
fask
v0.3.3
Published
NodeJS package for analysing large amount of files.
Downloads
15

Readme

NodeJS package for analysing large amount of files.
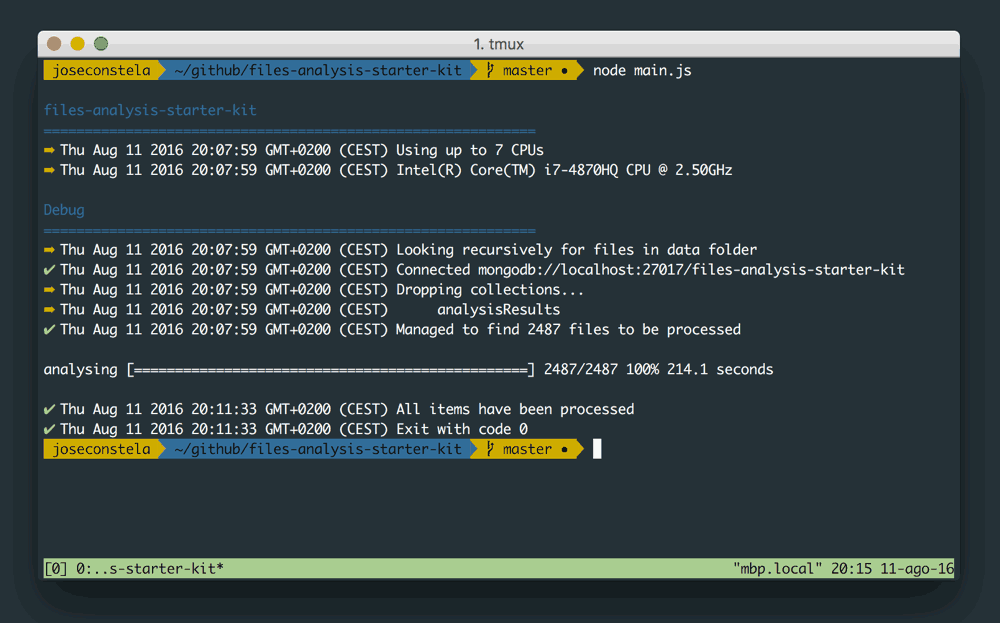
This NodeJs library searches for all files within an specific folder - recursively - and sends each file info to your processing library. It takes care of multithreading, queuing and managing database connections.
## Usage
- Require the package
$ npm install fask --save- Require it and define your analysis
const fask = require('files-analysis-starter-kit')
// Pre-analysis hook
fask.before = (dbs, callback) => { callback() }
// The actual file processing
fask.process = (dbs, fileInfo, callback) => {
setImmediate(callback)
}
// Post-analysis hook
fask.after = (dbs, callback) => { callback() }
// Launch the analysis
fask.start({...})
Options
Options for the .start method:
Parameter | Default | Description --- | --- | --- cpus | 100 | Max number of CPUs to use for concurrency limitFiles | -1 (no limit) | Limit the number or files to be processed mimeType | null (no filter) | Only path | "data" | Files location mongodb | localhost | MongoDB connection url
fileInfo
The fileInfo parameter have the following structure:
{
root: '/',
dir: '/.../files-analysis-starter-kit/data/subfolder',
base: 'myPdfFile.PDF',
ext: '.PDF',
name: 'myPdfFile',
route: '/.../files-analysis-starter-kit/data/subfolder/myPdfFile.PDF',
mime: 'application/pdf',
stats: {
dev: 16777220,
mode: 33188,
nlink: 1,
uid: 501, // user-id of the owner of the file.
gid: 20, // group-id of the owner of the file.
rdev: 0,
blksize: 4096,
ino: 29670994,
size: 68704, // Size in bytes
blocks: 136,
atime: Thu Aug 11 2016 13:30:51 GMT+0200 (CEST), // last access
mtime: Tue Apr 01 2008 08:52:56 GMT+0200 (CEST), // last modification
ctime: Tue Aug 09 2016 04:20:35 GMT+0200 (CEST), // creation
birthtime: Tue Apr 01 2008 08:52:56 GMT+0200 (CEST)
}
}Databases instances
To use the DB connections use the dbs object. i.e.:
dbs.mongo.getCollection('myCollection').insert(...)