
universalintelligence
v1.2.0
Published
Universal Intelligence Protocols and Community Components


Readme

This page aims to document Python protocols and usage (e.g. cloud, desktop).
Looking for Javascript/Typescript instructions?
Overview
Universal Intelligence (aka UIN) aims to make AI development accessible to everyone through a simple interface, which can optionally be customized to grow with you as you learn, up to production readiness.
It provides both a standard protocol, and a library of components implementating the protocol for you to get started —on any platform  .
.
🧩 AI made simple. Bluera Inc.
Learn more by clicking the most appropriate option for you:
Welcome! Before jumping into what this project is, let's start with the basics.
What is an agentic app?
Agentics apps are applications which use AI. They typically use pretrained models, or agents, to interact with the user and/or achieve tasks.
What is a model?
Models are artificial brains, or neural networks in coding terms. 🧠
They can think, but they can't act without being given the appropriate tools for the job. They are trained to produce a specific output, given a specific input. These can be of any type (often called modalities —eg. text, audio, image, video).
What is a tool?
Tools are scripted tasks, or functions in coding terms. 🔧
They can't think, but they can be used to achieve a pre-defined task (eg. executing a script, making an API call, interacting with a database).
What is an agent?
Agents are robots, or simply put, models and tools connected together. 🤖
🤖 = 🧠 + [🔧, 🔧,..]
They can think and act. They typically use a model to decompose a task into a list of actions, and use the appropriate tools to perform these actions.
What is ⚪ Universal Intelligence?
UIN is a protocol aiming to standardize, simplify and modularize these fundamental AI components (ie. models, tools and agents), for them to be accessible to any developer, and distributed on any platform.
It provides three specifications: Universal Model, Universal Tool, and Universal Agent.
UIN also provides a set of ready-made components and playgrounds for you to get familiar with the protocol and start building in seconds.
Universal Intelligence can be used across all platforms (cloud, desktop, web, mobile).
Universal Intelligence standardizes, simplifies and modularizes the usage and distribution of artifical intelligence, for it to be accessible by any developers, and distributed on any platform.
It aims to be a framework-less agentic protocol, removing the need for proprietary frameworks (eg. Langchain, Google ADK, Autogen, CrewAI) to build simple, portable and composable intelligent applications.
It does so by standardizing the fundamental building blocks used to make an intelligent application (models, tools, agents), which agentic frameworks typically (re)define and build upon —and by ensuring these blocks can communicate and run on any hardware (model, size, and precision dynamically set; agents share resources).
It provides three specifications: Universal Model, Universal Tool, and Universal Agent.
This project also provides a set of community-built components and playgrounds, implementing the UIN specification, for you to get familiar with the protocol and start building in seconds.
Universal Intelligence protocols and components can be used across all platforms (cloud, desktop, web, mobile).
Agentic Framework vs. Agentic Protocol
How do they compare?
Agent frameworks (like Langchain, Google ADK, Autogen, CrewAI), each orchestrate their own versions of so-called building blocks. Some of them implement the building blocks themselves, others have them built by the community.
UIN hopes to standardize those building blocks and remove the need for a framework to run/orchestrate them. It also adds a few cool features to these blocks like portability. For example, UIN models are designed to automatically detect the current hardware (cuda, mps, webgpu), its available memory, and run the appropriate quantization and engine for it (eg. transformers, llama.cpp, mlx, web-llm). It allows developers not to have to implement different stacks to support different devices when running models locally, and (maybe more importantly) not to have to know or care about hardware compatibility, so long as they don't try to run a rocket on a gameboy 🙂
Get Started
An online Google Colab Playground is now available to help introduce you to making AI applications using Universal Intelligence! ⚡
Get familiar with the composable building blocks, using the default community components.
# Choose relevant install for your device
pip install "universal-intelligence[community,mps]" # Apple
pip install "universal-intelligence[community,cuda]" # NVIDIA
# Log into Hugging Face CLI so you can download models
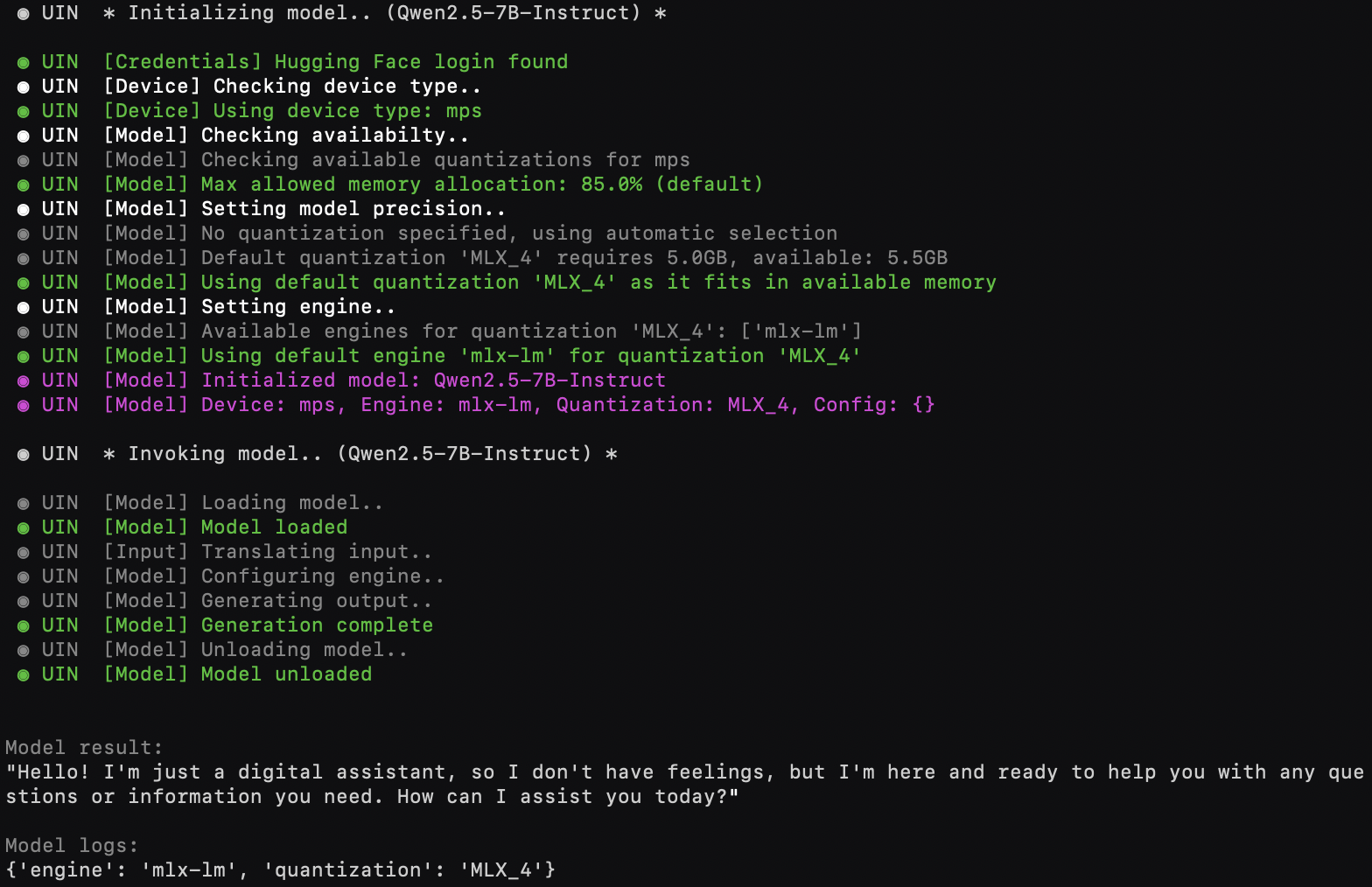
huggingface-cli login🧠 Simple model
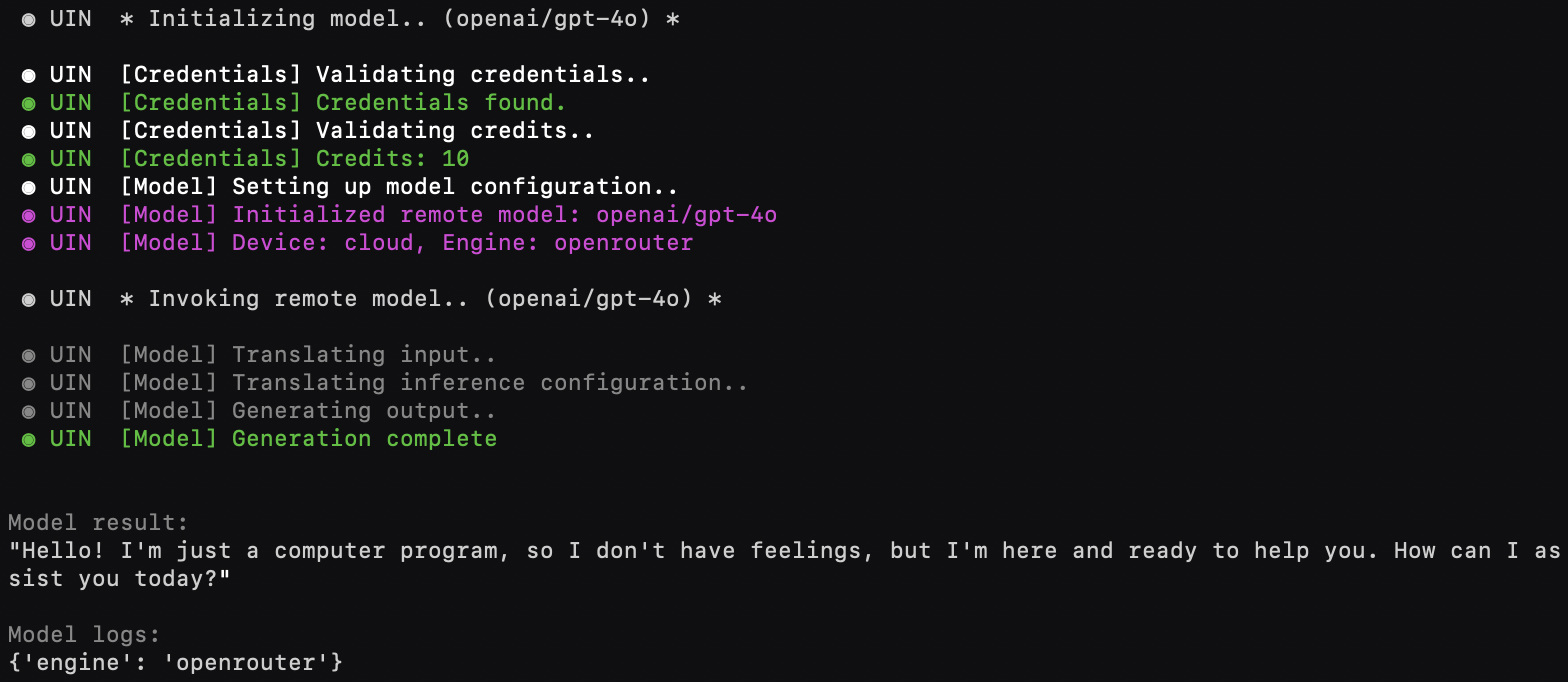
from universal_intelligence import Model # (or in the cloud) RemoteModel [free], PaidRemoteModel [paid, higher perf]
model = Model() # (or in the cloud) RemoteModel(credentials='openrouter-api-key')
result, logs = model.process("Hello, how are you?")Models may run locally or in the cloud.
See Documentation>Community Components>Remote Models for details.
Preview:
- Local Model
- Remote Model (cloud-based)
🔧 Simple tool
from universal_intelligence import Tool
tool = Tool()
result, logs = tool.print_text("This needs to be printed")Preview:

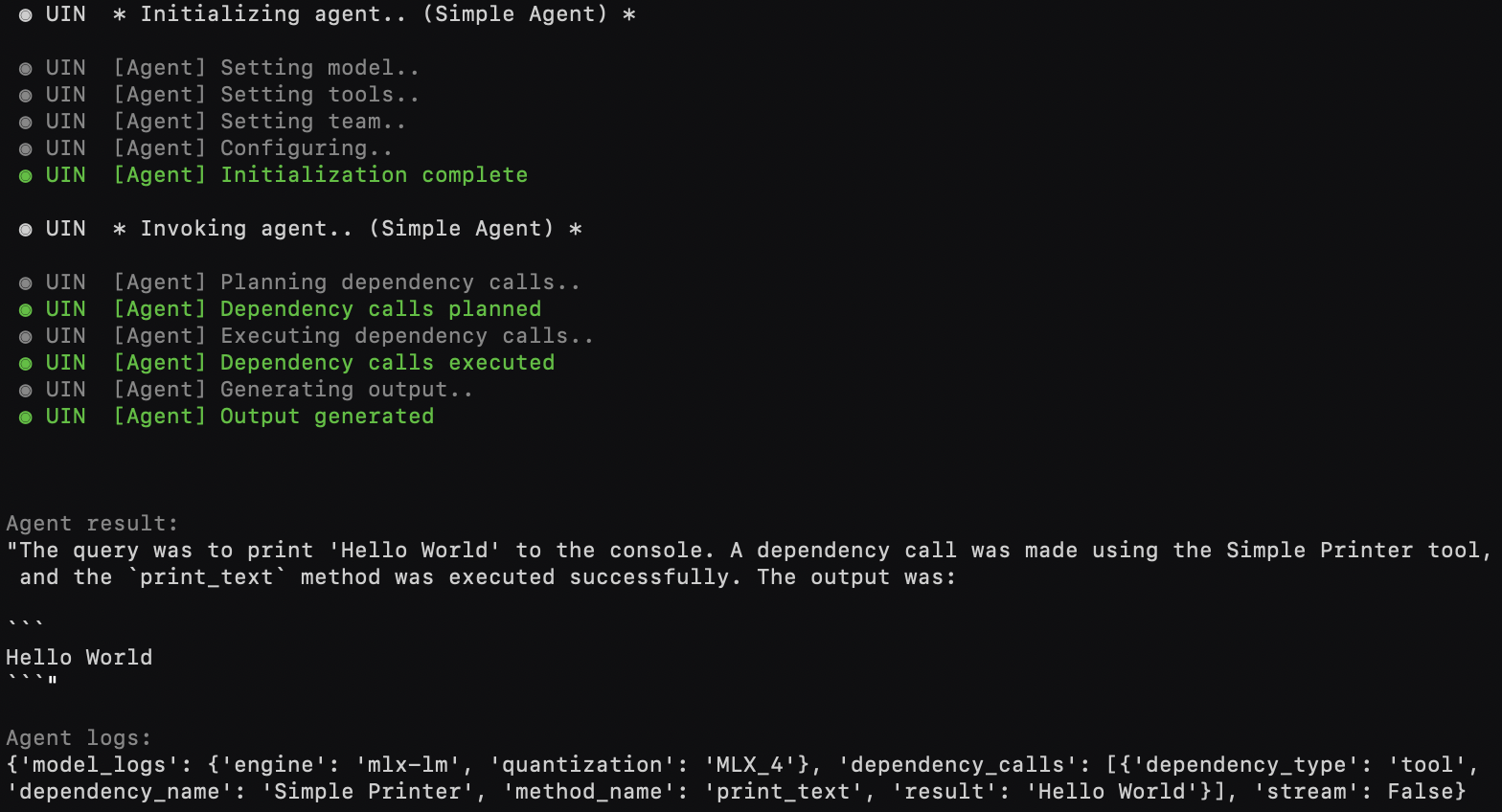
🤖 Simple agent (🧠 + 🔧)
from universal_intelligence import Model, Tool, Agent, OtherAgent
agent = Agent(
# model=Model(), # customize or share 🧠 across [🤖,🤖,🤖,..]
# expand_tools=[Tool()], # expand 🔧 set
# expand_team=[OtherAgent()] # expand 🤖 team
)
result, logs = agent.process("Please print 'Hello World' to the console", extra_tools=[Tool()])Preview:
Playground
Online
An online Google Colab Playground is now available!
Local
A ready-made playground is also available locally to help familiarize yourself with the protocols and components.
python -m playground.example Documentation
Would you rather chat with our docs? 💬
Note: AI responses may include mistakes. Refer to the documentation below for sample code.
Protocol Specifications
Universal Model
A ⚪ Universal Model is a standardized, self-contained and configurable interface able to run a given model, irrespective of the consumer hardware and without requiring domain expertise.
It embeddeds a model (i.e. hosted, fetched, or local), one or more engines (e.g. transformers, lama.cpp, mlx-lm, web-llm), runtime dependencies for each device type (e.g. CUDA, MPS), and exposes a standard interface.
While configurable, every aspect is preset for the user, based on automatic device detection and dynamic model precision, in order to abstract complexity and provide a simplified and portable interface.
Providers: In the intent of preseting a
Universal Modelfor non-technical mass adoption, we recommend defaulting to 4 bit quantization.
Universal Tool
A ⚪ Universal Tool is a standardized tool interface, usable by any Universal Agent.
Tools allow interacting with other systems (e.g. API, database) or performing scripted tasks.
When
Universal Toolsrequire accessing remote services, we recommend standardizing those remote interfaces as well using MCP Servers, for greater portability. Many MCP servers have already been shared with the community and are ready to use, see available MCP servers for details.
Universal Agent
A ⚪ Universal Agent is a standardized, configurable and composable agent, powered by a Universal Model, Universal Tools and other Universal Agents.
While configurable, every aspect is preset for the user, in order to abstract complexity and provide a simplified and portable interface.
Through standardization, Universal Agent can seemlessly and dynamically integrate with other Universal Intelligence components to achieve any task, and/or share hardware recources (i.e. sharing a common Universal Model) —allowing it to generalize and scale at virtually no cost.
When
Universal Agentsrequire accessing remote agents, we recommend leveraging Google's A2A Protocols, for greater compatibility.
In simple terms:
Universal Model = 🧠
Universal Tool = 🔧
Universal Agent = 🤖
🤖 = 🧠 + [🔧, 🔧,..] + [🤖, 🤖,..]
Usage
Universal Model
from <provider> import UniversalModel as Model
model = Model()
output, logs = model.process('How are you today?') # 'Feeling great! How about you?'Automatically optimized for any supported device 🔥
Customization Options
Simple does not mean limited. Most advanted configuration options remain available.
Those are defined by and specific to the universal model provider.
We encourage providers to use industry standard Hugging Face Transformers specifications, irrespective of the backend internally used for the detected device and translated accordingly, allowing for greater portability and adoption.
Optional Parameters
from <provider> import UniversalModel as Model
model = Model(
credentials='<token>', # (or) object containing credentials eg. { id: 'example', passkey: 'example' }
engine='transformers', # (or) ordered by priority ['transformers', 'llama.cpp']
quantization='BNB_4', # (or) ordered by priority ['Q4_K_M', 'Q8_0'] (or) auto in range {'default': 'Q4_K_M', 'min_precision': '4bit', 'max_precision': '8bit'}
max_memory_allocation=0.8, # maximum allowed memory allocation in percentage
configuration={
# (example)
# "processor": {
# e.g. Tokenizer https://huggingface.co/docs/transformers/fast_tokenizers
#
# model_max_length: 4096,
# model_input_names: ['token_type_ids', 'attention_mask']
# ...
# },
# "model": {
# e.g. AutoModel https://huggingface.co/docs/transformers/models
#
# torch_dtype: "auto"
# device_map: "auto"
# ...
# }
},
verbose=True # or string describing log level
)
output, logs = model.process(
input=[
{
"role": "system",
"content": "You are a helpful model to recall schedules."
},
{
"role": "user",
"content": "What did I do in May?"
},
], # multimodal
context=["May: Went to the Cinema", "June: Listened to Music"], # multimodal
configuration={
# (example)
# e.g. AutoModel Generate https://huggingface.co/docs/transformers/llm_tutorial
#
# max_new_tokens: 2000,
# use_cache: True,
# temperature: 1.0
# ...
},
remember=True, # remember this interaction
stream=False, # stream output asynchronously
keep_alive=True # keep model loaded after processing the request
) # 'In May, you went to the Cinema.'Optional Methods
from <provider> import UniversalModel as Model
model = Model()
# Optional
model.load() # loads the model in memory (otherwise automatically loaded/unloaded on execution of `.process()`)
model.loaded() # checks if model is loaded
model.unload() # unloads the model from memory (otherwise automatically loaded/unloaded on execution of `.process()`)
model.reset() # resets remembered chat history
model.configuration() # gets current model configuration
# Class Optional
Model.contract() # Contract
Model.compatibility() # Compatibility Universal Tool
from <provider> import UniversalTool as Tool
tool = Tool(
# configuration={ "any": "configuration" },
# verbose=False
)
result, logs = tool.example_task(example_argument=data)Optional Methods
from <provider> import UniversalTool as Tool
# Class Optional
Tool.contract() # Contract
Tool.requirements() # Configuration Requirements Universal Agent
from <provider> import UniversalAgent as Agent
agent = Agent(
# (optionally composable)
#
# model=Model(),
# expand_tools=[Tool()],
# expand_team=[OtherAgent()]
)
output, logs = agent.process('What happened on Friday?') # > (tool call) > 'Friday was your birthday!'Modular, and automatically optimized for any supported device 🔥
Customization Options
Most advanted configuration options remain available.
Those are defined by and specific to the universal model provider.
We encourage providers to use industry standard Hugging Face Transformers specifications, irrespective of the backend internally used for the detected device and translated accordingly, allowing for greater portability and adoption.
Optional Parameters
from <provider.agent> import UniversalAgent as Agent
from <provider.other_agent> import UniversalAgent as OtherAgent
from <provider.model> import UniversalModel as Model
from <provider.tool> import UniversalTool as Tool # e.g. API, database
# This is where the magic happens ✨
# Standardization of all layers make agents composable and generalized.
# They can now utilize any 3rd party tools or agents on the fly to achieve any tasks.
# Additionally, the models powering each agent can now be hot-swapped so that
# a team of agents shares the same intelligence(s), thus removing hardware overhead,
# and scaling at virtually no cost.
agent = Agent(
credentials='<token>', # (or) object containing credentials eg. { id: 'example', passkey: 'example' }
model=Model(), # see Universal Model API for customizations
expand_tools=[Tool()], # see Universal Tool API for customizations
expand_team=[OtherAgent()], # see Universal Agent API for customizations
configuration={
# agent configuration (eg. guardrails, behavior, tracing)
},
verbose=True # or string describing log level
)
output, logs = agent.process(
input=[
{
"role": "system",
"content": "You are a helpful model to recall schedules and set events."
},
{
"role": "user",
"content": "Can you schedule what we did in May again for the next month?"
},
], # multimodal
context=['May: Went to the Cinema', 'June: Listened to Music'], # multimodal
configuration={
# (example)
# e.g. AutoModel Generate https://huggingface.co/docs/transformers/llm_tutorial
#
# max_new_tokens: 2000,
# use_cache: True,
# temperature: 1.0
# ...
},
remember=True, # remember this interaction
stream=False, # stream output asynchronously
extra_tools=[Tool()], # extra tools available for this inference; call `agent.connect()` link during initiation to persist them
extra_team=[OtherAgent()], # extra agents available for this inference; call `agent.connect()` link during initiation to persist them
keep_alive=True # keep model loaded after processing the request
)
# > "In May, you went to the Cinema. Let me check the location for you."
# > (tool call: database)
# > "It was in Hollywood. Let me schedule a reminder for next month."
# > (agent call: scheduler)
# > "Alright you are all set! Hollywood cinema is now scheduled again in July."Optional Methods
from <provider.agent> import UniversalAgent as Agent
from <provider.other_agent> import UniversalAgent as OtherAgent
from <provider.model> import UniversalModel as Model
from <provider.tool> import UniversalTool as Tool # e.g. API, database
agent = Agent()
other_agent = OtherAgent()
tool = Tool()
# Optional
agent.load() # loads the agent's model in memory (otherwise automatically loaded/unloaded on execution of `.process()`)
agent.loaded() # checks if agent is loaded
agent.unload() # unloads the agent's model from memory (otherwise automatically loaded/unloaded on execution of `.process()`)
agent.reset() # resets remembered chat history
agent.connect(tools=[tool], agents=[other_agent]) # connects additionnal tools/agents
agent.disconnect(tools=[tool], agents=[other_agent]) # disconnects tools/agents
# Class Optional
Agent.contract() # Contract
Agent.requirements() # Configuration Requirements
Agent.compatibility() # Compatibility API
Universal Model
A self-contained environment for running AI models with standardized interfaces.
| Method | Parameters | Return Type | Description |
|--------|------------|-------------|-------------|
| __init__ | • credentials: str \| Dict = None: Authentication information (e.g. authentication token (or) object containing credentials such as { id: 'example', passkey: 'example' })• engine: str \| List[str] = None: Engine used (e.g., 'transformers', 'llama.cpp', (or) ordered by priority ['transformers', 'llama.cpp']). Prefer setting quantizations over engines for broader portability.• quantization: str \| List[str] \| QuantizationSettings = None: Quantization specification (e.g., 'Q4_K_M', (or) ordered by priority ['Q4_K_M', 'Q8_0'] (or) auto in range {'default': 'Q4_K_M', 'min_precision': '4bit', 'max_precision': '8bit'})• max_memory_allocation: float = None: Maximum allowed memory allocation in percentage• configuration: Dict = None: Configuration for model and processor settings• verbose: bool \| str = "DEFAULT": Enable/Disable logs, or set a specific log level | None | Initialize a Universal Model |
| process | • input: Any \| List[Message]: Input or input messages• context: List[Any] = None: Context items (multimodal supported)• configuration: Dict = None: Runtime configuration• remember: bool = False: Whether to remember this interaction. Please be mindful of the available context length of the underlaying model.• stream: bool = False: Stream output asynchronously• keep_alive: bool = None: Keep model loaded for faster consecutive interactions | Tuple[Any, Dict] | Process input through the model and return output and logs. The output is typically the model's response and the logs contain processing metadata |
| load | None | None | Load model into memory |
| loaded | None | bool | Check if model is currently loaded in memory |
| unload | None | None | Unload model from memory |
| reset | None | None | Reset model chat history |
| configuration | None | Dict | Get current model configuration |
| (class).contract | None | Contract | Model description and interface specification |
| (class).compatibility | None | List[Compatibility] | Model compatibility specification |
Universal Tool
A standardized interface for tools that can be used by models and agents.
| Method | Parameters | Return Type | Description |
|--------|------------|-------------|-------------|
| __init__ | • configuration: Dict = None: Tool configuration including credentials | None | Initialize a Universal Tool |
| (class).contract | None | Contract | Tool description and interface specification |
| (class).requirements | None | List[Requirement] | Tool configuration requirements |
Additional methods are defined by the specific tool implementation and documented in the tool's contract.
Any tool specific method must return a tuple[Any, dict], respectively (result, logs).
Universal Agent
An AI agent powered by Universal Models and Tools with standardized interfaces.
| Method | Parameters | Return Type | Description |
|--------|------------|-------------|-------------|
| __init__ | • credentials: str \| Dict = None: Authentication information (e.g. authentication token (or) object containing credentials such as { id: 'example', passkey: 'example' })• model: UniversalModel = None: Model powering this agent• expand_tools: List[UniversalTool] = None: Tools to connect• expand_team: List[UniversalAgent] = None: Other agents to connect• configuration: Dict = None: Agent configuration (eg. guardrails, behavior, tracing)• verbose: bool \| str = "DEFAULT": Enable/Disable logs, or set a specific log level | None | Initialize a Universal Agent |
| process | • input: Any \| List[Message]: Input or input messages• context: List[Any] = None: Context items (multimodal)• configuration: Dict = None: Runtime configuration• remember: bool = False: Remember this interaction. Please be mindful of the available context length of the underlaying model.• stream: bool = False: Stream output asynchronously• extra_tools: List[UniversalTool] = None: Additional tools• extra_team: List[UniversalAgent] = None: Additional agents• keep_alive: bool = None: Keep underlaying model loaded for faster consecutive interactions | Tuple[Any, Dict] | Process input through the agent and return output and logs. The output is typically the agent's response and the logs contain processing metadata including tool/agent calls |
| load | None | None | Load agent's model into memory |
| loaded | None | bool | Check if the agent's model is currently loaded in memory |
| unload | None | None | Unload agent's model from memory |
| reset | None | None | Reset agent's chat history |
| connect | • tools: List[UniversalTool] = None: Tools to connect• agents: List[UniversalAgent] = None: Agents to connect | None | Connect additional tools and agents |
| disconnect | • tools: List[UniversalTool] = None: Tools to disconnect• agents: List[UniversalAgent] = None: Agents to disconnect | None | Disconnect tools and agents |
| (class).contract | None | Contract | Agent description and interface specification |
| (class).requirements | None | List[Requirement] | Agent configuration requirements |
| (class).compatibility | None | List[Compatibility] | Agent compatibility specification |
Data Structures
Message
| Field | Type | Description |
|-------|------|-------------|
| role | str | The role of the message sender (e.g., "system", "user") |
| content | Any | The content of the message (multimodal supported) |
Schema
| Field | Type | Description |
|-------|------|-------------|
| maxLength | Optional[int] | Maximum length constraint |
| minLength | Optional[int] | Maximum length constraint |
| pattern | Optional[str] | Pattern constraint |
| nested | Optional[List[Argument]] | Nested argument definitions for complex types |
| properties | Optional[Dict[str, Schema]] | Property definitions for object types |
| items | Optional[Schema] | Schema for array items |
Expandable as needed
Argument
| Field | Type | Description |
|-------|------|-------------|
| name | str | Name of the argument |
| type | str | Type of the argument |
| schema | Optional[Schema] | Schema constraints |
| description | str | Description of the argument |
| required | bool | Whether the argument is required |
Output
| Field | Type | Description |
|-------|------|-------------|
| type | str | Type of the output |
| description | str | Description of the output |
| required | bool | Whether the output is required |
Method
| Field | Type | Description |
|-------|------|-------------|
| name | str | Name of the method |
| description | str | Description of the method |
| arguments | List[Argument] | List of method arguments |
| outputs | List[Output] | List of method outputs |
| asynchronous | Optional[bool] | Whether the method is asynchronous (default: False) |
Contract
| Field | Type | Description |
|-------|------|-------------|
| name | str | Name of the contract |
| description | str | Description of the contract |
| methods | List[Method] | List of available methods |
When describing a Universal Model, we encourage providers to document core information such as parameter counts and context sizes.
Requirement
| Field | Type | Description |
|-------|------|-------------|
| name | str | Name of the requirement |
| type | str | Type of the requirement |
| schema | Schema | Schema constraints |
| description | str | Description of the requirement |
| required | bool | Whether the requirement is required |
Compatibility
| Field | Type | Description |
|-------|------|-------------|
| engine | str | Supported engine |
| quantization | str | Supported quantization |
| devices | List[str] | List of supported devices |
| memory | float | Required memory in GB |
| dependencies | List[str] | Required software dependencies |
| precision | int | Precision in bits |
QuantizationSettings
| Field | Type | Description |
|-------|------|-------------|
| default | Optional[str] | Default quantization to use (e.g., 'Q4_K_M'), otherwise using defaults set in sources.yaml |
| min_precision | Optional[str] | Minimum precision requirement (e.g., '4bit'). Default: Lowest between 4 bit and the default's precision if explicitly provided. |
| max_precision | Optional[str] | Maximum precision requirement (e.g., '8bit'). Default: 8 bit or the default's precision if explicitly provided. |
Expandable as needed
Development
Abstract classes and types for Universal Intelligence components are made available by the package if you wish to develop and publish your own.
# Install abstracts
pip install universal-intelligencefrom universal_intelligence.core import AbstractUniversalModel, AbstractUniversalTool, AbstractUniversalAgent, types
class UniversalModel(AbstractUniversalModel):
# ...
pass
class UniversalTool(AbstractUniversalTool):
# ...
pass
class UniversalAgent(AbstractUniversalAgent):
# ...
passIf you wish to contribute to community based components, mixins are made available to allow quickly bootstrapping new Universal Models.
See Community>Development section below for additional information.
Community Components
The universal-intelligence package provides several community-built models, agents, and tools that you can use out of the box.
Installation
# Install with device optimizations
pip install "universal-intelligence[community,mps]" # Apple
pip install "universal-intelligence[community,cuda]" # NVIDIASome components may require additional dependencies. These can be installed on demand.
# Install MCP specific dependencies
pip install "universal-intelligence[community,mps,mcp]" # Apple
pip install "universal-intelligence[community,cuda,mcp]" # NVIDIASome of the community components interface with gated models, in which case you may have to accept the model's terms on Hugging Face and log into that approved account.
You may do so in your terminal using
huggingface-cli loginor in your code:
from huggingface_hub import login login()
Playground
You can get familiar with the library using our ready-made playground
python -m playground.example or online using our Google Colab Playground!
Usage
Local Models
from universal_intelligence.community.models.local.default import UniversalModel as Model
model = Model()
output, logs = model.process("How are you doing today?")View Universal Intelligence Protocols for additional information.
Remote Models
from universal_intelligence.community.models.remote.default import UniversalModel as Model # (or) .default__free
model = Model(credentials='your-openrouter-api-key-here')
output, logs = model.process("How are you doing today?")View Universal Intelligence Protocols for additional information.
Tools
from universal_intelligence.community.tools.simple_printer import UniversalTool as Tool
tool = Tool()
result, logs = tool.print_text("This needs to be printed")View Universal Intelligence Protocols for additional information.
Agents
from universal_intelligence.community.agents.default import UniversalAgent as Agent
agent = Agent(
# model=Model(), # customize or share 🧠 across [🤖,🤖,🤖,..]
# expand_tools=[Tool()], # expand 🔧 set
# expand_team=[OtherAgent()] # expand 🤖 team
)
result, logs = agent.process("Please print 'Hello World' to the console", extra_tools=[Tool()])View Universal Intelligence Protocols for additional information.
Supported Components
Models
Local Models
Import path:
universal_intelligence.community.models.local.<import>(eg. universal_intelligence.community.models.local.default)
| I/O | Name | Import | Description | Supported Configurations |
|------|------|------|-------------|-----------|
| Text/Text | Qwen2.5-7B-Instruct (default)| default or qwen2_5_7b_instruct | Small powerful model by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-32B-Instruct | qwen2_5_32b_instruct | Large powerful model by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-14B-Instruct | qwen2_5_14b_instruct | Medium powerful model by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-14B-Instruct-1M | qwen2_5_14b_instruct_1m | Medium powerful model with 1M context by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-7B-Instruct-1M | qwen2_5_7b_instruct_1m | Small powerful model with 1M context by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-3B-Instruct | qwen2_5_3b_instruct | Compact powerful model by Alibaba Cloud | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Qwen2.5-1.5B-Instruct | qwen2_5_1d5b_instruct | Ultra-compact powerful model by Alibaba Cloud | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-27b-it | gemma3_27b_it | Large powerful model by Google | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:Q4_K_M:llama.cppcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-12b-it | gemma3_12b_it | Medium powerful model by Google | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-4b-it | gemma3_4b_it | Small powerful model by Google | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | gemma-3-1b-it | gemma3_1b_it | Ultra-compact powerful model by Google | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:bfloat16:transformerscpu:bfloat16:transformers |
| Text/Text | falcon-3-10b-instruct | falcon3_10b_instruct | Medium powerful model by TII | Supported ConfigurationsDefault:cuda:AWQ_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | falcon-3-7b-instruct | falcon3_7b_instruct | Small powerful model by TII | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:Q4_K_M:llama.cppcpu:Q4_K_M:llama.cpp |
| Text/Text | falcon-3-3b-instruct | falcon3_3b_instruct | Compact powerful model by TII | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:bfloat16:transformerscpu:bfloat16:transformers |
| Text/Text | Llama-3.3-70B-Instruct | llama3_3_70b_instruct | Large powerful model by Meta | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.1-8B-Instruct | llama3_1_8b_instruct | Small powerful model by Meta | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.2-3B-Instruct | llama3_2_3b_instruct | Compact powerful model by Meta | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | Llama-3.2-1B-Instruct | llama3_2_1b_instruct | Ultra-compact powerful model by Meta | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:bfloat16:transformerscpu:Q4_K_M:llama.cpp |
| Text/Text | phi-4 | phi4 | Small powerful model by Microsoft | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | phi-4-mini-instruct | phi4_mini_instruct | Compact powerful model by Microsoft | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-1.7b-instruct | smollm2_1d7b_instruct | Small powerful model by SmolLM | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-360m-instruct | smollm2_360m_instruct | Ultra-compact powerful model by SmolLM | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:MLX_8:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | smollm2-135m-instruct | smollm2_135m_instruct | Ultra-compact powerful model by SmolLM | Supported ConfigurationsDefault:cuda:bfloat16:transformersmps:MLX_8:mlxcpu:bfloat16:transformers |
| Text/Text | mistral-7b-instruct-v0.3 | mistral_7b_instruct_v0d3 | Small powerful model by Mistral | Supported ConfigurationsDefault:cuda:Q4_K_M:llama.cppmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | mistral-nemo-instruct-2407 | mistral_nemo_instruct_2407 | Small powerful model by Mistral | Supported ConfigurationsDefault:cuda:AWQ_4:transformersmps:MLX_3:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | OpenR1-Qwen-7B | openr1_qwen_7b | Medium powerful model by Open R1 | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
| Text/Text | QwQ-32B | qwq_32b | Large powerful model by Qwen | Supported ConfigurationsDefault:cuda:BNB_4:transformersmps:MLX_4:mlxcpu:Q4_K_M:llama.cpp |
Remote Models
Import path:
universal_intelligence.community.models.remote.<import>(eg. universal_intelligence.community.models.remote.default)
| I/O | Name | Import | Description | Provider |
|------|------|------|-------------|-----------|
| Text/Text | deepseek/deepseek-r1:free | default__free (default free) | DeepSeek R1 is here: Performance on par with OpenAI o1, but open-sourced and with fully open reasoning tokens. It's 671B parameters in size, with 37B active in an inference pass. Fully open-source model & technical report. MIT licensed: Distill & commercialize freely! | openrouter |
| Text/Text | openrouter/auto | default (default paid) | Your prompt will be processed by a meta-model and routed to one of dozens of models (see below), optimizing for the best possible output. To see which model was used, visit Activity, or read the model attribute of the response. Your response will be priced at the same rate as the routed model. The meta-model is powered by Not Diamond. Learn more in our docs. Requests will be routed to the following models:- openai/gpt-4o-2024-08-06- openai/gpt-4o-2024-05-13- openai/gpt-4o-mini-2024-07-18- openai/chatgpt-4o-latest- openai/o1-preview-2024-09-12- openai/o1-mini-2024-09-12- anthropic/claude-3.5-sonnet- anthropic/claude-3.5-haiku- anthropic/claude-3-opus- anthropic/claude-2.1- google/gemini-pro-1.5- google/gemini-flash-1.5- mistralai/mistral-large-2407- mistralai/mistral-nemo- deepseek/deepseek-r1- meta-llama/llama-3.1-70b-instruct- meta-llama/llama-3.1-405b-instruct- mistralai/mixtral-8x22b-instruct- cohere/command-r-plus- cohere/command-r | openrouter |
| Text/Text | 01-ai/yi-large | yi_large | The Yi Large model was designed by 01.AI with the following usecases in mind: knowledge search, data classification, human-like chat bots, and customer service. It stands out for its multilingual proficiency, particularly in Spanish, Chinese, Japanese, German, and French. Check out the launch announcement to learn more. | openrouter |
| Text/Text | aetherwiing/mn-starcannon-12b | mn_starcannon_12b | Starcannon 12B v2 is a creative roleplay and story writing model, based on Mistral Nemo, using nothingiisreal/mn-celeste-12b as a base, with intervitens/mini-magnum-12b-v1.1 merged in using the TIES method. Although more similar to Magnum overall, the model remains very creative, with a pleasant writing style. It is recommended for people wanting more variety than Magnum, and yet more verbose prose than Celeste. | openrouter |
| Text/Text | agentica-org/deepcoder-14b-preview:free | deepcoder_14b_preview__free | DeepCoder-14B-Preview is a 14B parameter code generation model fine-tuned from DeepSeek-R1-Distill-Qwen-14B using reinforcement learning with GRPO+ and iterative context lengthening. It is optimized for long-context program synthesis and achieves strong performance across coding benchmarks, including 60.6% on LiveCodeBench v5, competitive with models like o3-Mini | openrouter |
| Text/Text | ai21/jamba-1.6-large | jamba_1_6_large | AI21 Jamba Large 1.6 is a high-performance hybrid foundation model combining State Space Models (Mamba) with Transformer attention mechanisms. Developed by AI21, it excels in extremely long-context handling (256K tokens), demonstrates superior inference efficiency (up to 2.5x faster than comparable models), and supports structured JSON output and tool-use capabilities. It has 94 billion active parameters (398 billion total), optimized quantization support (ExpertsInt8), and multilingual proficiency in languages such as English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew. Usage of this model is subject to the Jamba Open Model License. | openrouter |
| Text/Text | ai21/jamba-1.6-mini | jamba_1_6_mini | AI21 Jamba Mini 1.6 is a hybrid foundation model combining State Space Models (Mamba) with Transformer attention mechanisms. With 12 billion active parameters (52 billion total), this model excels in extremely long-context tasks (up to 256K tokens) and achieves superior inference efficiency, outperforming comparable open models on tasks such as retrieval-augmented generation (RAG) and grounded question answering. Jamba Mini 1.6 supports multilingual tasks across English, Spanish, French, Portuguese, Italian, Dutch, German, Arabic, and Hebrew, along with structured JSON output and tool-use capabilities. Usage of this model is subject to the Jamba Open Model License. | openrouter |
| Text/Text | ai21/jamba-instruct | jamba_instruct | The Jamba-Instruct model, introduced by AI21 Labs, is an instruction-tuned variant of their hybrid SSM-Transformer Jamba model, specifically optimized for enterprise applications.- 256K Context Window: It can process extensive information, equivalent to a 400-page novel, which is beneficial for tasks involving large documents such as financial reports or legal documents- Safety and Accuracy: Jamba-Instruct is designed with enhanced safety features to ensure secure deployment in enterprise environments, reducing the risk and cost of implementation Read their announcement to learn more. Jamba has a knowledge cutoff of February 2024. | openrouter |
| Text/Text | aion-labs/aion-1.0 | aion_1_0 | Aion-1.0 is a multi-model system designed for high performance across various tasks, including reasoning and coding. It is built on DeepSeek-R1, augmented with additional models and techniques such as Tree of Thoughts (ToT) and Mixture of Experts (MoE). It is Aion Lab's most powerful reasoning model. | openrouter |
| Text/Text | aion-labs/aion-1.0-mini | aion_1_0_mini | Aion-1.0-Mini 32B parameter model is a distilled version of the DeepSeek-R1 model, designed for strong performance in reasoning domains such as mathematics, coding, and logic. It is a modified variant of a FuseAI model that outperforms R1-Distill-Qwen-32B and R1-Distill-Llama-70B, with benchmark results available on its Hugging Face page, independently replicated for verification. | openrouter |
| Text/Text | aion-labs/aion-rp-llama-3.1-8b | aion_rp_llama_3_1_8b | Aion-RP-Llama-3.1-8B ranks the highest in the character evaluation portion of the RPBench-Auto benchmark, a roleplaying-specific variant of Arena-Hard-Auto, where LLMs evaluate each other's responses. It is a fine-tuned base model rather than an instruct model, designed to produce more natural and varied writing. | openrouter |
| Text/Text | alfredpros/codellama-7b-instruct-solidity | codellama_7b_instruct_solidity | A finetuned 7 billion parameters Code LLaMA - Instruct model to generate Solidity smart contract using 4-bit QLoRA finetuning provided by PEFT library. | openrouter |
| Text/Text | all-hands/openhands-lm-32b-v0.1 | openhands_lm_32b_v0_1 | OpenHands LM v0.1 is a 32B open-source coding model fine-tuned from Qwen2.5-Coder-32B-Instruct using reinforcement learning techniques outlined in SWE-Gym. It is optimized for autonomous software development agents and achieves strong performance on SWE-Bench Verified, with a 37.2% resolve rate. The model supports a 128K token context window, making it well-suited for long-horizon code reasoning and large codebase tasks. OpenHands LM is designed for local deployment and runs on consumer-grade GPUs such as a single 3090. It enables fully offline agent workflows without dependency on proprietary APIs. This release is intended as a research preview, and future updates aim to improve generalizability, reduce repetition, and offer smaller variants. | openrouter |
| Text/Text | allenai/olmo-7b-instruct | olmo_7b_instruct | OLMo 7B Instruct by the Allen Institute for AI is a model finetuned for question answering. It demonstrates notable performance across multiple benchmarks including TruthfulQA and ToxiGen.Open Source: The model, its code, checkpoints, logs are released under the Apache 2.0 license.- Core repo (training, inference, fine-tuning etc.)- Evaluation code- Further fine-tuning code- Paper- Technical blog post- W&B Logs | openrouter |
| Text/Text | alpindale/goliath-120b | goliath_120b | A large LLM created by combining two fine-tuned Llama 70B models into one 120B model. Combines Xwin and Euryale. Credits to- @chargoddard for developing the framework used to merge the model - mergekit.- @Undi95 for helping with the merge ratios.#merge | openrouter |
| Text/Text | alpindale/magnum-72b | magnum_72b | From the maker of Goliath, Magnum 72B is the first in a new family of models designed to achieve the prose quality of the Claude 3 models, notably Opus & Sonnet. The model is based on Qwen2 72B and trained with 55 million tokens of highly curated roleplay (RP) data. | openrouter |
| Text/Text | amazon/nova-lite-v1 | nova_lite_v1 | Amazon Nova Lite 1.0 is a very low-cost multimodal model from Amazon that focused on fast processing of image, video, and text inputs to generate text output. Amazon Nova Lite can handle real-time customer interactions, document analysis, and visual question-answering tasks with high accuracy. With an input context of 300K tokens, it can analyze multiple images or up to 30 minutes of video in a single input. | openrouter |
| Text/Text | amazon/nova-micro-v1 | nova_micro_v1 | Amazon Nova Micro 1.0 is a text-only model that delivers the lowest latency responses in the Amazon Nova family of models at a very low cost. With a context length of 128K tokens and optimized for speed and cost, Amazon Nova Micro excels at tasks such as text summarization, translation, content classification, interactive chat, and brainstorming. It has simple mathematical reasoning and coding abilities. | openrouter |
| Text/Text | amazon/nova-pro-v1 | nova_pro_v1 | Amazon Nova Pro 1.0 is a capable multimodal model from Amazon focused on providing a combination of accuracy, speed, and cost for a wide range of tasks. As of December 2024, it achieves state-of-the-art performance on key benchmarks including visual question answering (TextVQA) and video understanding (VATEX). Amazon Nova Pro demonstrates strong capabilities in processing both visual and textual information and at analyzing financial documents.NOTE: Video input is not supported at this time. | openrouter |
| Text/Text | anthracite-org/magnum-v2-72b | magnum_v2_72b | From the maker of Goliath, Magnum 72B is the seventh in a family of models designed to achieve the prose quality of the Claude 3 models, notably Opus & Sonnet. The model is based on Qwen2 72B and trained with 55 million tokens of highly curated roleplay (RP) data. | openrouter |
| Text/Text | anthracite-org/magnum-v4-72b | magnum_v4_72b | This is a series of models designed to replicate the prose quality of the Claude 3 models, specifically Sonnet(https://openrouter.ai/anthropic/claude-3.5-sonnet) and Opus(https://openrouter.ai/anthropic/claude-3-opus). The model is fine-tuned on top of Qwen2.5 72B. | openrouter |
| Text/Text | anthropic/claude-2 | claude_2 | Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2.0 | claude_2_0 | Anthropic's flagship model. Superior performance on tasks that require complex reasoning. Supports hundreds of pages of text. | openrouter |
| Text/Text | anthropic/claude-2.0:beta | claude_2_0__beta | Anthropic's flagship model. Superior performance on tasks that require complex reasoning. Supports hundreds of pages of text. | openrouter |
| Text/Text | anthropic/claude-2.1 | claude_2_1 | Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2.1:beta | claude_2_1__beta | Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-2:beta | claude_2__beta | Claude 2 delivers advancements in key capabilities for enterprises—including an industry-leading 200K token context window, significant reductions in rates of model hallucination, system prompts and a new beta feature: tool use. | openrouter |
| Text/Text | anthropic/claude-3-haiku | claude_3_haiku | Claude 3 Haiku is Anthropic's fastest and most compact model for near-instant responsiveness. Quick and accurate targeted performance. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-haiku:beta | claude_3_haiku__beta | Claude 3 Haiku is Anthropic's fastest and most compact model for near-instant responsiveness. Quick and accurate targeted performance. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-opus | claude_3_opus | Claude 3 Opus is Anthropic's most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-opus:beta | claude_3_opus__beta | Claude 3 Opus is Anthropic's most powerful model for highly complex tasks. It boasts top-level performance, intelligence, fluency, and understanding. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-sonnet | claude_3_sonnet | Claude 3 Sonnet is an ideal balance of intelligence and speed for enterprise workloads. Maximum utility at a lower price, dependable, balanced for scaled deployments. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3-sonnet:beta | claude_3_sonnet__beta | Claude 3 Sonnet is an ideal balance of intelligence and speed for enterprise workloads. Maximum utility at a lower price, dependable, balanced for scaled deployments. See the launch announcement and benchmark results here#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-haiku | claude_3_5_haiku | Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Engineered to excel in real-time applications, it delivers quick response times that are essential for dynamic tasks such as chat interactions and immediate coding suggestions. This makes it highly suitable for environments that demand both speed and precision, such as software development, customer service bots, and data management systems. This model is currently pointing to Claude 3.5 Haiku (2024-10-22). | openrouter |
| Text/Text | anthropic/claude-3.5-haiku-20241022 | claude_3_5_haiku_20241022 | Claude 3.5 Haiku features enhancements across all skill sets including coding, tool use, and reasoning. As the fastest model in the Anthropic lineup, it offers rapid response times suitable for applications that require high interactivity and low latency, such as user-facing chatbots and on-the-fly code completions. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for a broad range of industries. It does not support image inputs. See the launch announcement and benchmark results here | openrouter |
| Text/Text | anthropic/claude-3.5-haiku-20241022:beta | claude_3_5_haiku_20241022__beta | Claude 3.5 Haiku features enhancements across all skill sets including coding, tool use, and reasoning. As the fastest model in the Anthropic lineup, it offers rapid response times suitable for applications that require high interactivity and low latency, such as user-facing chatbots and on-the-fly code completions. It also excels in specialized tasks like data extraction and real-time content moderation, making it a versatile tool for a broad range of industries. It does not support image inputs. See the launch announcement and benchmark results here | openrouter |
| Text/Text | anthropic/claude-3.5-haiku:beta | claude_3_5_haiku__beta | Claude 3.5 Haiku features offers enhanced capabilities in speed, coding accuracy, and tool use. Engineered to excel in real-time applications, it delivers quick response times that are essential for dynamic tasks such as chat interactions and immediate coding suggestions. This makes it highly suitable for environments that demand both speed and precision, such as software development, customer service bots, and data management systems. This model is currently pointing to Claude 3.5 Haiku (2024-10-22). | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet | claude_3_5_sonnet | New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Scores ~49% on SWE-Bench Verified, higher than the last best score, and without any fancy prompt scaffolding- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet-20240620 | claude_3_5_sonnet_20240620 | Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Autonomously writes, edits, and runs code with reasoning and troubleshooting- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems) For the latest version (2024-10-23), check out Claude 3.5 Sonnet.#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet-20240620:beta | claude_3_5_sonnet_20240620__beta | Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Autonomously writes, edits, and runs code with reasoning and troubleshooting- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems) For the latest version (2024-10-23), check out Claude 3.5 Sonnet.#multimodal | openrouter |
| Text/Text | anthropic/claude-3.5-sonnet:beta | claude_3_5_sonnet__beta | New Claude 3.5 Sonnet delivers better-than-Opus capabilities, faster-than-Sonnet speeds, at the same Sonnet prices. Sonnet is particularly good at:- Coding: Scores ~49% on SWE-Bench Verified, higher than the last best score, and without any fancy prompt scaffolding- Data science: Augments human data science expertise; navigates unstructured data while using multiple tools for insights- Visual processing: excelling at interpreting charts, graphs, and images, accurately transcribing text to derive insights beyond just the text alone- Agentic tasks: exceptional tool use, making it great at agentic tasks (i.e. complex, multi-step problem solving tasks that require engaging with other systems)#multimodal | openrouter |
| Text/Text | anthropic/claude-3.7-sonnet | claude_3_7_sonnet | Claude 3.7 Sonnet is an advanced large language model with improved reasoning, coding, and problem-solving capabilities. It introduces a hybrid reasoning approach, allowing users to choose between rapid responses and extended, step-by-step processing for complex tasks. The model demonstrates notable improvements in coding, particularly in front-end development and full-stack updates, and excels in agentic workflows, where it can autonomously navigate multi-step processes. Claude 3.7 Sonne