
drizzle-cube
v0.6.4
Published
Drizzle ORM-first semantic layer with Cube.js compatibility. Type-safe analytics and dashboards with SQL injection protection.
Downloads
13,623
Maintainers
 cliftonc
cliftoncReadme
Drizzle Cube
A Drizzle ORM-first semantic layer for type-safe analytics
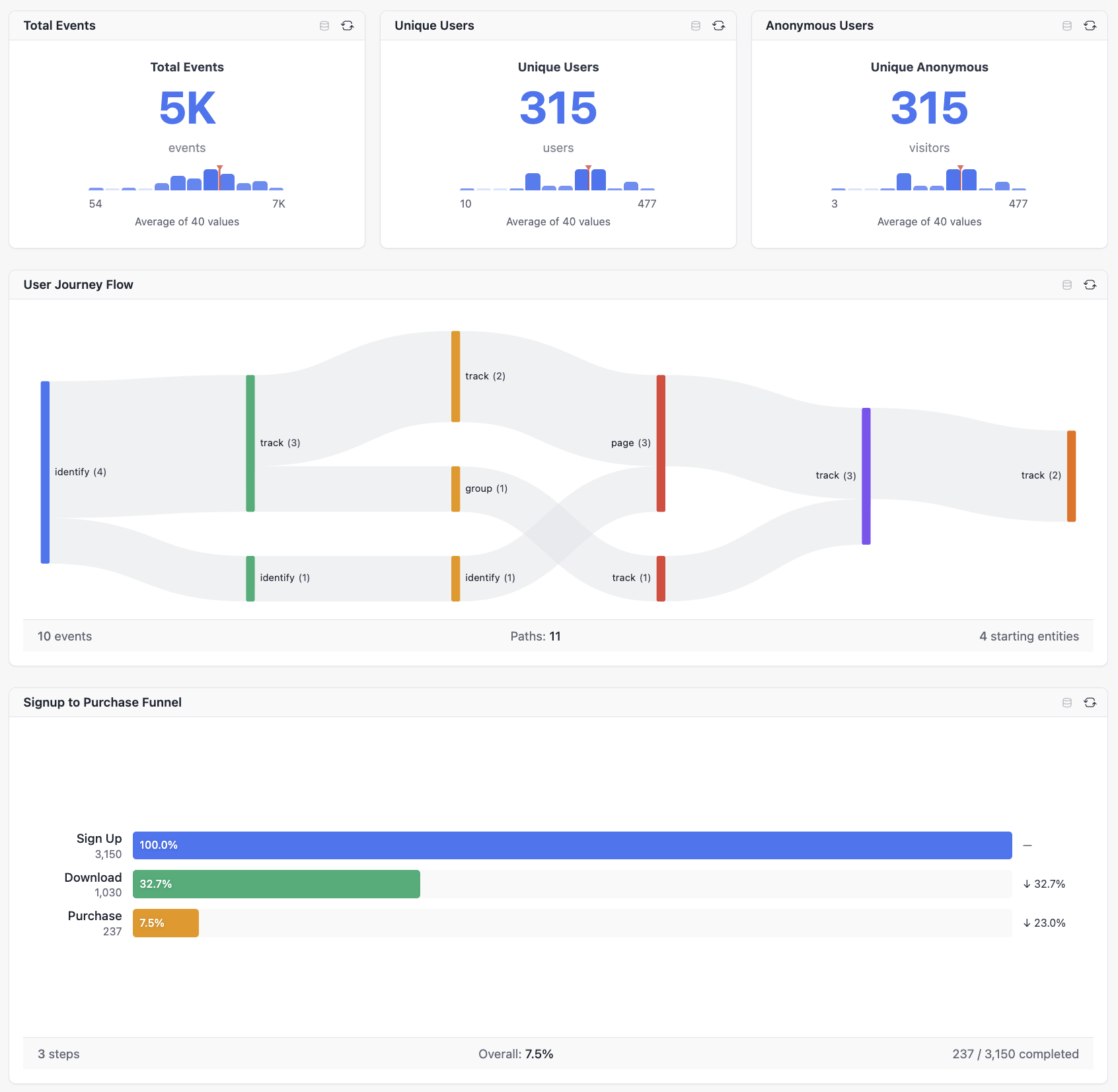
Build a semantic layer on top of your Drizzle schema. Define cubes with measures, dimensions, and joins—then query them from dashboards, AI agents, or your own code. All with full TypeScript inference and SQL injection protection.

![]()
What is a Semantic Layer?
A semantic layer sits between your database and your applications. It provides:
- Business-friendly abstractions - Define "Revenue" once, use it everywhere
- Consistent metrics - Everyone uses the same calculation for "Active Users"
- Security isolation - Multi-tenant filtering built into every query
- Self-service analytics - Users explore data without writing SQL
- Decoupling - Reports and AI agents continue to work when you change your underlying data model
Drizzle Cube brings this to the Drizzle ORM ecosystem with full type safety.
Why Drizzle Cube?
| Feature | Drizzle Cube | Raw SQL | Other BI Tools | |---------|-------------|---------|----------------| | Type Safety | Full TypeScript inference | Manual types | None | | SQL Injection | Impossible (parameterized) | Risk | Varies | | Multi-tenant | Built-in security context | Manual | Complex | | AI Integration | MCP server included | Build yourself | Limited | | Setup | Minutes | Hours | Days |
Quick Start
1. Install
npm install drizzle-cube drizzle-orm2. Define Cubes on Your Schema
import { defineCube } from 'drizzle-cube/server'
import { eq } from 'drizzle-orm'
import { employees, departments } from './schema'
export const employeesCube = defineCube('Employees', {
// Security: filter by organisation automatically
sql: (ctx) => ({
from: employees,
where: eq(employees.organisationId, ctx.securityContext.organisationId)
}),
// Define relationships for cross-cube queries
joins: {
Departments: {
targetCube: () => departmentsCube,
relationship: 'belongsTo',
on: [{ source: employees.departmentId, target: departments.id }]
}
},
measures: {
count: { type: 'count', sql: employees.id },
avgSalary: { type: 'avg', sql: employees.salary },
totalSalary: { type: 'sum', sql: employees.salary }
},
dimensions: {
name: { type: 'string', sql: employees.name },
email: { type: 'string', sql: employees.email },
hiredAt: { type: 'time', sql: employees.hiredAt }
}
})3. Create API Server
import { Hono } from 'hono'
import { createCubeApp } from 'drizzle-cube/adapters/hono'
import { employeesCube, departmentsCube } from './cubes'
const app = createCubeApp({
cubes: [employeesCube, departmentsCube],
drizzle: db,
schema,
extractSecurityContext: async (req) => ({
organisationId: req.user.orgId // Multi-tenant isolation
})
})
export default app4. Query from Anywhere
// From React components
import { AnalysisBuilder, AnalyticsDashboard } from 'drizzle-cube/client'
// From AI agents via MCP
// Connect Claude, ChatGPT, or n8n to /mcp
// From your own code
const result = await fetch('/cubejs-api/v1/load', {
method: 'POST',
body: JSON.stringify({
query: {
measures: ['Employees.count', 'Employees.avgSalary'],
dimensions: ['Departments.name']
}
})
})Analysis Modes
Drizzle Cube supports multiple analysis modes out of the box:
Query Builder (Analysis Builder)
Build ad-hoc queries with measures, dimensions, filters, and time ranges. Search-first field picker, drag-and-drop chart configuration, and multiple visualization options.
Funnel Analysis
Track conversion through multi-step processes. Define funnel steps, measure drop-off rates, and analyze time-to-convert metrics (average, median, p90).
// Funnel query example
{
analysisType: 'funnel',
steps: [
{ name: 'Signed Up', filter: { member: 'Users.status', operator: 'equals', values: ['registered'] } },
{ name: 'Activated', filter: { member: 'Users.activated', operator: 'equals', values: [true] } },
{ name: 'Subscribed', filter: { member: 'Users.plan', operator: 'notEquals', values: ['free'] } }
],
timeDimension: 'Users.createdAt',
dateRange: ['2024-01-01', '2024-12-31']
}Flow Analysis
Visualize user journeys and navigation paths through your application. Understand how users move between states or pages.
Retention Analysis
Measure user retention over time with cohort analysis. Track how many users return after their first interaction across days, weeks, or months.
Dashboards
Compose multiple charts into persistent dashboards with grid layouts, filters, and real-time updates. Save and share dashboard configurations.
AI & MCP Integration
Drizzle Cube includes a built-in MCP server that lets AI agents query your semantic layer:
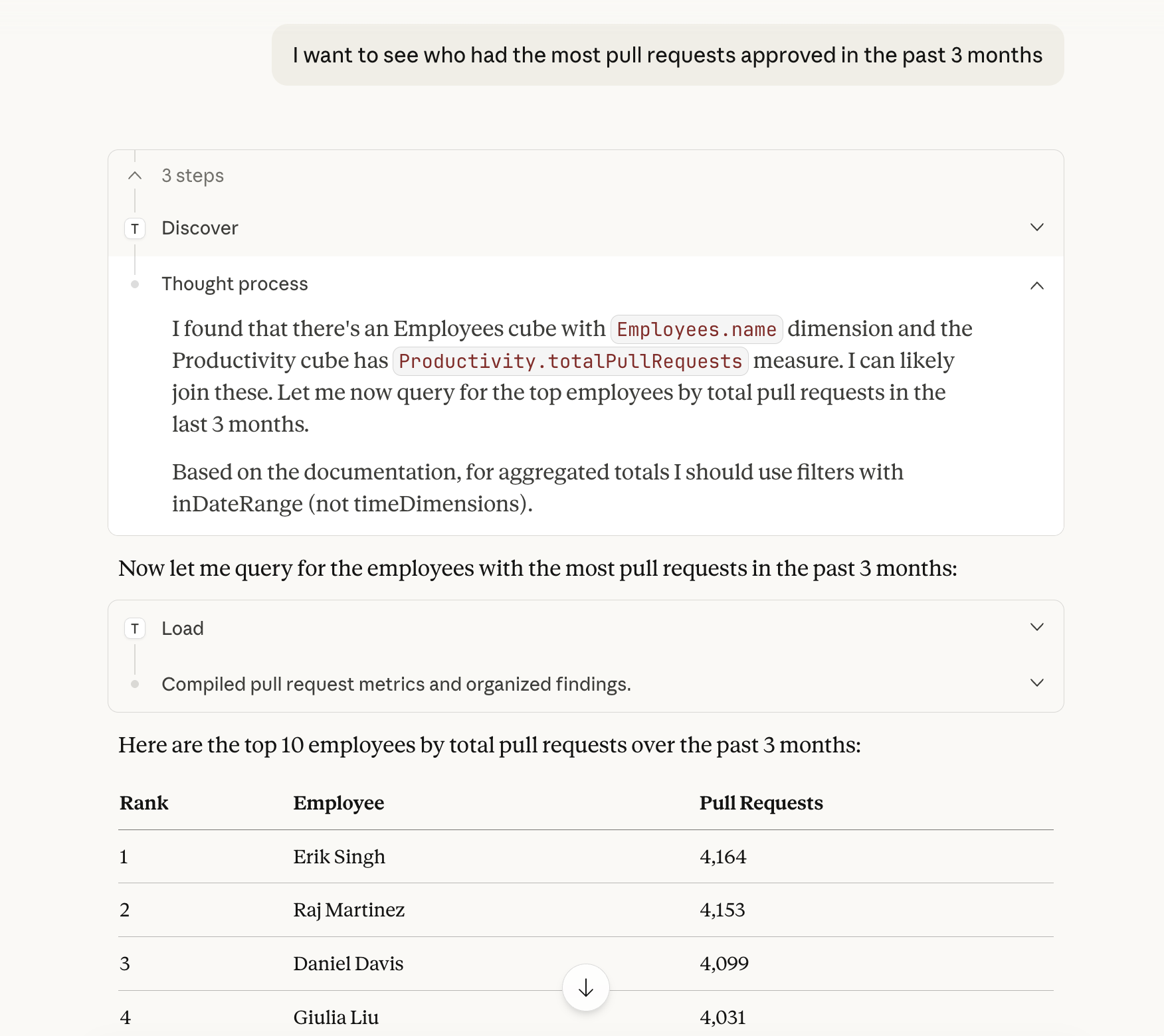
Available MCP Tools
| Tool | Purpose |
|------|---------|
| drizzle_cube_discover | Find relevant cubes by topic |
| drizzle_cube_validate | Validate queries with auto-corrections |
| drizzle_cube_load | Execute queries and return data |
| drizzle_cube_chart | Execute queries with interactive chart visualization |
Connect AI Tools
Claude Desktop - Add to claude_desktop_config.json:
{
"mcpServers": {
"analytics": {
"command": "npx",
"args": ["-y", "@anthropic/mcp-remote", "https://your-app.com/mcp"]
}
}
}Claude.ai - Settings → Connectors → Add your MCP URL
ChatGPT - Settings → Connectors → Developer Mode → Add MCP URL
n8n - Use the MCP Client node in your workflows
Learn more about AI integration →
Claude Code Plugin
Query your semantic layer with natural language directly from Claude Code:
claude /install-plugin github:cliftonc/drizzle-cube-pluginThen configure your API endpoint in .drizzle-cube.json and ask Claude things like:
- "Show me revenue by region for the last quarter"
- "Which departments have the highest average salary?"
- "Create a dashboard showing key HR metrics"
Features
Semantic Layer
- Cubes - Define measures, dimensions, and calculated fields
- Joins - belongsTo, hasOne, hasMany, belongsToMany relationships
- Security - Multi-tenant isolation via security context
- Cross-cube queries - Automatic join resolution
Modeling Note: Multi-Fact Queries
- For
FactA -> Dimension <- FactB(star/snowflake patterns), define reversehasManyjoins on the center dimension back to each fact. - Example: if
SalesandInventorybothbelongsTo Products,Productsshould definehasMany SalesandhasMany Inventory. - Why: join-path traversal is directional. Without reverse joins, the planner may not be able to pick the center dimension as the primary cube, which can lead to fan-out-prone execution plans.
- If you cannot add reverse joins immediately, include the center join key dimension (for example
Products.id) in the query grain to reduce aggregation ambiguity.
Client Components
- AnalysisBuilder - Interactive query builder with chart visualization
- AnalyticsDashboard - Configurable dashboards with grid layouts
- Chart components - Bar, line, area, pie, funnel, heatmap, and more
Framework Support
- Express, Fastify, Hono, Next.js adapters
- PostgreSQL, MySQL, SQLite, DuckDB databases
- React components with TanStack Query
Theming
Three built-in themes (light, dark, neon) with semantic CSS variables. Add custom themes without changing components.
Documentation
- Getting Started - Installation and setup
- Semantic Layer - Cubes, measures, dimensions, joins
- Client Components - React components and hooks
- AI Integration - MCP server and Claude plugin
- API Reference - Complete API documentation
Examples
- Hono Example - Cloudflare Workers compatible
- Express Example - Traditional Node.js server
- Fastify Example - High-performance server
- Next.js Example - Full-stack React
Contributing
We welcome contributions! Please see our Contributing Guide.
Query performance is benchmarked on every push to main — browse the historical trends at the Performance Dashboard.
Roadmap
View and contribute to the roadmap on GitHub Projects.
License
MIT © Clifton Cunningham
Built with ❤️ for the Drizzle ORM community
This repository is maintained with the assistance of Last Light, an automated GitHub maintenance bot that handles issue triage, pull request reviews, and routine repository upkeep.