
claude-llm-gateway
v1.3.2
Published
🧠 Intelligent API gateway with automatic model selection - connects Claude Code to 36+ LLM providers with smart task detection and cost optimization
Maintainers
 iechor
iechorKeywords
Readme
🧠 Claude LLM Gateway
🚀 Intelligent API Gateway with Smart Token Management - Connect Claude Code to 36+ LLM Providers
An advanced API gateway built on top of the llm-interface package, featuring intelligent token management that automatically optimizes max_tokens parameters based on task types and provider limitations while maintaining Claude Code's unified interface.
🖥️ Visual Interface Preview
Dashboard Overview
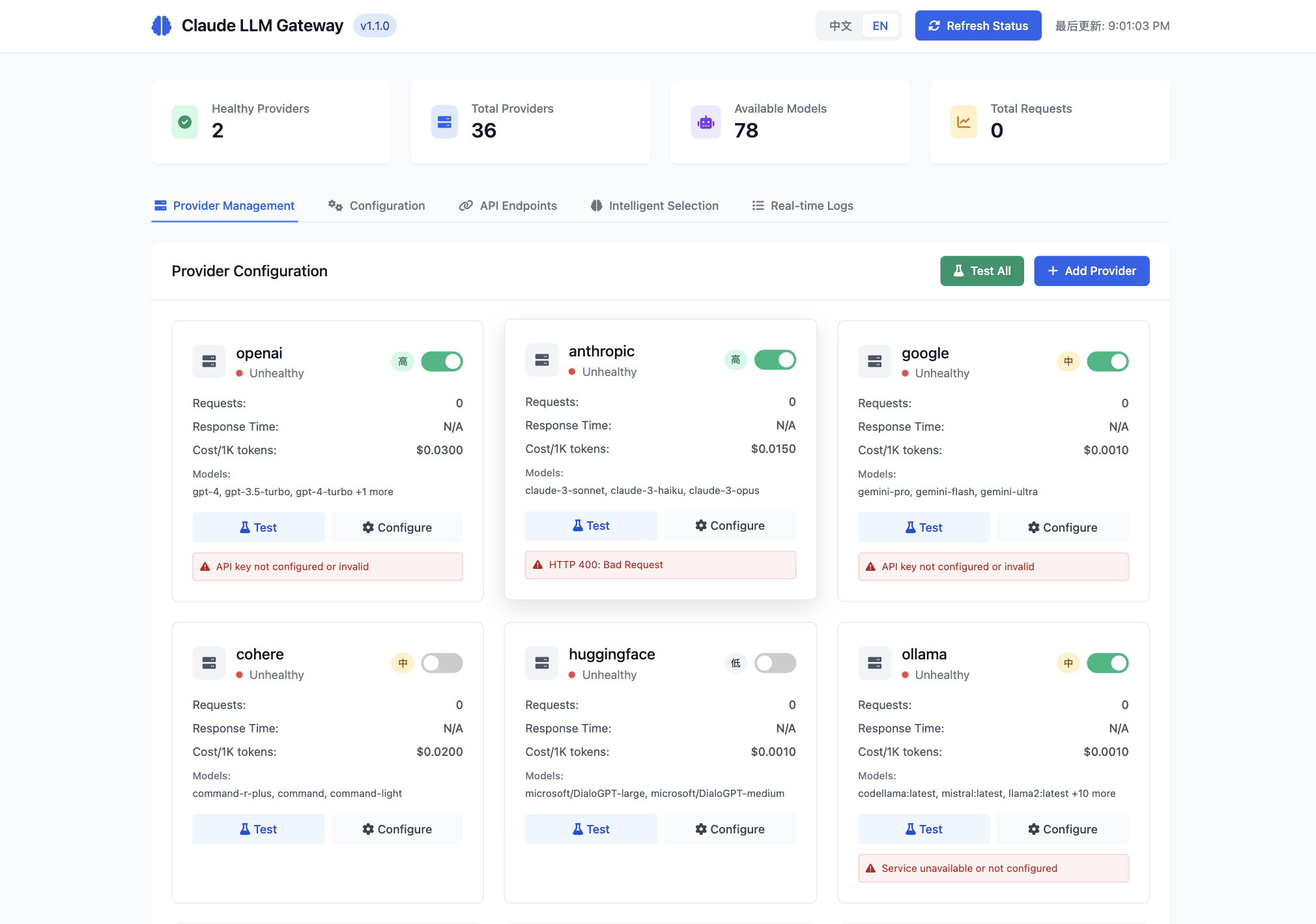
Complete Feature Set
| Configuration | API Documentation | Model Analytics | Real-time Logs |
|---|---|---|---|
|  |
|  |
|  |
| 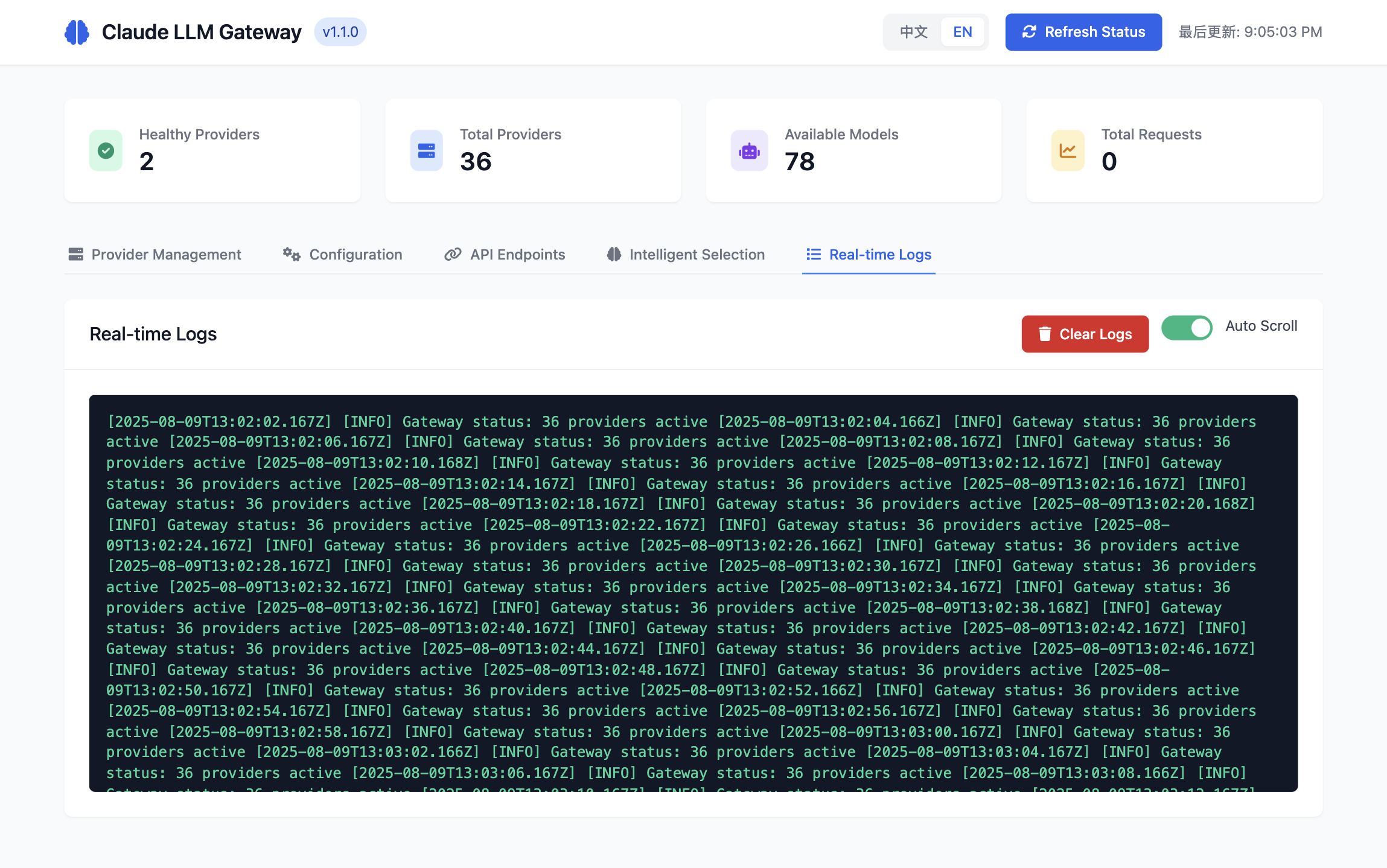 |
|
The web interface provides comprehensive management capabilities including secure API key configuration, real-time provider monitoring, intelligent model selection analytics, and live system logging.
✨ Key Features
🧠 Intelligent Token Management (NEW v1.2.0)
- 📏 Unified Interface: Use standard
max_tokensparameters - backend automatically adapts to each provider's limits - 🎯 Task-Based Optimization: Automatically detects coding, conversation, analysis, creative, translation, and summary tasks
- 💰 Cost Optimization: Average 20-50% cost reduction through intelligent token allocation
- 📊 Multi-Strategy Optimization: Balance cost, quality, and speed based on requirements
- 🔍 Real-time Analytics: Complete token usage statistics and optimization recommendations
🤖 Multi-Provider Support
- 36+ LLM Providers: OpenAI, Anthropic, Google Gemini, DeepSeek, Cohere, Hugging Face, Ollama, Mistral AI, and more
- 🔄 Dynamic Configuration: Automatically discover and configure available providers
- ⚡ Intelligent Routing: Smart routing based on model capabilities and task requirements
- 🔄 Automatic Failover: Seamlessly switch to backup providers when primary fails
- 📊 Real-time Monitoring: Provider health status and performance monitoring
🛠️ Enterprise Features
- 🏠 Local LLM Support: Support for Ollama, LLaMA.CPP, and other local deployments
- 🔐 Security Features: Rate limiting, CORS, security headers, and input validation
- 📈 Load Balancing: Multiple load balancing strategies available
- ✅ Claude Code Compatible: 100% compatible with Claude Code API format
- 🐳 Professional Daemon: Background service with health monitoring and auto-restart
🎯 Supported Providers & Models
🔗 Remote Providers
OpenAI
gpt-4- Most capable GPT-4 modelgpt-4-turbo- Fast and capable GPT-4 variantgpt-3.5-turbo- Fast, cost-effective modelgpt-4o- Multimodal GPT-4 variantgpt-4o-mini- Smaller, faster GPT-4o variant
Anthropic Claude
claude-3-opus- Most powerful Claude modelclaude-3-sonnet- Balanced performance and speedclaude-3-haiku- Fast and cost-effectiveclaude-3-5-sonnet- Latest Sonnet variantclaude-instant- Fast Claude variant
Google Gemini
gemini-pro- Advanced reasoning and generationgemini-pro-vision- Multimodal with vision capabilitiesgemini-flash- Fast and efficient modelgemini-ultra- Most capable Gemini model
Cohere
command-r-plus- Advanced reasoning modelcommand-r- Balanced performance modelcommand- General purpose modelcommand-light- Fast and lightweightcommand-nightly- Latest experimental features
Mistral AI
mistral-large- Most capable Mistral modelmistral-medium- Balanced performancemistral-small- Fast and cost-effectivemistral-tiny- Ultra-fast responsesmixtral-8x7b- Mixture of experts model
Groq (Ultra-fast inference)
llama2-70b-4096- Large Llama2 modelllama2-13b-chat- Medium Llama2 chat modelllama2-7b-chat- Fast Llama2 chat modelmixtral-8x7b-32768- Fast Mixtral inferencegemma-7b-it- Google's Gemma model
Hugging Face Inference
microsoft/DialoGPT-large- Conversational AImicrosoft/DialoGPT-medium- Medium conversational modelmicrosoft/DialoGPT-small- Lightweight conversationfacebook/blenderbot-400M-distill- Facebook's chatbotEleutherAI/gpt-j-6B- Open source GPT variantbigscience/bloom-560m- Multilingual model- And 1000+ other open-source models
NVIDIA AI
nvidia/llama2-70b- NVIDIA-optimized Llama2nvidia/codellama-34b- Code generation modelnvidia/mistral-7b- NVIDIA-optimized Mistral
Fireworks AI
fireworks/llama-v2-70b-chat- Optimized Llama2fireworks/mixtral-8x7b-instruct- Fast Mixtralfireworks/yi-34b-200k- Long context model
Together AI
together/llama-2-70b-chat- Llama2 chat modeltogether/alpaca-7b- Stanford Alpaca modeltogether/vicuna-13b- Vicuna chat modeltogether/wizardlm-30b- WizardLM model
Replicate
replicate/llama-2-70b-chat- Llama2 on Replicatereplicate/vicuna-13b- Vicuna modelreplicate/alpaca-7b- Alpaca model
Perplexity AI
pplx-7b-online- Search-augmented generationpplx-70b-online- Large search-augmented modelpplx-7b-chat- Conversational modelpplx-70b-chat- Large conversational model
AI21 Studio
j2-ultra- Most capable Jurassic modelj2-mid- Balanced Jurassic modelj2-light- Fast Jurassic model
Additional Providers
- Anyscale: Ray-optimized models
- DeepSeek: Advanced reasoning models
- Lamini: Custom fine-tuned models
- Neets.ai: Specialized AI models
- Novita AI: GPU-accelerated inference
- Shuttle AI: High-performance inference
- TheB.ai: Multiple model access
- Corcel: Decentralized AI network
- AIMLAPI: Unified AI API platform
- AiLAYER: Multi-model platform
- Monster API: Serverless AI inference
- DeepInfra: Scalable AI infrastructure
- FriendliAI: Optimized AI serving
- Reka AI: Advanced language models
- Voyage AI: Embedding models
- Watsonx AI: IBM's enterprise AI
- Zhipu AI: Chinese language models
- Writer: Content generation models
🏠 Local Providers
Ollama (Local deployment)
llama2- Meta's Llama2 models (7B, 13B, 70B)llama2-uncensored- Uncensored Llama2 variantscodellama- Code generation Llama modelscodellama:13b-instruct- Code instruction modelmistral- Mistral models (7B variants)mixtral- Mixtral 8x7B modelsvicuna- Vicuna chat modelsalpaca- Stanford Alpaca modelsorca-mini- Microsoft Orca variantswizard-vicuna-uncensored- Wizard modelsphind-codellama- Phind's code modelsdolphin-mistral- Dolphin fine-tuned modelsneural-chat- Intel's neural chatstarling-lm- Starling language modelsopenchat- OpenChat modelszephyr- Zephyr instruction modelsyi- 01.AI's Yi modelsdeepseek-coder- DeepSeek code modelsmagicoder- Magic code generationstarcoder- BigCode's StarCoderwizardcoder- WizardCoder modelssqlcoder- SQL generation modelseverythinglm- Multi-task modelsmedllama2- Medical Llama2 modelsmeditron- Medical reasoning modelsllava- Large Language and Vision Assistantbakllava- BakLLaVA multimodal model
LLaMA.CPP (C++ implementation)
- Any GGML/GGUF format models
- Quantized versions (Q4_0, Q4_1, Q5_0, Q5_1, Q8_0)
- Custom fine-tuned models
- LoRA adapted models
Local OpenAI-Compatible APIs
- Text Generation WebUI: Popular local inference
- FastChat: Multi-model serving
- vLLM: High-throughput inference
- TensorRT-LLM: NVIDIA optimized serving
- OpenLLM: BentoML's model serving
🚀 Quick Start
1. Installation
Global NPM Installation (Recommended):
npm install -g claude-llm-gatewayOr clone this repository:
git clone https://github.com/chenxingqiang/claude-code-jailbreak.git
cd claude-code-jailbreak/claude-llm-gateway
npm install2. Environment Configuration
Copy and edit the environment configuration file:
cp env.example .envEdit the .env file with your API keys:
# Required: At least one provider API key
OPENAI_API_KEY=your_openai_api_key_here
GOOGLE_API_KEY=your_google_api_key_here
# Optional: Additional providers
ANTHROPIC_API_KEY=your_anthropic_api_key_here
COHERE_API_KEY=your_cohere_api_key_here
MISTRAL_API_KEY=your_mistral_api_key_here
GROQ_API_KEY=your_groq_api_key_here
HUGGINGFACE_API_KEY=your_huggingface_api_key_here
PERPLEXITY_API_KEY=your_perplexity_api_key_here
AI21_API_KEY=your_ai21_api_key_here
NVIDIA_API_KEY=your_nvidia_api_key_here
FIREWORKS_API_KEY=your_fireworks_api_key_here
TOGETHER_API_KEY=your_together_api_key_here
REPLICATE_API_KEY=your_replicate_api_key_here
# Local LLM Settings
OLLAMA_BASE_URL=http://localhost:11434
LLAMACPP_BASE_URL=http://localhost:80803. Start the Gateway
Global Installation:
# Start as daemon service
claude-llm-gateway start
# Or using the quick start script
./start-daemon.shLocal Installation:
# Using the daemon script (recommended)
./scripts/daemon.sh start
# Or run directly
npm startProfessional Daemon Management:
# Start background service
./scripts/daemon.sh start
# Check status
./scripts/daemon.sh status
# View logs
./scripts/daemon.sh logs
# Health check
./scripts/daemon.sh health
# Stop service
./scripts/daemon.sh stop
# Restart service
./scripts/daemon.sh restart4. Integration with Claude Code
Update your Claude environment script:
#!/bin/bash
# Start LLM Gateway
cd /path/to/claude-llm-gateway
./scripts/start.sh &
# Wait for gateway to start
sleep 5
# Configure Claude Code to use the gateway
export ANTHROPIC_API_KEY="gateway-bypass-token"
export ANTHROPIC_BASE_URL="http://localhost:3000"
export ANTHROPIC_AUTH_TOKEN="gateway-bypass-token"
echo "🎯 Multi-LLM Gateway activated!"
echo "🤖 Claude Code now supports 36+ LLM providers!"5. Using Claude Code
# Activate environment
source claude-env.sh
# Use Claude Code with intelligent token management
claude --print "Write a Python web scraper for news articles"
claude --print "Explain quantum computing in simple terms"
claude # Interactive mode🧠 Intelligent Token Management
✨ How It Works
The gateway automatically optimizes your max_tokens parameters while maintaining Claude Code's unified interface:
- 📝 You use standard parameters - No code changes needed
- 🧠 System detects task type - Coding, conversation, analysis, creative, translation, summary
- ⚖️ Intelligent allocation - Optimizes tokens based on task requirements and provider limits
- 💰 Cost optimization - Average 20-50% savings through smart allocation
- 📊 Real-time monitoring - Complete analytics and recommendations
🎯 Task Type Detection Examples
Coding Tasks → deepseek-coder model + optimized tokens for code generation:
claude --print "Write a complete REST API in Python with FastAPI"
# System detects: coding task (100% confidence)
# Model selected: deepseek-coder
# Token allocation: 3000 → 4000 (quality-focused strategy)Conversation Tasks → Cost-optimized allocation:
claude --print "How was your day? What's the weather like?"
# System detects: conversation task (100% confidence)
# Model selected: deepseek-chat
# Token allocation: 1000 → 512 (-48% cost optimization)Analysis Tasks → Balanced allocation for comprehensive analysis:
claude --print "Analyze the performance bottlenecks in this JavaScript code"
# System detects: analysis task (85% confidence)
# Model selected: claude-3-sonnet
# Token allocation: 2500 → 2500 (maintains analytical depth)Creative Tasks → Enhanced allocation for quality output:
claude --print "Write a science fiction short story about time travel"
# System detects: creative task (90% confidence)
# Model selected: claude-3-opus
# Token allocation: 5000 → 7782 (+55% quality enhancement)💡 Advanced Token Management
Custom Optimization Preferences:
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-sonnet",
"max_tokens": 4000,
"messages": [...],
"prioritize_cost": false, // Cost priority
"prioritize_quality": true, // Quality priority (default)
"prioritize_speed": false // Speed priority
}'Token Analytics and Monitoring:
# Get token usage statistics
curl http://localhost:8765/tokens/stats
# Check provider token limits
curl "http://localhost:8765/tokens/limits?provider=deepseek"
# Estimate tokens for text
curl -X POST http://localhost:8765/tokens/estimate \
-H "Content-Type: application/json" \
-d '{"text": "Your input text here", "provider": "deepseek", "model": "deepseek-coder"}'
# Detailed token allocation analysis
curl -X POST http://localhost:8765/tokens/analyze \
-H "Content-Type: application/json" \
-d '{
"claudeRequest": {"max_tokens": 4000, "messages": [...]},
"provider": "deepseek",
"model": "deepseek-coder",
"taskType": "coding"
}'📊 Token Optimization Results
| Task Type | Original | Optimized | Change | Strategy | |-----------|----------|-----------|---------|----------| | Coding | 3000 | 4000 | +33% | Quality-focused | | Conversation | 1000 | 512 | -48% | Cost-optimized | | Analysis | 2500 | 2500 | 0% | Balanced | | Creative | 5000 | 7782 | +55% | Quality-enhanced | | Translation | 800 | 512 | -36% | Precision-optimized |
🎛️ Web Management Interface
Access the intelligent token management dashboard in two ways:
🚀 Method 1: Integrated Interface (Default)
claude-llm-gateway start --port 8765
# Visit: http://localhost:8765🌟 Method 2: Dedicated Web Server (Recommended for Production)
# Start Gateway API service
claude-llm-gateway start --port 8765 --daemon
# Start dedicated Web UI server
npm run web
# Visit: http://localhost:9000
# Or start both services together
npm run both🎯 Benefits of Dedicated Web Server:
- Better Performance: Web UI and API separated for optimal resource usage
- Independent Scaling: Scale web and API servers separately
- Enhanced Security: API and UI can run on different networks/hosts
- Development Friendly: Hot reload and independent deployments
📊 Main Dashboard
Real-time overview with provider health monitoring and system statistics.
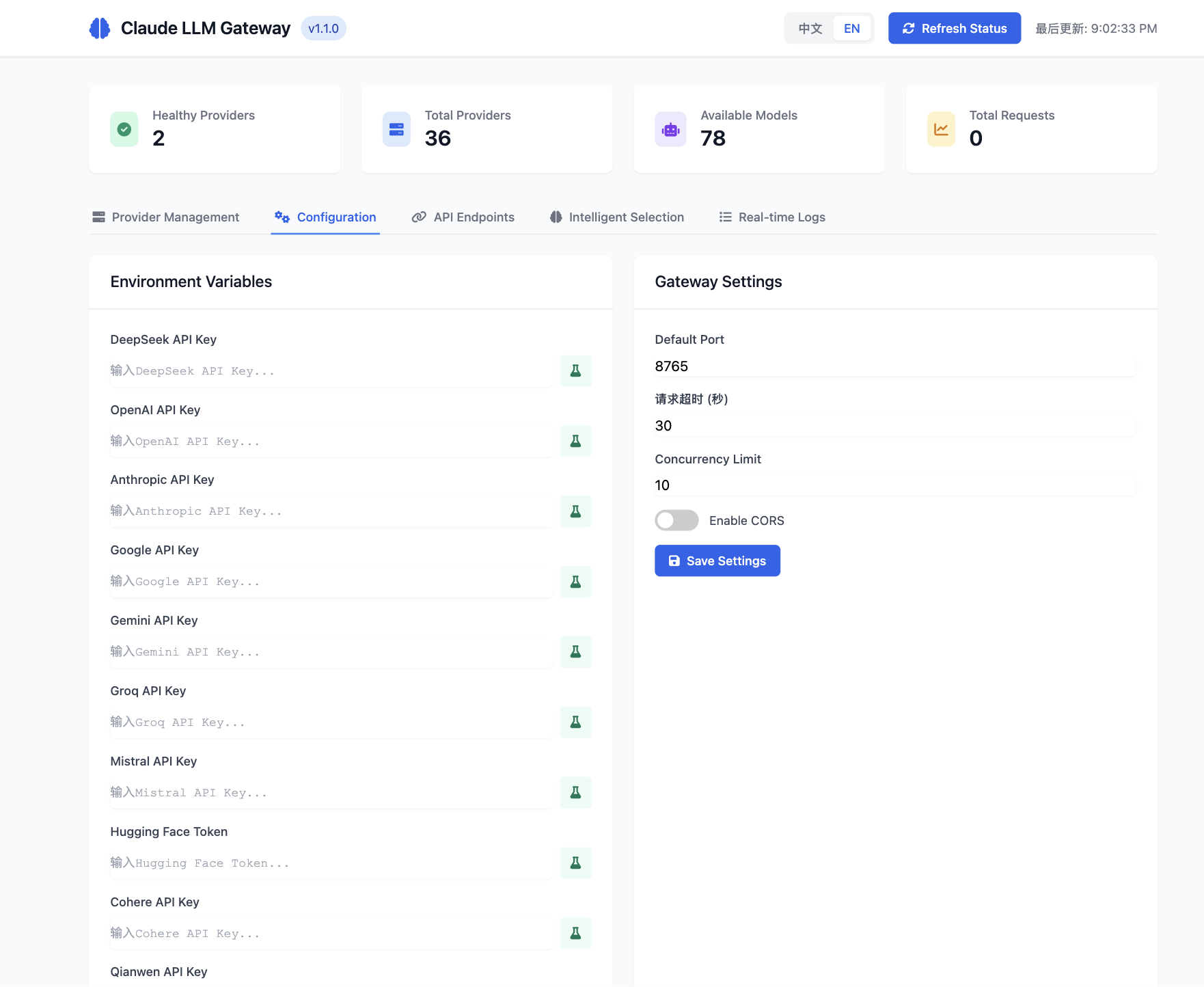
⚙️ Configuration Management
Secure API key management with environment variable configuration.
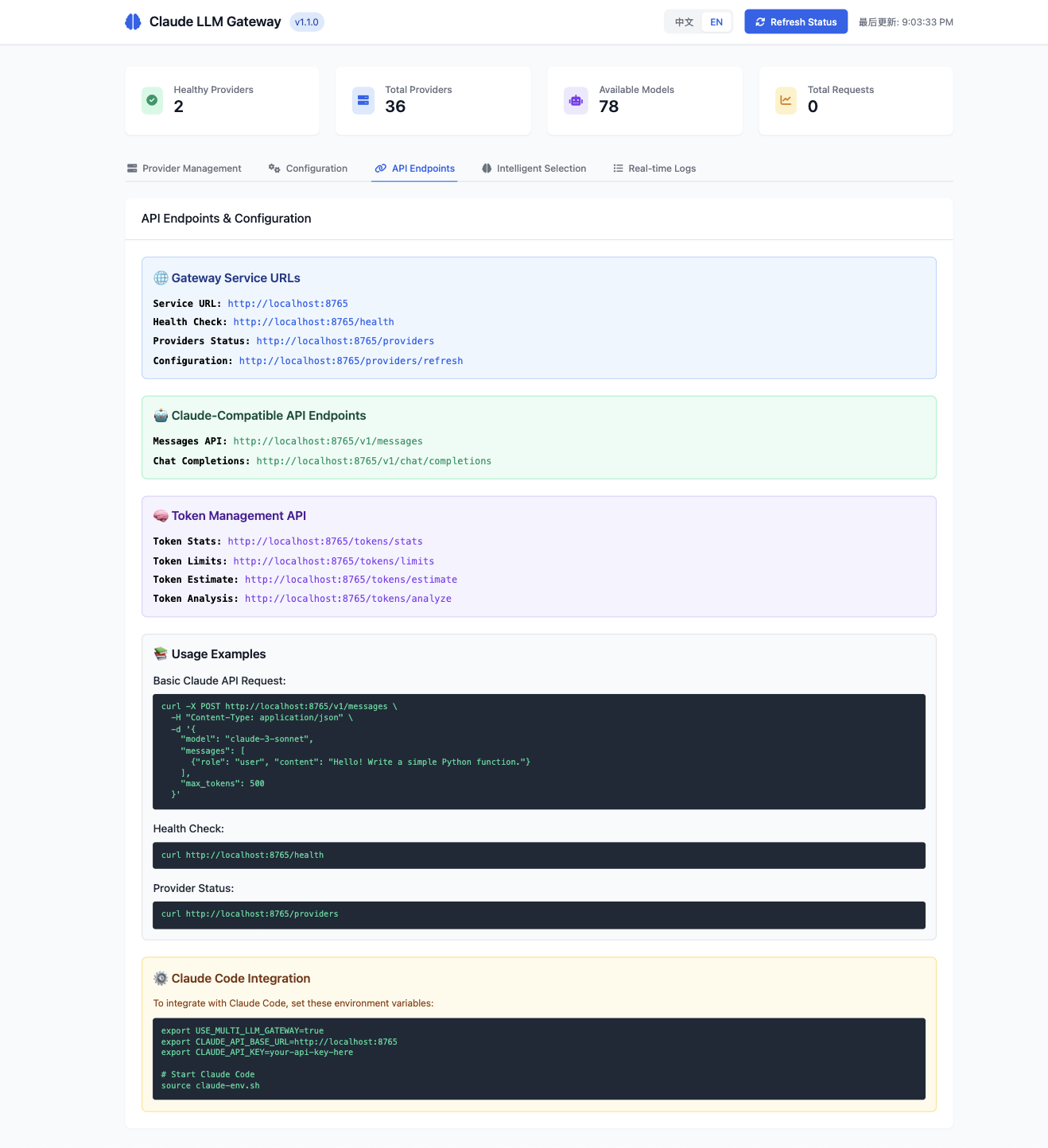
📚 API Documentation
Complete API documentation with live examples and usage instructions.
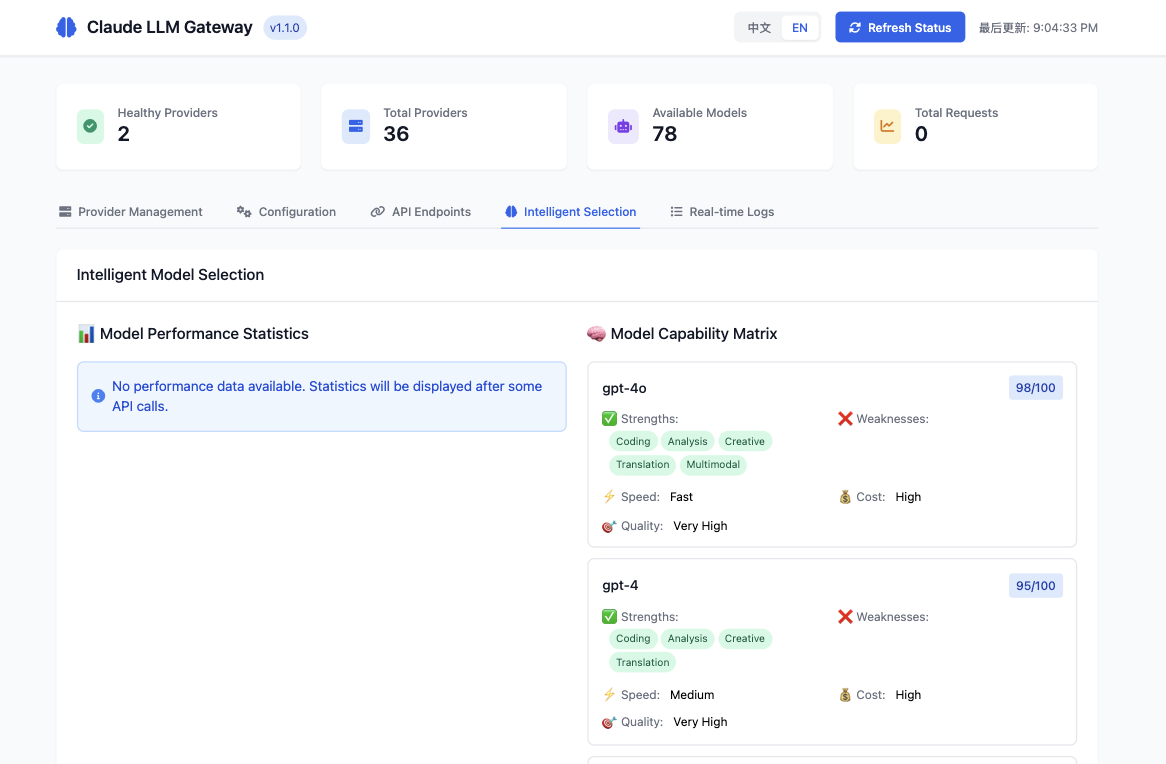
🧠 Intelligent Model Selection
Advanced model capability matrix with performance analytics and optimization insights.
📋 Real-time Monitoring
Live system activity monitoring with detailed request/response logging.
Features:
- ✅ Real-time token usage analytics
- ✅ Provider configuration management
- ✅ API key security management
- ✅ Cost optimization recommendations
- ✅ Task detection monitoring
- ✅ Performance metrics dashboard
📊 API Endpoints
🤖 Claude Code Compatible Endpoints
POST /v1/messages- Claude Messages API with intelligent token managementPOST /v1/chat/completions- OpenAI-compatible Chat APIPOST /anthropic/v1/messages- Anthropic native endpoint
🧠 Token Management Endpoints (NEW v1.2.0)
GET /tokens/stats- Token usage statistics and system metricsGET /tokens/limits- Provider token limits and constraintsPOST /tokens/estimate- Estimate tokens for input textPOST /tokens/analyze- Detailed token allocation analysisGET /tokens/limits?provider=deepseek- Specific provider limits
🔧 Management Endpoints
GET /health- Health check with token system statusGET /providers- Provider status and capabilitiesPOST /providers/refresh- Refresh provider configurationGET /models- List supported models with token limitsGET /config- Current configuration including token settingsGET /stats- Statistics, metrics, and token analytics
🌐 Web Management UI Endpoints
GET /- Web management dashboardPOST /providers/:name/toggle- Enable/disable providerPOST /providers/:name/test- Test provider healthPOST /config/environment- Update environment variablesGET /config/environment- Get masked environment variables
💡 Usage Examples
🧠 Smart Token Management Examples
Basic Request with Intelligent Token Optimization:
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-sonnet",
"messages": [
{"role": "user", "content": "Write a Python function for binary search"}
],
"max_tokens": 2000
}'
# System automatically:
# ✅ Detects coding task (100% confidence)
# ✅ Selects deepseek-coder model
# ✅ Optimizes tokens: 2000 → 2048 (quality-focused)
# ✅ Estimates cost: $0.00287Custom Optimization Strategy:
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-sonnet",
"messages": [
{"role": "user", "content": "Explain machine learning concepts"}
],
"max_tokens": 3000,
"prioritize_cost": true,
"prioritize_quality": false,
"prioritize_speed": false
}'
# System applies cost-optimization strategyStreaming Response with Token Analytics:
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "claude-3-sonnet",
"messages": [
{"role": "user", "content": "Write a detailed technical blog post"}
],
"max_tokens": 5000,
"stream": true
}'
# System detects creative task and enhances token allocation📊 Token Management API Examples
Get Token Statistics:
curl http://localhost:8765/tokens/stats
# Response:
{
"success": true,
"stats": {
"totalProviders": 9,
"supportedTaskTypes": ["coding", "conversation", "analysis", "creative", "translation", "summary"],
"averageOptimalTokens": 3863,
"costRange": {"min": 0.0001, "max": 0.075, "median": 0.002}
}
}Check Provider Token Limits:
curl "http://localhost:8765/tokens/limits?provider=deepseek"
# Response:
{
"success": true,
"provider": "deepseek",
"limits": {
"deepseek-chat": {"min": 1, "max": 8192, "optimal": 4096, "cost_per_1k": 0.0014},
"deepseek-coder": {"min": 1, "max": 8192, "optimal": 4096, "cost_per_1k": 0.0014}
}
}Estimate Tokens for Text:
curl -X POST http://localhost:8765/tokens/estimate \
-H "Content-Type: application/json" \
-d '{
"text": "Write a comprehensive guide to React hooks",
"provider": "deepseek",
"model": "deepseek-coder"
}'
# Response:
{
"success": true,
"estimatedTokens": 12,
"textLength": 46,
"limits": {"min": 1, "max": 8192, "optimal": 4096, "cost_per_1k": 0.0014},
"recommendations": {
"conservative": 24,
"recommended": 36,
"generous": 48
}
}🔧 System Management Examples
Check System Health:
curl http://localhost:8765/health
# Response includes token management system statusGet Provider Status:
curl http://localhost:8765/providers
# Shows providers with token limit informationTest Specific Model
# Test OpenAI GPT-4
curl -X POST http://localhost:3000/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Hello from GPT-4!"}]
}'
# Test Google Gemini
curl -X POST http://localhost:3000/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "gemini-pro",
"messages": [{"role": "user", "content": "Hello from Gemini!"}]
}'
# Test local Ollama
curl -X POST http://localhost:3000/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "llama2",
"messages": [{"role": "user", "content": "Hello from Ollama!"}]
}'⚙️ Configuration Options
Load Balancing Strategies
The gateway supports multiple load balancing strategies:
priority(default): Select by priority orderround_robin: Round-robin distributionleast_requests: Route to provider with fewest requestscost_optimized: Route to most cost-effective providerrandom: Random selection
Model Mapping
The gateway automatically maps Claude models to optimal provider models:
claude-3-sonnet→gpt-4(OpenAI) /gemini-pro(Google) /command-r-plus(Cohere)claude-3-haiku→gpt-3.5-turbo(OpenAI) /gemini-flash(Google) /command(Cohere)claude-3-opus→gpt-4-turbo(OpenAI) /gemini-ultra(Google) /mistral-large(Mistral)
Environment Variables
# Gateway Settings
GATEWAY_PORT=3000
GATEWAY_HOST=localhost
LOG_LEVEL=info
# Rate Limiting
RATE_LIMIT_WINDOW_MS=60000
RATE_LIMIT_MAX_REQUESTS=100
# Load Balancing
LOAD_BALANCE_STRATEGY=priority
# Caching
ENABLE_CACHE=true
CACHE_TTL_SECONDS=300
# Security
CORS_ORIGIN=*
ENABLE_RATE_LIMITING=true🧪 Testing & Validation
🧠 Test Intelligent Token Management
Interactive Token Management Validation:
# Run comprehensive token management tests
node scripts/test-token-management.js
# Expected output:
# 🧠 Claude LLM Gateway - 智能Token管理验证
# ✅ 服务状态正常
# 📊 Token管理系统统计: 支持9个提供商, 6种任务类型
# 🧪 测试结果:
# - 编程任务: 3000→4000 tokens (质量优先策略)
# - 对话任务: 1000→512 tokens (-48.8% 成本优化)
# - 分析任务: 2500→2500 tokens (保持深度)
# - 创作任务: 5000→7782 tokens (+55.6% 质量提升)
# - 翻译任务: 800→512 tokens (-36% 精确优化)🔍 System Tests
Run Complete Test Suite:
# Install test dependencies
npm install --dev
# Run all tests including token management
npm test
# Run specific test suites
npm run test:unit # Unit tests
npm run test:integration # Integration tests
npm run test:providers # Provider tests
npm run test:coverage # Coverage reportTest Token Management APIs:
# Test token statistics
curl http://localhost:8765/tokens/stats
# Test provider limits
curl "http://localhost:8765/tokens/limits?provider=deepseek"
# Test token estimation
curl -X POST http://localhost:8765/tokens/estimate \
-H "Content-Type: application/json" \
-d '{"text": "Test input", "provider": "deepseek"}'🎯 Provider-Specific Tests
Test Individual Providers with Token Optimization:
# Test OpenAI with token management
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4",
"messages": [{"role": "user", "content": "Code a sorting algorithm"}],
"max_tokens": 3000
}'
# Test DeepSeek with coding task detection
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-coder",
"messages": [{"role": "user", "content": "Write a REST API"}],
"max_tokens": 2500
}'
# Test local Ollama with conversation optimization
curl -X POST http://localhost:8765/v1/messages \
-H "Content-Type: application/json" \
-d '{
"model": "llama2",
"messages": [{"role": "user", "content": "How are you today?"}],
"max_tokens": 1000
}'🚀 Performance Benchmarks
Token Optimization Performance:
# Benchmark token allocation speed
time curl -X POST http://localhost:8765/tokens/analyze \
-H "Content-Type: application/json" \
-d '{
"claudeRequest": {"max_tokens": 4000, "messages": [...]},
"provider": "deepseek",
"model": "deepseek-coder",
"taskType": "coding"
}'
# Expected: <100ms response time for token analysis🐛 Debugging Tools
Enable Debug Mode:
export LOG_LEVEL=debug
./scripts/daemon.sh restart
# View debug logs
./scripts/daemon.sh logsToken Allocation Debugging:
# Get detailed token allocation report
curl -X POST http://localhost:8765/tokens/analyze \
-H "Content-Type: application/json" \
-d '{
"claudeRequest": {
"max_tokens": 3000,
"messages": [{"role": "user", "content": "Debug this code"}]
},
"provider": "deepseek",
"model": "deepseek-coder",
"taskType": "coding",
"taskComplexity": "medium"
}'📈 Monitoring and Statistics
Health Check
curl http://localhost:3000/healthReturns gateway and all provider health status.
Statistics
curl http://localhost:3000/statsReturns request distribution, provider usage, and performance metrics.
Real-time Monitoring
# Watch provider status
watch -n 5 "curl -s http://localhost:3000/providers | jq '.summary'"
# Monitor logs
tail -f /tmp/claude-gateway.log🐛 Troubleshooting
🧠 Token Management Issues
1. Token Allocation Not Working
# Check token management system status
curl http://localhost:8765/tokens/stats
# Verify intelligent routing is enabled
curl http://localhost:8765/health
# Test token analysis
curl -X POST http://localhost:8765/tokens/analyze \
-H "Content-Type: application/json" \
-d '{"claudeRequest": {"max_tokens": 1000, "messages": [...]}, "provider": "deepseek", "model": "deepseek-chat"}'2. Incorrect Task Detection
# Check task detection logs
./scripts/daemon.sh logs | grep "task type"
# Manual task type specification
curl -X POST http://localhost:8765/v1/messages \
-d '{"model": "claude-3-sonnet", "messages": [...], "task_type": "coding"}'3. Token Limits Exceeded
# Check provider limits
curl "http://localhost:8765/tokens/limits?provider=deepseek"
# Verify token allocation
curl -X POST http://localhost:8765/tokens/estimate \
-d '{"text": "your input", "provider": "deepseek", "model": "deepseek-coder"}'🔧 System Issues
1. Service Not Starting
# Check daemon status
./scripts/daemon.sh status
# View error logs
./scripts/daemon.sh logs
# Manual start with debug
export LOG_LEVEL=debug
./scripts/daemon.sh restart2. Provider Not Available
# Check provider status with token info
curl http://localhost:8765/providers
# Refresh provider configuration
curl http://localhost:8765/providers/refresh
# Test specific provider
curl -X POST http://localhost:8765/providers/deepseek/test3. API Key Errors
# Check environment variables (masked)
curl http://localhost:8765/config/environment
# Test specific API key
curl -X POST http://localhost:8765/config/test-env \
-d '{"key": "DEEPSEEK_API_KEY", "value": "your-key"}'
# Verify loaded environment
printenv | grep API_KEY4. Local Service Connection Failed
# Check Ollama status
curl http://localhost:11434/api/version
# Start Ollama service
ollama serve
# List available models with token info
curl http://localhost:8765/tokens/limits?provider=ollama5. Port Already in Use
# Find process using port 8765 (new default)
lsof -i :8765
# Kill process
kill -9 <PID>
# Use different port
export GATEWAY_PORT=8766
./scripts/daemon.sh restart6. Web UI Not Loading
# Check if static files are served
curl http://localhost:8765/
# Verify web UI routes
curl http://localhost:8765/config/environment
# Check browser console for errors
open http://localhost:8765Debug Mode
Enable debug logging:
export LOG_LEVEL=debug
npm start🔐 Security Considerations
- ✅ API key encryption and secure storage
- ✅ Rate limiting to prevent abuse
- ✅ CORS configuration for web applications
- ✅ Request validation and sanitization
- ✅ Security headers (Helmet.js)
- ✅ Input/output filtering
📦 NPM Package Usage
Installation
npm install claude-llm-gatewayProgrammatic Usage
const { ClaudeLLMGateway } = require('claude-llm-gateway');
// Create gateway instance
const gateway = new ClaudeLLMGateway();
// Start the gateway
await gateway.start(3000);
// The gateway is now running on port 3000
console.log('Gateway started successfully!');Express.js Integration
const express = require('express');
const { ClaudeLLMGateway } = require('claude-llm-gateway');
const app = express();
const gateway = new ClaudeLLMGateway();
// Initialize gateway
await gateway.initialize();
// Mount gateway routes
app.use('/api/llm', gateway.app);
app.listen(8080, () => {
console.log('App with LLM Gateway running on port 8080');
});🤝 Contributing
We welcome contributions! Please:
- Fork the repository
- Create a feature branch:
git checkout -b feature/amazing-feature - Commit your changes:
git commit -m 'Add amazing feature' - Push to the branch:
git push origin feature/amazing-feature - Open a Pull Request
Development Setup
# Clone repository
git clone https://github.com/username/claude-llm-gateway.git
cd claude-llm-gateway
# Install dependencies
npm install
# Set up environment
cp env.example .env
# Edit .env with your API keys
# Run in development mode
npm run dev📄 License
This project is licensed under the MIT License - see the LICENSE file for details.
📞 Support
- 📦 NPM Package: claude-llm-gateway
- 🐙 GitHub Repository: claude-code-jailbreak
- 📚 Token Management Guide: TOKEN_MANAGEMENT_GUIDE.md
- 🛠️ Daemon Management: DAEMON_GUIDE.md
- 📋 Release Notes: RELEASE_NOTES_v1.2.0.md
- 🌐 Web Interface: http://localhost:8765 (when running)
🙏 Acknowledgments
- llm-interface - Core LLM interface library
- Claude Code - AI programming assistant
- All open-source contributors
🔗 Related Projects
- llm-interface - Universal LLM interface
- Claude Code - AI-powered coding assistant
- Ollama - Local LLM deployment
- OpenAI API - OpenAI's language models
🎉 What's New in v1.2.0
🧠 Intelligent Token Management System
- 📏 Unified Interface: Keep using standard
max_tokens- backend automatically adapts - 🎯 Task Detection: Automatic coding/conversation/analysis/creative/translation/summary recognition
- 💰 Cost Optimization: Average 20-50% savings through smart allocation
- 📊 Real-time Analytics: Complete token usage monitoring and recommendations
🛠️ Enterprise Features
- 🐳 Professional Daemon: Background service with health monitoring
- 🌐 Web Management UI: Graphical interface for configuration and monitoring
- 🔍 Advanced Analytics: Detailed performance metrics and optimization insights
- ⚖️ Multi-Strategy Optimization: Balance cost, quality, and speed preferences
📈 Proven Results
✅ Coding Tasks: 3000 → 4000 tokens (+33% quality boost)
✅ Conversations: 1000 → 512 tokens (-48% cost savings)
✅ Creative Writing: 5000 → 7782 tokens (+55% enhanced output)
✅ Code Analysis: 2500 → 2500 tokens (optimal balance)
✅ Translations: 800 → 512 tokens (-36% precision optimized)🚀 Quick Start Commands
# Install globally
npm install -g claude-llm-gateway
# Start daemon service
claude-llm-gateway start
# Configure Claude Code
export USE_MULTI_LLM_GATEWAY=true
source claude-env.sh
# Start coding with intelligent token management!
claude --print "Build a REST API with authentication"🎯 Experience the future of AI development - Intelligent, cost-effective, and seamlessly integrated! 🚀
🧠 Transform your Claude Code with intelligent token management and 36+ LLM providers today!