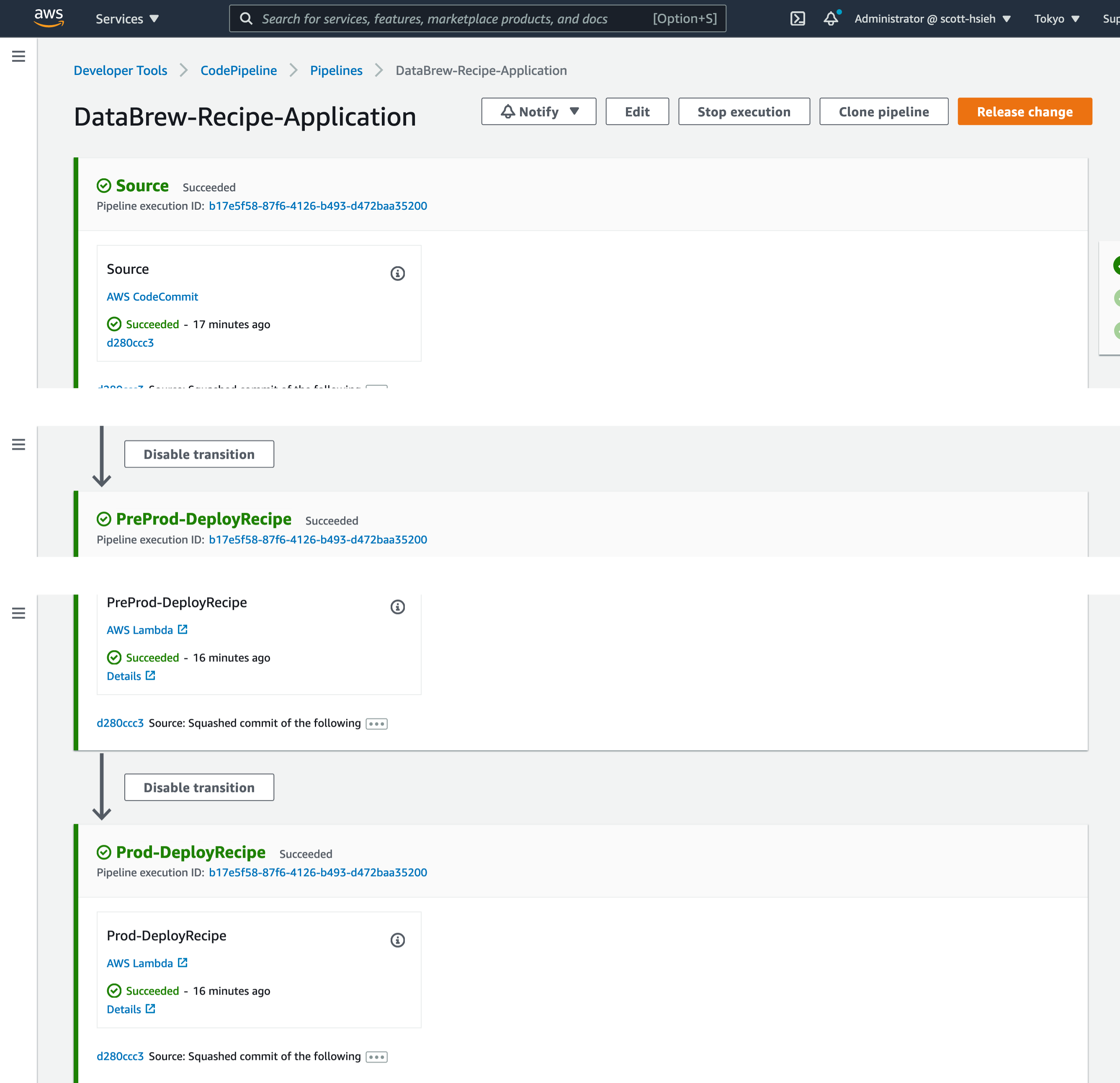
- In the pre-production account with the same region as where the CICD pipeline is deployed at the infrastructue account, you'll see this.
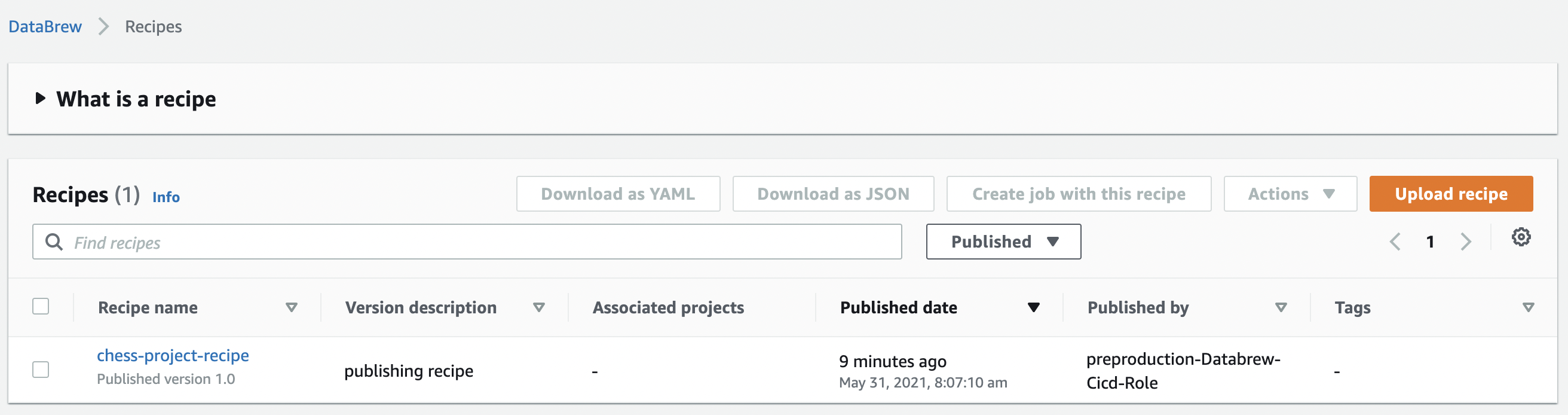
- In the production account with the same region as where the CICD pipeline is deployed at the infrastructue account, you'll see this.