
huanqiu-news-crawler
v1.0.0
Published
用于爬取环球网的新闻数据
Downloads
1
Maintainers
 petercheng
peterchengReadme
环球网新闻爬虫脚本(NodeJs)
目录
- start.js 可执行文件
- config.json 配置文件
- data 数据保存的文件夹 (配置后自动生成)
- news_detail.json 爬取新闻的列表数据
- news_item.json 爬取的新闻详情数据
使用
// huanqiu-crawler模块导出的是一个可执行函数
const hc = require("huanqiu-news-crawler")
hc()第一次使用,请关闭 config 的
isAutoAssignTime属性,并配置assignTime、maxScrollTop、maxNewsNumber
配置文件介绍
基本配置"rootUrl" 爬虫目标的根地址(不可更改)"newsType" 新闻类型,以及对应的链接"isPrintInfoToConsole" 是否实时打印爬虫信息"isAutoAssignTime" 是否开启自动匹配时间"isScrollAwait" 是否开启滚动延迟"isPageAwait" 是否开启页面关闭延时"scrollAwaitTime" 页面滚动延时(默认单位:ms)"pageAwaitTime" 页面关闭延时(默认单位:ms)"isSavaToFile" 是否将数据保存到文件"isSavaToDataBase" 是否将数据保存到Mysql数据库
数据配置"assignTime" 将新闻以该时间进行筛选"maxScrollTop" 最大滚动距离,相同条件下,滚动距离越大,数据获取越多(默认单位:px)"maxNewsNumber" 爬取单类新闻的最大条数
数据库配置"mysql_host" Mysql主机地址"mysql_user" Mysql登录用户名"mysql_password" Mysql登录口令"mysql_database" 链接的数据库"mysql_port" 端口号"mysql_timezone" 时区
数据表结构
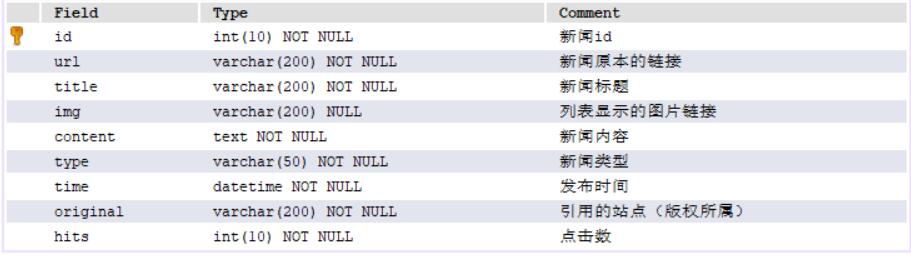
优化
优化爬虫的异步操作和流程
新增错误处理机制
实现新闻时间智能识别,按需爬取
解决了偶尔出现的未爬完数据就结束的Bug
新增了是否打印实时爬虫信息的功能