
union-subdivided-polygons
v0.9.1
Published
Efficiently union polygons that are known to have been subdivided using an algorithm such as PostGIS ST_Subdivide

Readme

Getting Started
npm install union-subdivided-polygons
const { union } = require("union-subdivided-polygons");
const collection = union(srcFeatureCollection, "_oid");The second parameter is optional. If your features were created with a property that references the id of the original feature they were split from, using this property to guide the algorithm can make the process run up to 2x faster. The San Francisco Bay example above using full resolution OSM coastline data takes 11ms on a 2015 era desktop computer.
Project Status
This project should be considered a work in progress until more test cases are added and support for interior rings is included. If you have a subdivided dataset that doesn't produce good output I will be grateful if you submit a ticket for testing.
Motivation
Subdividing large features into many smaller pieces can be a powerful technique when working with large spatial datasets. Serving these features over the network along with a spatial index can be a great way to do analysis on platforms with limited memory such as AWS Lambda or in a web browser. Just as image and vector tiles were transformative for online maps, "tiling" raw data for the web could enable exciting analytical capabilities. Similar efforts are proceeding for raster data using Cloud Optimized GeoTIFF.
The problems start when the analysis requires reassembly of the subdivided vectors, such as when clipping.
As an example, the primary use-case that drove development of this tool was a need to clip a user-drawn polygon so that all land was erased, creating an ocean zone polygon.
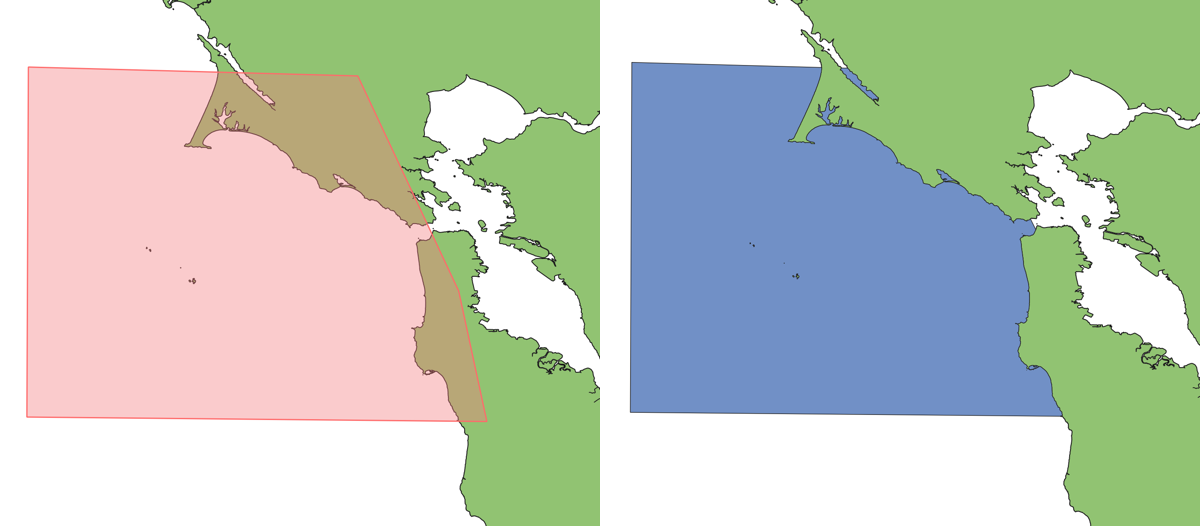
Land polygons derived from Open Street Map are ideal in that they are high resolution and available for the entire globe. Each time the process is run, just the relevant subdivided parts of the dataset are downloaded and land is erased from the user polygon. Unfortunately, doing this with tools such as Turf or martinez-polygon-clipping would produce topological errors at "tile" boundaries. Attempting to union these subdivided parts before the clipping operation produced similar results. Using a cascaded union approach improved efficiency but did not solve validity problems.
General-purpose clipping algorithms designed to work with overlapping polygons seem to be ill suited to working with geometries that share boundaries. For each vertex in a dataset they must perform complex point-in-polygon and angle comparison operations which are sensitive to floating point precision issues when comparing co-planar joints. This library takes a fundamentally different approach that takes advantages of assumptions that can be made about subdivided polygons and how they share boundaries. The task is a simple matter of joining segments where vertices match exactly and accounting for a couple particular circumstances where offset corners join. For this reason the library can perform 2 orders of magnitude faster than general purpose clipping operations and provide reliable output.
Limitations
Currently polygons with holes are poorly supported. Interior rings from subdivided features should be included in the output, but holes formed at the boundaries of subdivided features will be dropped from the output. It should be relatively straightforward to include support in a future version.
The algorithm is very sensitive to winding order. Exterior rings of input polygons should run counter-clockwise, in accordance with the GeoJSON spec. Unfortunately PostGIS functions and other tools often produce output with the opposite winding order. You can either create GeoJSON manually that adheres to this requirement or use a tool such as turf.rewind to fix it before processing.
If the input GeoJSON includes bounding box properties they will be used as a performance optimization. If they are there, they must be accurate and of the same precision as the actual coordinates or the algorithm will have trouble identifying corners.
Future Plans
A goal of this project is to facilitate spatial operations on subsets of very large datasets in a browser at 60 frames per second. The example of erasing land from polygons mentioned above could then be performed interactively as the user digitizes an input polygon, fetching data as the area of interest increases. This may require further optimization to perform the reassembly and clipping within 16ms.
Right now a single union operation is supported where all steps are performed in a single run, but an "online" version of the algorithm could be used which breaks down the steps involved. The process of segmenting pieces from input features is the most computationally intensive step. Afterwards, the polygonizing step of line following and vertex matching is quite fast. Expect a future revision of this library to expose both stages as seperate steps with tools to add and remove segments from an index before running the polygonize process, enabling even better performance when repeatedly accessing a dataset at different scales.
Running Tests and Scripts
The tests and debugging scripts use a postgis database to verify the validity of outputs. A docker-compose file is provided in scripts, and with Docker installed starting the database is a simple matter of:
cd scripts/
docker-compose up -d
# detached. `docker-compose` down to stopRun tests with npm test. They take some time as shipping all the features to the database for st_isvalid tests is slow.
Debugging scripts are provided under scripts. To run all examples, use node scripts/runExamples.js, or run specific examples with node scripts/debugExample.js examples/SoCal-Bight.geojson. In both cases, lots of useful artifacts will be output into the postgres database and scripts/qgis-project.qgz has them loaded with good default symbology. These scripts assume the database in docker-compose.yml is available, but if you are running with different connection parameters you can run tests and scripts with a DB environment variable set to a custom connection string.