
cranium
v1.3.3
Published
Streaming SVM trainer that uses stochastic gradient descent
Maintainers
 benng
benngReadme
cranium

Machine learning with streams.
var train = require('cranium').train
, opts = {
features: ['attr1', 'attr2']
, classAttribute: 'class'
}
train('input.csv', opts, function (err, machine) {
if(machine.predict({attr1: 5, attr2: 2}) > 0)
console.log('true')
else
console.log('false')
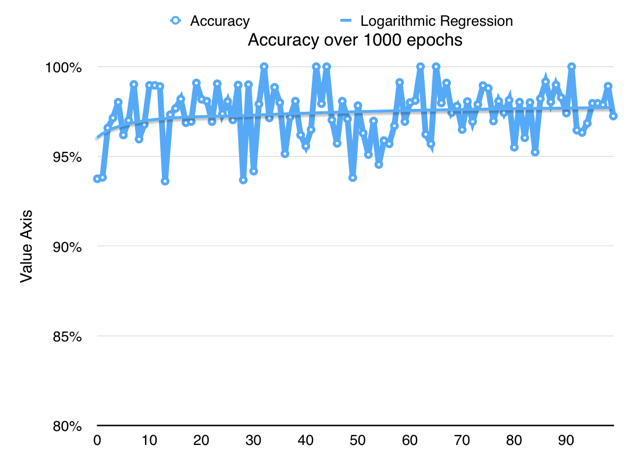
})Accuracy rates of around 99% can be achieved once parameters are tuned for your data.
An example run with 1000 epochs on the University of Wisconsin's breast cancer data.
Tradeoffs
Plenty of options for machine learning exist if your dataset can fit in memory. I recommend my friend Matt Rajca's LearnKit, or Weka if you like having a GUI.
The amount of data you need to build a good classifier increases with the number of features you have, so out of memory errors become a problem when dealing with thousands of features. For example, Weka fails to perform logistic regression with more than a couple thousand features on a 5mb dataset. Cranium never assumes that your instances can fit in memory, so you can use it on terabytes of data.
Cranium works with node streams, so you have a lot of flexibility with your input. Using streams sacrifies speed for memory efficiency -- Cranium uses a constant amount of memory that is typically below 100mb. The speed penalty is significant: Cranium runs about 500x slower than LearnKit. If your dataset can fit in memory, Cranium is probably not right for you.
Training
train
The train function creates a support vector machine and trains it on your data using stochastic gradient descent.
function train (input, opts, cb) {}
- input - Either a CSV file's path, or a function that returns an instance stream
- opts - An object, options are documented below
- cb - A callback with signature
function cb (err, svm)
train.opts.features
Required An array of strings. Strings should be the headers of columns in the csv that should be used as features.
train.opts.classAttribute
Required A string, the header of the column to use as the class. Only binary classification is supported right now, so valid class attributes are true and false.
train.opts.regularizer
Default 0.001. How hard to try to fit the data. Passed to the SVM.
train.opts.buffer
Default false. Set to true if your data is small enough to keep entirely in memory, and training will be sped up by about 40%. If this option is true, the input option to train must be a filename.
train.opts.stepLength
Default 0.01. The learning rate. If a float, will be held constant. If a function, should have the signature function stepLength (epoch) {} where epoch is an integer, the current epoch. It should return a float, which will be used as the step length for that epoch. You can use this to decay the step length as time goes on.
train.opts.eachEpoch
Default no-op.
function eachEpoch (epoch, svm, testStream, cb) {}
- epoch - An integer, the current epoch
- svm - The SVM object
- testStream - A readable stream of instances
- cb - Call when done to continue training
train.opts.epochs
Default 1000. How many epochs to train for.
train.opts.stepPercentage
Default 0.4. The percentage of instances to use for each epoch.
train.opts.testPercentage
Default 0.3. The percentage of instances in each epoch to leave out. These instances are fed into the test stream passed to eachEpoch.
SVM
The SVM object is a support vector machine.
SVM.predict
function predict (instance) {}
Instance is an object with the same features and classAttribute as the training data. Predict returns a float representing the output of the SVM. Values greater than zero are truthy, while values smaller than zero are falsey. The magnitude of the return value is the confidence of the prediction.
SVM.cost
function cost () {}
Returns a transform stream that accepts a stream of instances and outputs a single float. The float is the result of the cost function on the input.
SVM.accuracy
function accuracy () {}
Returns a transform stream that accepts a stream of instances and outputs a single float between zero and one. The float is the percentage of instances that were correctly classified.
License
The MIT License (MIT)
Copyright (c) 2014 Ben Ng
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.