
ludion-router
v0.1.3
Published
A load balancer between your users' GPUs and your cloud — per-request routing of AI inference between on-device WebGPU and your own server, decided by a versioned, deterministic, empirically derived policy.
Maintainers
 ludion
ludionReadme
ludion
A load balancer between your users' GPUs and your cloud.
Per-request routing of AI inference — on-device (WebGPU) when the device can, server when it can't — decided by a versioned, deterministic, empirically derived policy.
![]()

![]()
Published as ludion-router on npm — the name ludion is blocked by npm's
typosquat protection against luxon; the project itself is Ludion.
The same app, three environments — each response carries its routing decision:
| desktop → local (R4) | desktop, long CJK prompt → server (R6) | iPhone → server (R3) |
|---|---|---|
| 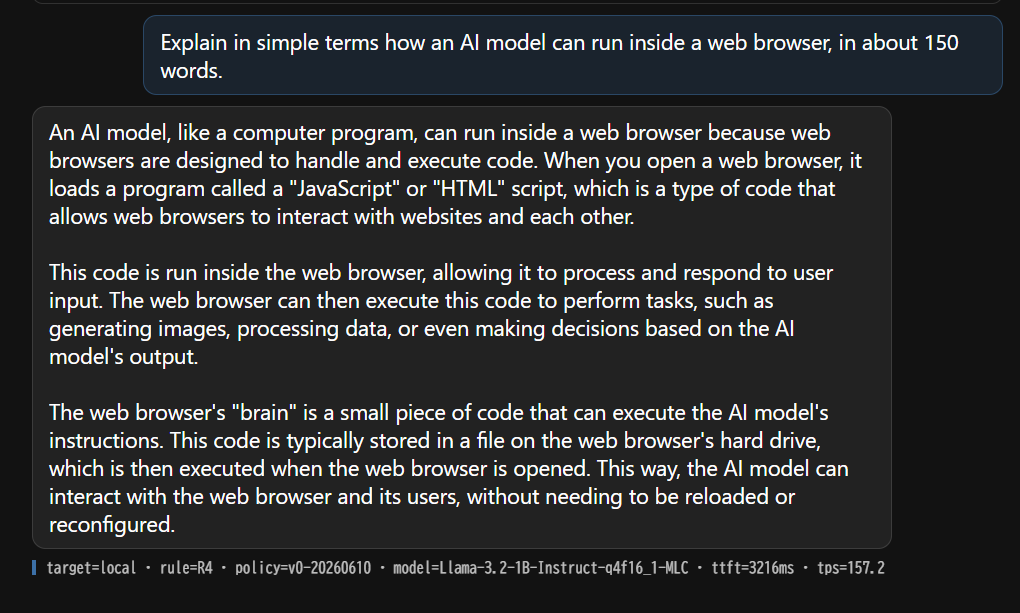 |
|  |
|  |
|
Quickstart
npm install ludion-routerZero config, zero keys — local-only mode. On a WebGPU desktop this runs entirely
on-device; on any machine without WebGPU (CI, many laptops, iOS) the policy
routes to a server, and with no fallback configured that throws a typed
LudionNoFallbackConfigured — so wrap the first call and let the catch point you
at the fallback example below:
import { Ludion } from "ludion-router";
const messages = [{ role: "user", content: "Write a haiku about the ocean." }];
try {
const ludion = await Ludion.create();
const stream = await ludion.chat.completions.create({ messages, stream: true });
let text = "";
for await (const chunk of stream) text += chunk.choices[0]?.delta?.content ?? "";
console.log(text); // ran entirely on the user's GPU
} catch (e) {
// No WebGPU + no fallback → the request routed to a server that isn't
// configured, so it throws LudionNoFallbackConfigured. Add a fallback
// (next example) to complete server-routed requests too.
console.error(e);
}To complete server-routed requests too, add a fallback. The endpoint is a small relay you host, so the API key stays in your server's environment — never in client code:
import { Ludion } from "ludion-router";
const ludion = await Ludion.create({
fallback: {
url: "/api/chat", // your relay proxy → your LLM provider (key server-side)
model: "your-server-model",
},
});
const stream = await ludion.chat.completions.create({
messages: [{ role: "user", content: "Hello!" }],
max_tokens: 256,
stream: true,
});
let text = "";
for await (const chunk of stream) text += chunk.choices[0]?.delta?.content ?? "";
console.log(stream._ludion); // the decision log: target, rule_id, policy_version, ttft_ms, tps, ...The relay is ~15 lines: copy one from
docs/recipes/
(Next.js route handler, Cloudflare Worker, or Express), or clone the
examples/next-starter/
template where it's already wired up. Any OpenAI-compatible /chat/completions
URL works as fallback.url as long as the browser can reach it (CORS —
same-origin relays sidestep this entirely).
The call shape is plain OpenAI. The only ludion-specific piece is _ludion,
the per-request decision log telling you where the request ran and which policy
rule decided it.
Build note: your bundler will flag a ~6 MB chunk — that is the
@mlc-ai/web-llmengine, which is code-split and lazy-loaded only on devices that route local. Server-routed sessions never download it, so the warning (e.g. Vite's 500 kB notice) is expected and safe to ignore.
Public API
Ludion (entry point), LudionPrivacyUnroutable / LudionMidStreamError /
LudionNoFallbackConfigured (errors), and the types DecisionLog,
PolicyTable, ModelId plus the option/response types their signatures
require. Everything else (policy evaluator, strike store, executors) is internal
and not exported.
The three typed errors cover routing/policy and mid-stream conditions. By
contrast, a network or relay HTTP failure (a missing, unreachable, or
4xx/5xx fallback endpoint) surfaces as a generic Error whose message is
prefixed ludion-router: and names the HTTP status (e.g.
ludion-router: fallback endpoint HTTP 404) — it is not a typed class, so
catch relay failures by prefix/status, not instanceof.
Fallback endpoint: browser CORS is REQUIRED
The browser calls the configured /chat/completions URL directly with fetch.
Host a small relay on your own backend (Next.js route handler / Cloudflare
Worker / Express — copy one from
docs/recipes/):
the provider key stays in your server's environment, and a same-origin relay
sidesteps CORS entirely. If you point fallback.url at a cross-origin endpoint
instead, it must allow requests from the app origin:
Access-Control-Allow-Origin, plus the authorization and content-type
request headers (preflight). A key that works from curl but not from the page is
almost always CORS.
The routing policy (and its evidence)
Policy v0-20260610 (default max_tokens 256). Rules evaluate top-down; first hardware+request match wins. Full rationales live in router/src/policy.v0.json.
| rule | target | hardware condition | request condition | privacy-eligible | rationale (first sentence) | |---|---|---|---|---|---| | R1 | server | env=webview-iab | any | no | In-app browsers stall/kill local inference regardless of hardware (LINE IAB, Pixel 8a 2026-06-10). | | R2 | server | webgpu=false | any | no | No WebGPU → no local path (WebLLM is WebGPU-only). | | R3 | server | os_class=ios-webkit | any | no | 0 successful iOS rows in Gate 0. | | R4 | local | os_class=desktop, webgpu=true | est_prompt_tokens ≤ 3000 | yes | Desktop WebGPU: 121-196 tps decode, prefill ~2.6k tps (Gate 0). | | R5 | local | os_class=android-chromium, webgpu=true | est_prompt_tokens ≤ 200, max_tokens ≤ 256, stream=true | yes | Pixel 8a: decode ~10 tps OK, prefill ~15 tps → long context unusable (77s TTFT @1.2k tok). | | R6 | server | any | any | no | Default: unknown territory routes safe. |
No other router ships its evidence: every rationale above cites the measurement that produced the rule. The full dataset and analysis live in the measurement report.
Privacy and token estimation:
privacy: truenever sends to server: it forces local where the hardware class allows it (R5 + privacy), otherwise throwsLudionPrivacyUnroutable.- Token estimate:
ceil(cjk × 1.0 + other / 4)— error bars: English +20–35% over (safe), Japanese ±15%, mixed code −10…+30%. Bias is always toward server, by design.
Degrade & strikes
stream: false→ any local failure transparently retries on server.stream: true→ transparent retry only before the first yielded token; after that the stream ends withLudionMidStreamError(degraded_failedin the log). Server-side continuation is forbidden.- Tombstone (localStorage,
ludion.router.*): a tab kill during load/generate = +1.0 strike on next boot; a caught failure = +0.5; score ≥ 1 short-circuits that model to server for 7 days (TTL configurable). Context-window-overflow errors degrade without striking.
Local engine
WebLLM 0.2.84 (pinned), dynamically imported only after a local decision —
server-routed sessions never download engine code or weights (verified against
the built dist on every publish). KV context window defaults to 4096
(localContextWindow), recorded per decision. The first local request downloads
the model; onLocalLoadProgress exposes the engine's progress so the UI never
stalls silently. Cancellation: consumer break → interruptGenerate() locally,
AbortController.abort() for server SSE.
Why this exists
Browser inference engines are commoditized (WebLLM, Transformers.js, wllama all run the same weights), but the environments they run in are fragmented: Chrome's built-in AI is desktop-only, iOS WebKit kills tabs without an error, in-app browsers report full WebGPU capability while being non-viable. The same model on the same hardware varies several-fold by engine, and a capability probe cannot predict any of it. The variance is the product: routing has to be measured, not assumed.
Policy v0 is derived from 54 archived benchmark runs across 5 device/environment configurations (desktop-chrome, iphone-11-pro-max, pixel-8a, pixel-8a-line-iab, web-windows-chrome), collected with bench/ and archived byte-for-byte in bench/results/. The aggregate is regenerated by script — no number in this README or the report is hand-typed.
Contribute a device row — two clicks
The routing table is only as good as its device coverage, and current coverage is honest but thin: one device per class, Mali-only Android, no Adreno, no 8 GB-RAM iPhone, no warm-cache mobile rows.
Open the live bench (deploying) on the device → Measure this device → Submit result. That's the whole contribution: the plan is auto-selected from the device probe, and submissions join the public dataset (CC0). Failed runs are first-class data — if the tab dies mid-bench, reopen the page and Submit is still there with the failure rows intact (those are routing data).
Curated submissions land in
bench/results/
with "source": "web-submission" provenance, and CI regenerates every table in
the README and report directly from the archived JSONs — your row becomes part
of the policy's evidence base. (Air-gapped or exotic setup? A PR adding your
downloaded JSON to bench/results/ still works — naming convention in
bench/results/README.md.)
Limitations (read before depending on this)
- Local engine = WebLLM only. No engine choice yet, although the bench data shows engine choice matters.
- Fallback = bring-your-own OpenAI-compatible endpoint (optional since
0.1.1 — without one, server-routed requests throw a typed error). The
browser calls it directly, so it must allow CORS from your origin; the
intended shape is a small relay you host
(
docs/recipes/) with the provider key in server-side env, never in client code. - Policy v0 is a 2-point interpolation in places (e.g. the Android prompt threshold sits between two measured points; the region between is unmeasured).
- Not production-hardened. v0.1.0 is a measured starting point, not a battle-tested router.
License
MIT. © 2026 Ludion-ai.