
utf-as
v0.2.0
Published
SIMD UTF-8/UTF-16 for AssemblyScript — a drop-in for String.UTF8 / String.UTF16 with simdutf-derived 128-bit Wasm SIMD kernels.
Downloads
917
Maintainers
 jairussw
jairusswReadme
What
This library ports simdutf's westmere SSE4 UTF-8 kernels to 128-bit Wasm SIMD and exposes them through the same namespace shape, so you can swap them in by changing the import. It also includes fast validators for both UTF-8 and UTF-16.
UTF8.decode→ 2-7× faster thanString.UTF8.decodeUTF8.encode→ 8-13× faster thanString.UTF8.encodeUTF8.validate→ up to 58 GB/s on ASCII-heavy HTML; 11-35 GB/s on mixed multibyte contentUTF16.validate→ ~24-25 GB/s on BMP-heavy text (surrogate-free fast path); ~13 GB/s on dense surrogate-pair content
Every operation has a portable SWAR (SIMD-within-a-register) path that runs by default and is dispatched to the SIMD kernel only above a size threshold, so small inputs avoid SIMD setup overhead and the library works with or without --enable simd (the throughput figures above are the SIMD path).
If you often pass strings between a UTF-8-based host and wasm, consider using UTF8.decode/UTF8.encode for much faster conversion and less overhead.
Installation
npm install utf-asThen import from the package root:
import { UTF8, UTF16 } from "utf-as";For full throughput, enable SIMD (it is on by default in the bundled asconfig.json):
--enable simdSIMD is no longer required — with --disable simd (or a toolchain without it) the library falls back to its scalar/SWAR paths and still works, just slower on large input.
Enabling Bulk Memory helps with memory allocation overhead and is not required, but strongly recommended.
--enable bulk-memory Usage
import { UTF8, UTF16 } from "utf-as";
const bytes = UTF8.encode("Hello, 世界 🌍"); // ArrayBuffer
const back = UTF8.decode(bytes); // string
const valid = UTF8.validate(bytes); // bool - strict UTF-8 check
// UTF-16 is memcpy under the hood (kept for API parity with String.UTF16)
const wide = UTF16.encode("Hello"); // ArrayBuffer
const wback = UTF16.decode(wide); // stringAll namespace functions match their Standard Library String.UTF8 / String.UTF16 counterparts' signatures - same ErrorMode enum (WTF8 / REPLACE / ERROR), same nullTerminated flag, byte-for-byte stdlib parity on valid input. They are 100% interchangeable.
API
UTF8
Drop-in for String.UTF8. encode / decode run a SWAR transcoder (8 code units / bytes per u64, with a scalar coder for multibyte) by default and dispatch to the SIMD kernel only when SIMD is compiled in (ASC_FEATURE_SIMD) and the input clears a size threshold (encode 32 units, decode 256 bytes) — below that the SIMD kernels do no vector work, so SWAR is faster (up to ~3× on small ASCII). The scalar fallback (a byte-for-byte stdlib clone) covers nullTerminated, REPLACE, and ERROR modes. Like validation, encode / decode compile and run with --enable simd off.
UTF8.byteLength(str: string, nullTerminated?: bool): i32
UTF8.encode(str: string, nullTerminated?: bool, errorMode?: UTF8.ErrorMode): ArrayBuffer
UTF8.decode(buf: ArrayBuffer, nullTerminated?: bool): string
// Pointer-based variants - no allocation, caller-owned buffers:
UTF8.encodeUnsafe(str: usize, len: i32, buf: usize, ...): usize
UTF8.decodeUnsafe(buf: usize, len: usize, nullTerminated?: bool): string
// Extensions (not in stdlib):
UTF8.utf16Length(buf: ArrayBuffer): i32
UTF8.utf16LengthUnsafe(buf: usize, len: i32): i32
UTF8.validate(buf: ArrayBuffer): bool
UTF8.validateUnsafe(buf: usize, len: i32): boolDecode is permissive - see the Architecture notes for what that means in practice.
UTF16
Drop-in for String.UTF16. UTF-16LE in, UTF-16LE out - all four entry points are memcpy-shaped, kept for API parity so callers can swap our package in without touching call sites.
UTF16.byteLength(str: string): i32
UTF16.encode(str: string): ArrayBuffer
UTF16.decode(buf: ArrayBuffer): string
UTF16.encodeUnsafe(str: usize, len: i32, buf: usize): usize
UTF16.decodeUnsafe(buf: usize, len: usize): string
// Extensions (not in stdlib):
UTF16.validate(buf: ArrayBuffer): bool
UTF16.validateUnsafe(buf: usize, len: i32): boolValidation
Strict validators with no stdlib equivalent, exposed on both namespaces. The *Unsafe variants take a raw pointer and a byte length (UTF16.validateUnsafe returns false on an odd byte length); the ArrayBuffer forms wrap them. Empty input is valid.
UTF8.validate(buf: ArrayBuffer): bool
UTF8.validateUnsafe(buf: usize, len: i32): bool // len in bytes
UTF16.validate(buf: ArrayBuffer): bool
UTF16.validateUnsafe(buf: usize, len: i32): bool // len in bytesUTF8(Keiser–Lemire, "Validating UTF-8 in less than one instruction per byte"): rejects lone continuation bytes, overlong sequences, UTF-8-encoded surrogates (ED A0–BF X), out-of-range codepoints (>U+10FFFF), and truncated multibyte at EOF.UTF16: rejects lone surrogates - every high surrogate (D800–DBFF) must be immediately followed by a low surrogate (DC00–DFFF), and vice versa - plus odd byte lengths.
UTF8.validate runs a SWAR (SIMD-within-a-register, 8 bytes per u64) validator by default and dispatches to the SIMD kernel only when SIMD is compiled in (ASC_FEATURE_SIMD) and the input is ≥ 64 bytes. The two paths agree byte-for-byte. Two consequences:
- Small inputs are faster. Below 64 bytes the SWAR path skips the SIMD kernel's 64-byte scratch fill and validates 8 bytes at a time — up to ~3× the throughput of the SIMD path on short ASCII (see the chart).
- SIMD is now optional for validation. With
--enable simdoff,UTF8.validatecompiles and runs through the SWAR path alone (it reaches zero v128 ops).
UTF16.validate works the same way (SWAR default, SIMD ≥ 16 bytes / one 8-unit block) and is ~2-2.5× faster than the SIMD path on sub-block input. UTF8.encode / decode likewise default to SWAR (see UTF8); UTF16.encode / decode are a plain memory.copy. The whole library now compiles and runs with --enable simd off.
Length pre-counters
Output-size pre-computation for sizing destination buffers without performing the full conversion.
utf16_length_from_utf8(src: usize, len: i32): i32 // → UTF-16 units from UTF-8 bytes
utf8_length_from_utf16(src: usize, len: i32): i32 // → UTF-8 bytes from UTF-16 units (0 on lone surrogate)Performance
Benchmarks
V8 / Apple Silicon, GB/s of UTF-8 input. Payloads are simdutf's wikipedia_mars/*.html + emoji.txt.
| Payload | UTF8.decode | × stdlib | UTF8.encode | × stdlib | UTF8.validate |
|---|---:|---:|---:|---:|---:|
| english.html | 16.4 GB/s | 6.97× | 14.2 GB/s | 13.0× | 59.6 GB/s |
| german.html | 10.8 GB/s | 4.71× | 12.0 GB/s | 11.3× | 35.3 GB/s |
| portuguese.html | 9.2 GB/s | 4.29× | 11.2 GB/s | 11.0× | 30.4 GB/s |
| french.html | 7.1 GB/s | 3.19× | 10.5 GB/s | 10.4× | 24.6 GB/s |
| turkish.html | 6.5 GB/s | 3.05× | 9.4 GB/s | 10.2× | 21.1 GB/s |
| vietnamese.html | 5.3 GB/s | 2.67× | 8.2 GB/s | 9.5× | 21.1 GB/s |
| chinese.html | 6.2 GB/s | 2.88× | 10.2 GB/s | 10.2× | 17.5 GB/s |
| japanese.html | 5.9 GB/s | 2.66× | 9.6 GB/s | 9.4× | 15.4 GB/s |
| thai.html | 6.2 GB/s | 2.58× | 8.3 GB/s | 8.4× | 15.6 GB/s |
| hindi.html | 5.8 GB/s | 2.40× | 9.0 GB/s | 9.4× | 16.2 GB/s |
| arabic.html | 4.7 GB/s | 2.55× | 7.1 GB/s | 8.4× | 14.3 GB/s |
| korean.html | 4.6 GB/s | 2.15× | 9.1 GB/s | 9.7× | 14.1 GB/s |
| russian.html | 4.4 GB/s | 2.45× | 6.6 GB/s | 8.1× | 14.0 GB/s |
| hebrew.html | 3.9 GB/s | 2.19× | 6.8 GB/s | 8.1× | 11.6 GB/s |
| emoji.txt | 1.5 GB/s | 0.62× | 1.8 GB/s | 1.7× | 6.6 GB/s |
Emoji.txt is the outlier on both sides: 100% supplementary-plane 4-byte sequences force the SIMD path's surrogate-pair branch on every block, defeating the BMP fast lanes. For non-emoji content the wins are consistent across scripts.
Charts
V8 / Apple Silicon, per simdutf payload. Regenerate with npm run charts.
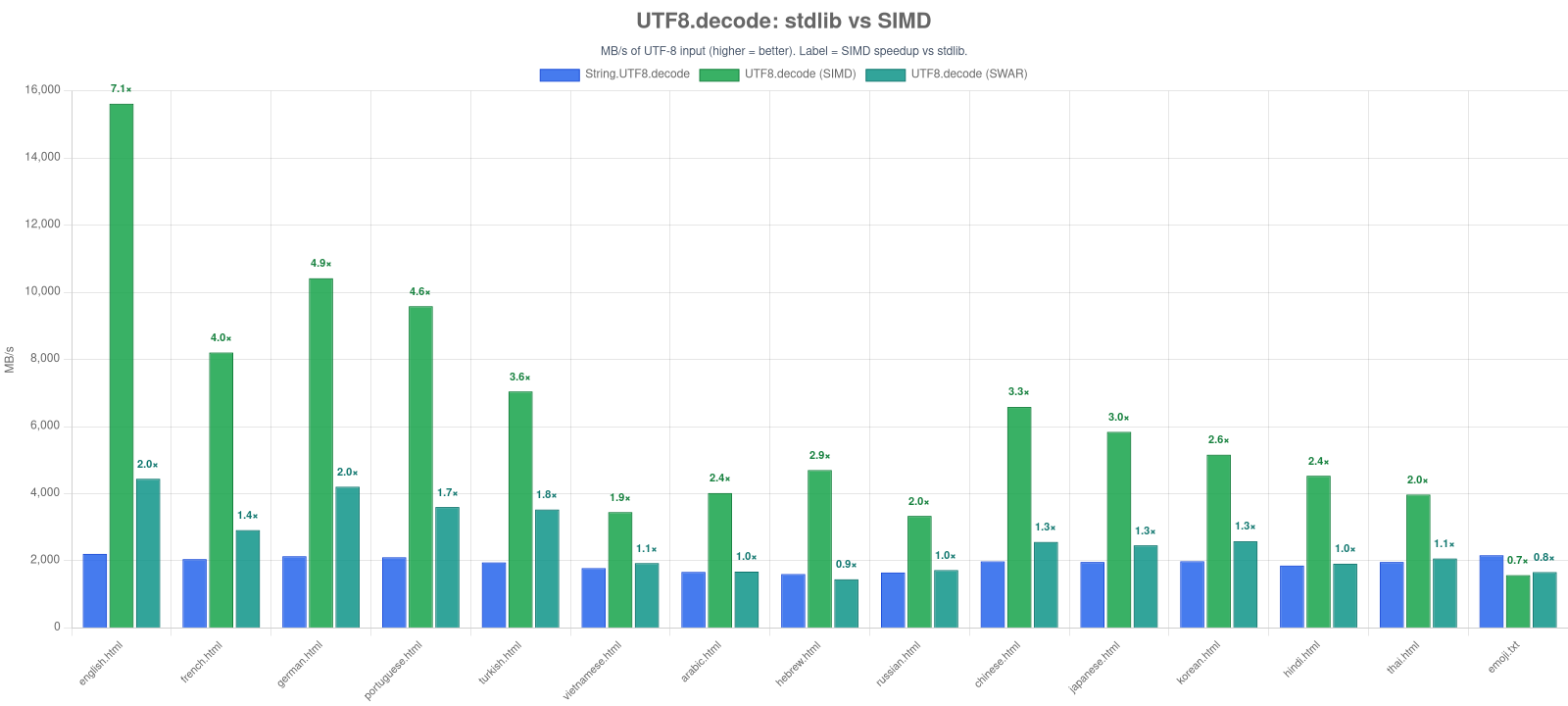
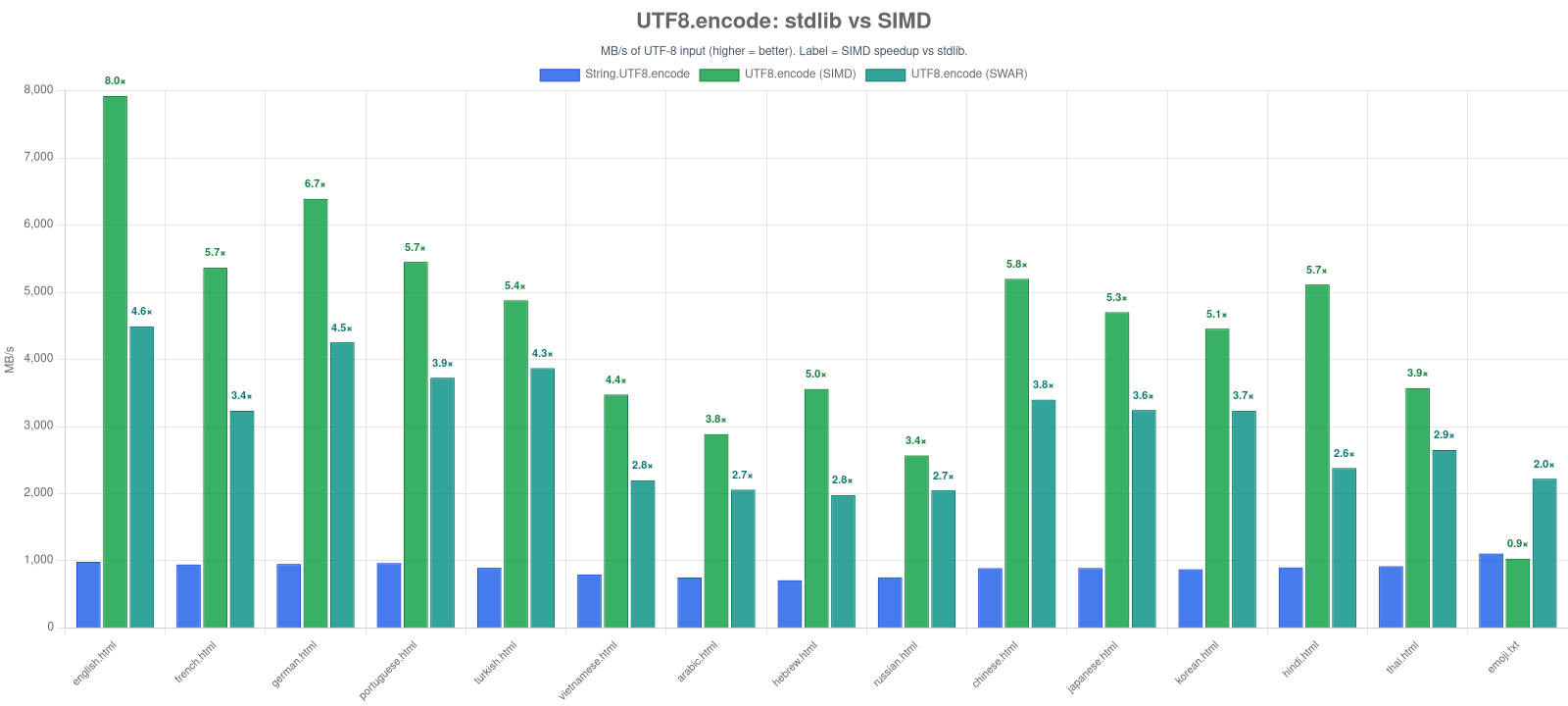
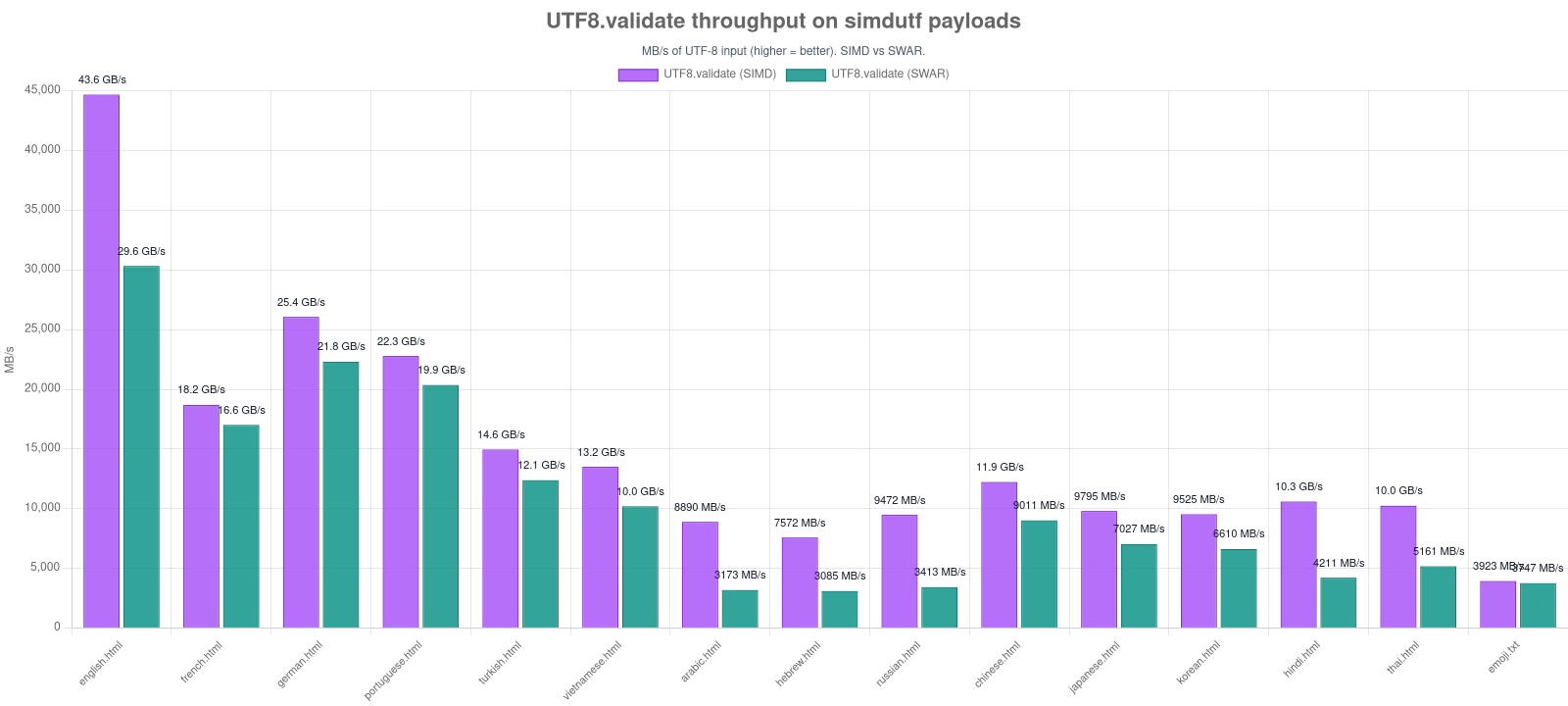
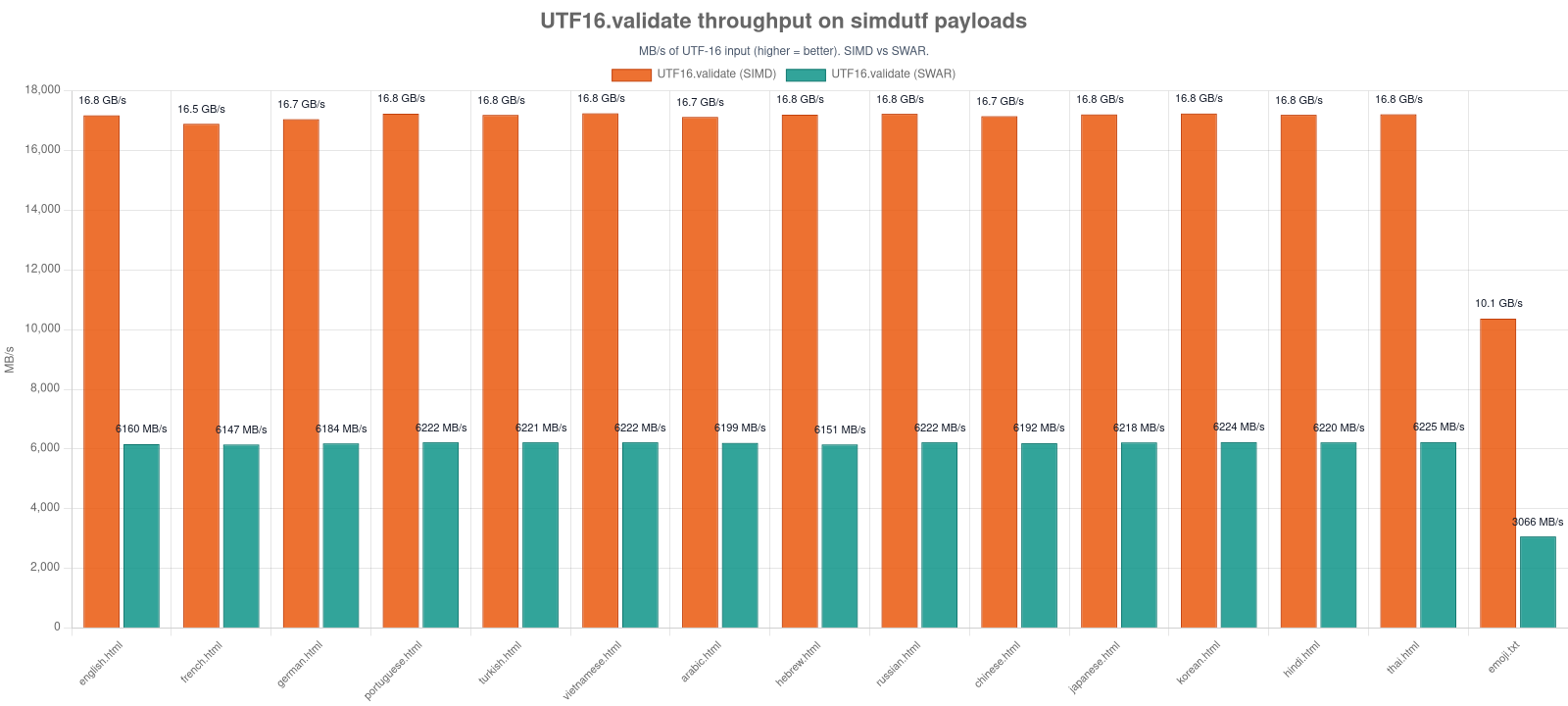
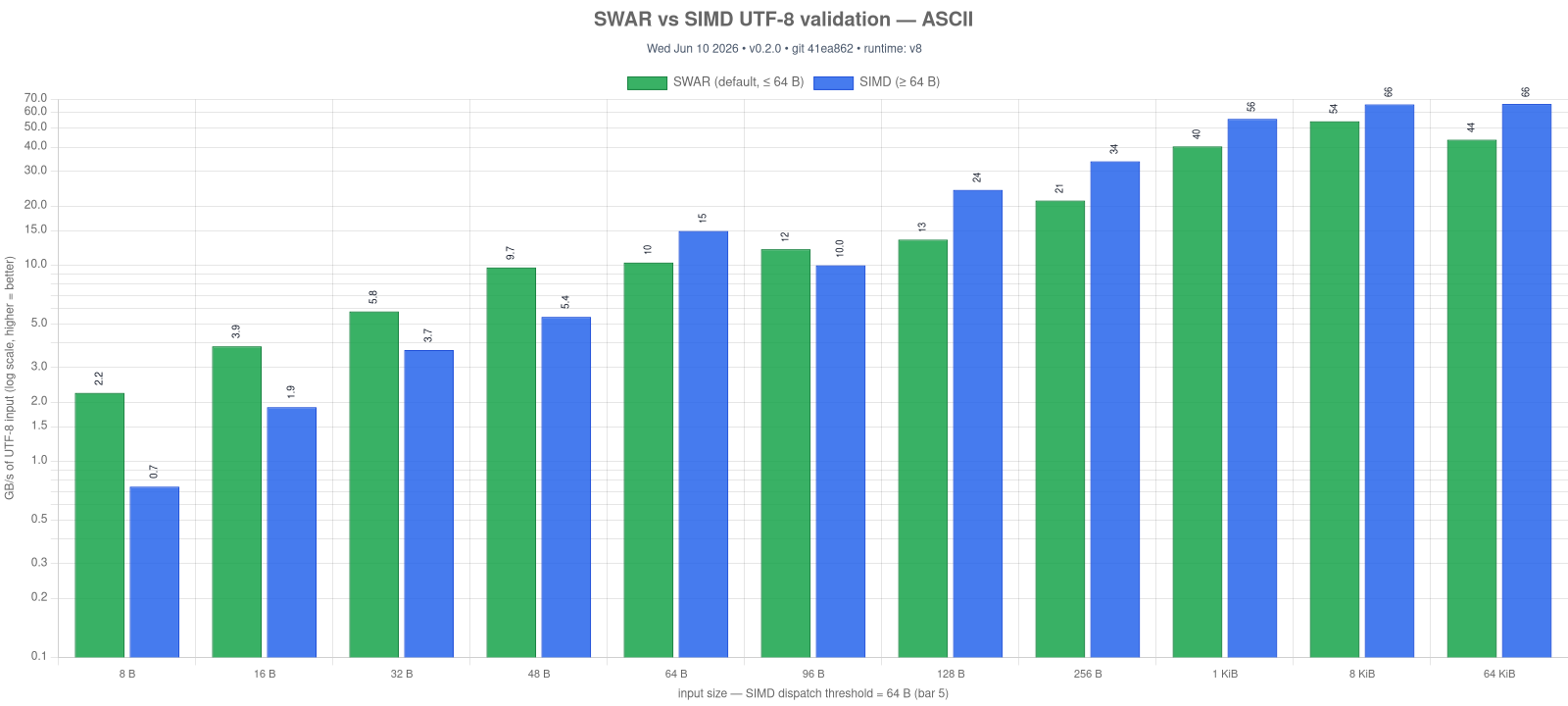
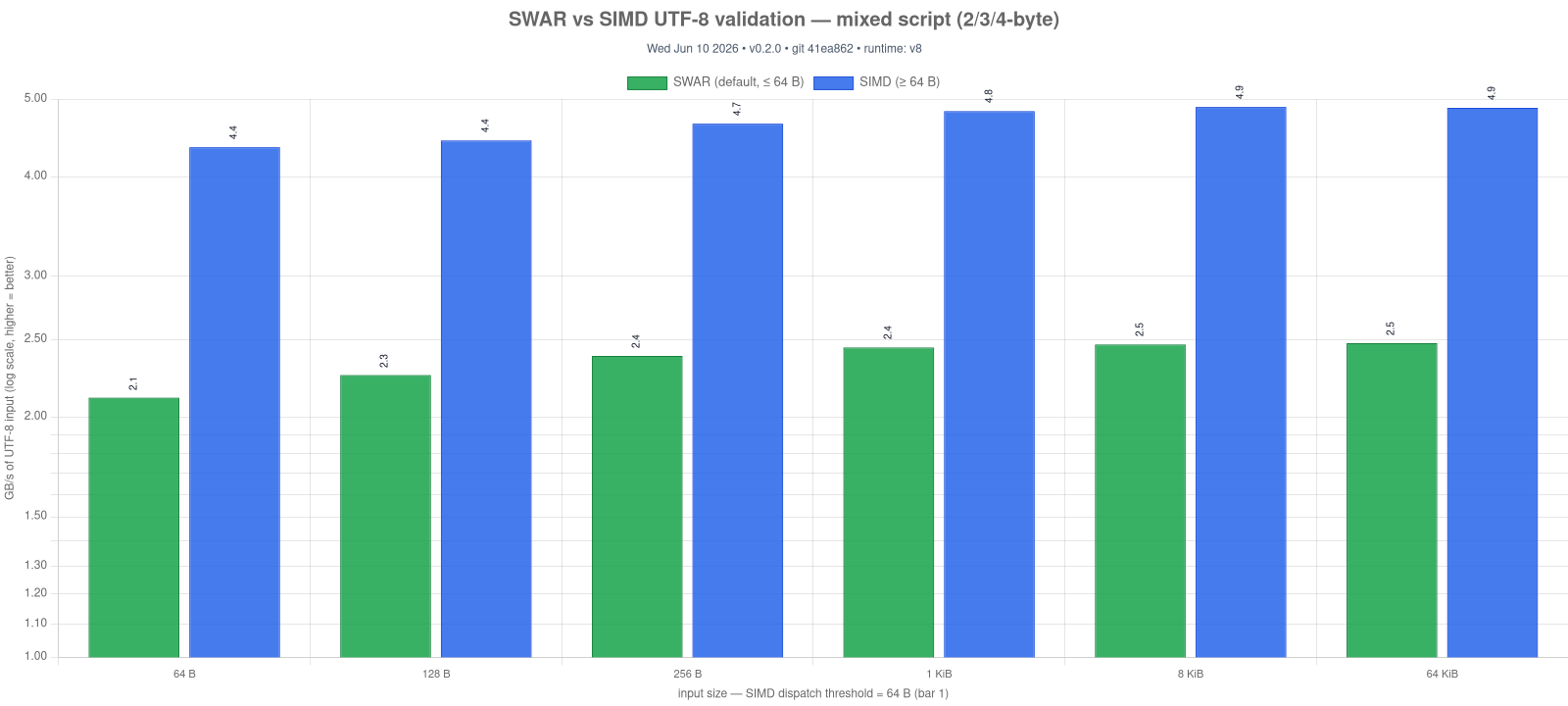
Regenerate with npm run bench -- utf-validate-swar && npm run charts:build -- utf-validate-swar-vs-simd.
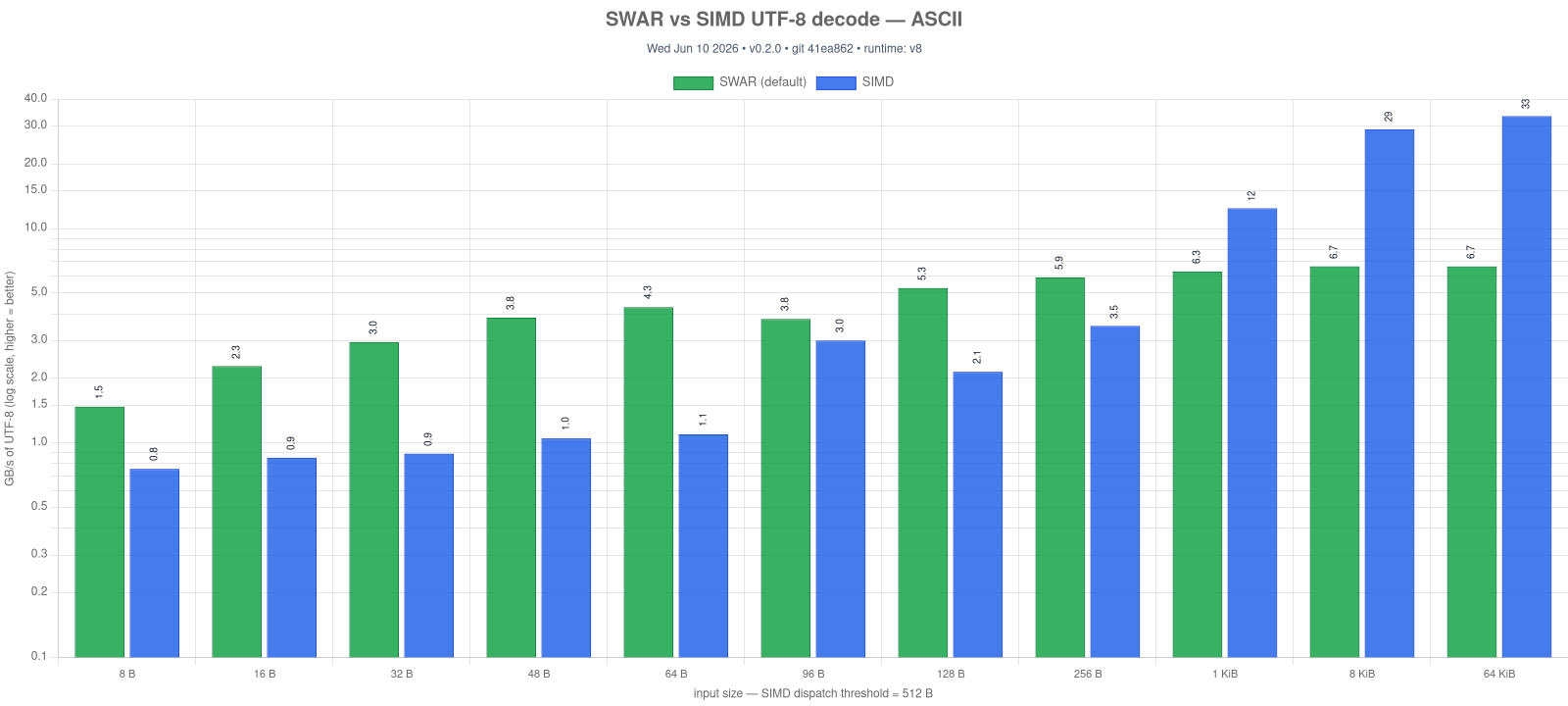
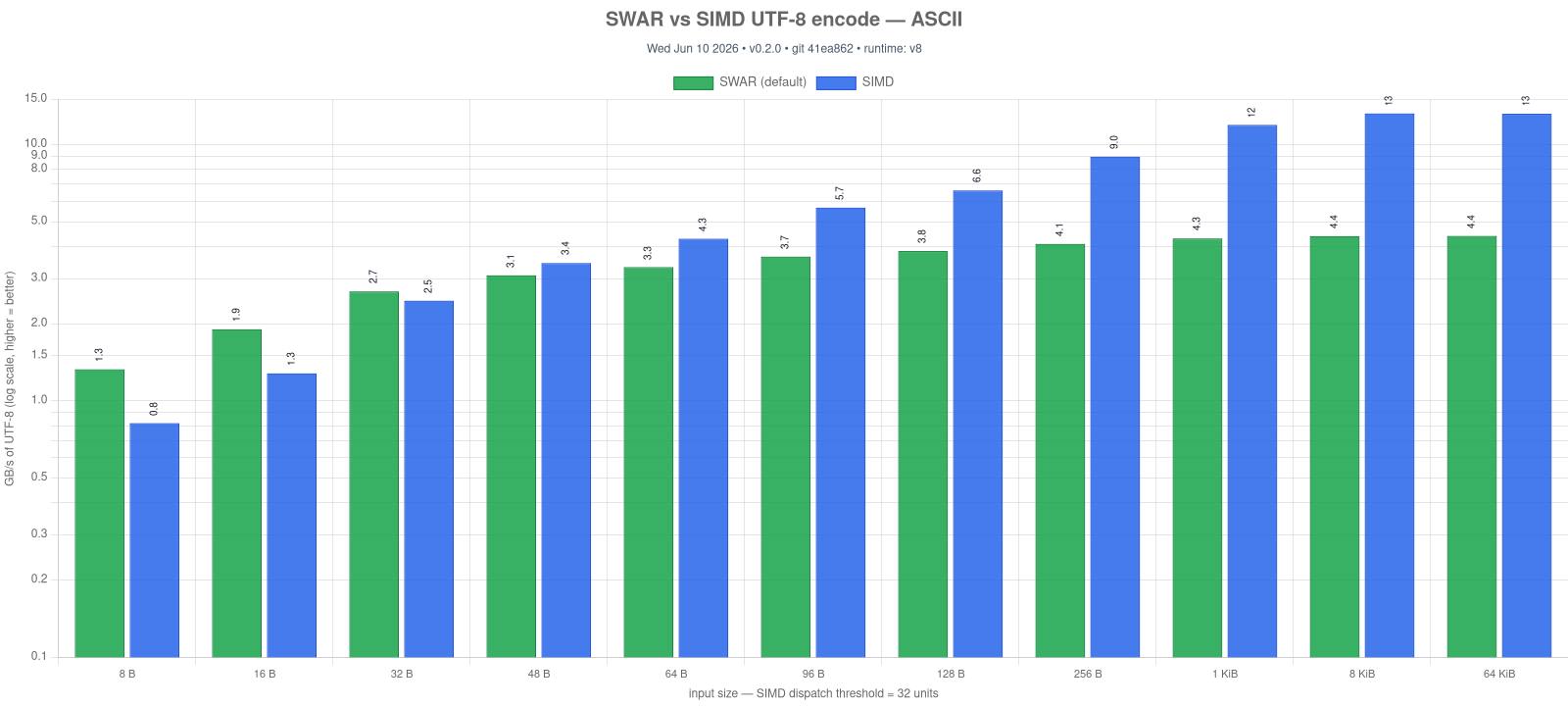
Regenerate with npm run bench -- utf-transcode-swar && npm run charts:build -- utf-transcode-swar-vs-simd.
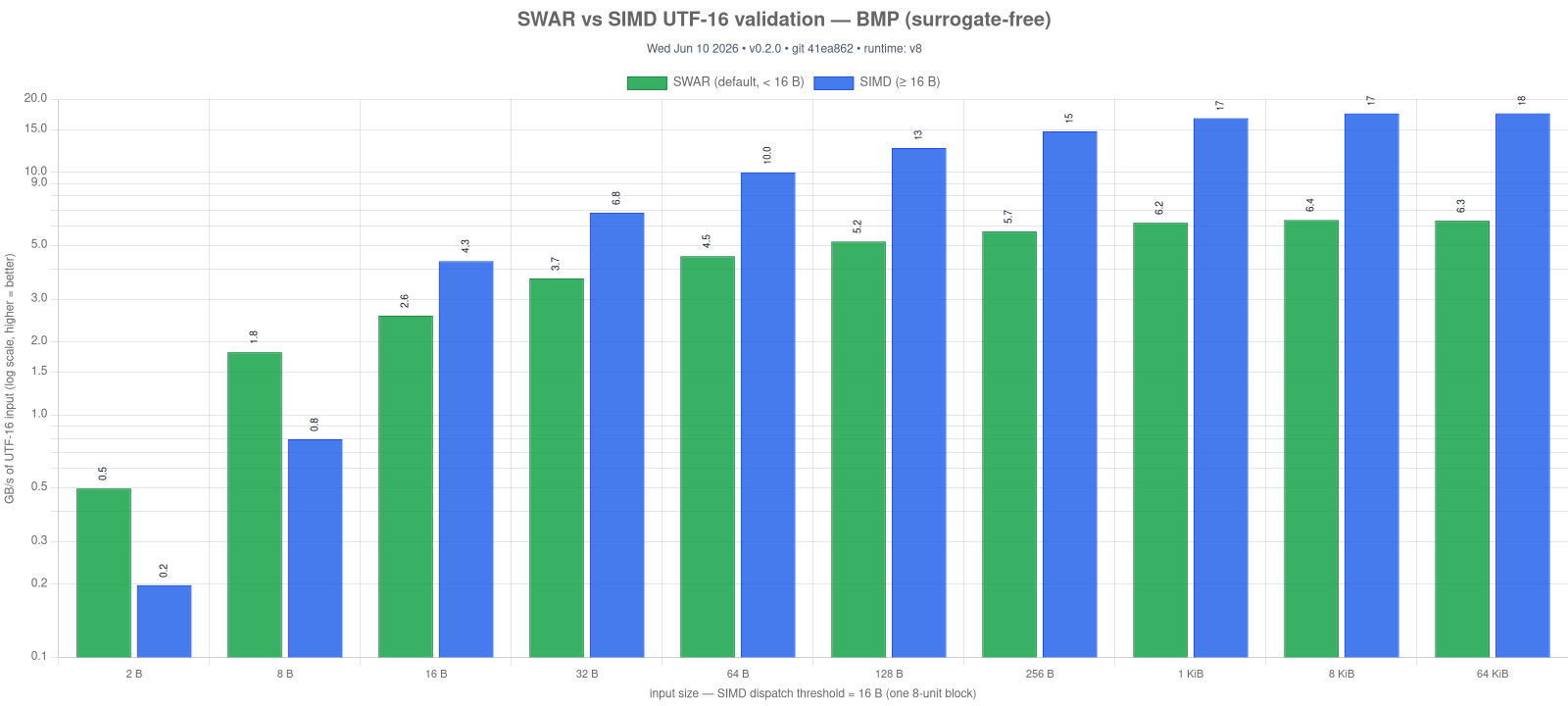
Regenerate with npm run bench -- utf16-validate-swar && npm run charts:build -- utf16-validate-swar-vs-simd.
Running benchmarks locally
npm install
npm run bench:fetch # one-time: pulls simdutf payloads into fixtures/simdutf/
npm run bench:simdutf # validator over the 18 payloads
npm run bench:vs-stdlib # head-to-head stdlib UTF8 vs ours (encode + decode)
npm run bench:summary # markdown summary of results from build/logs/as/<runtime>/
npm run charts # build + serve ./charts on :3000Multi-runtime - pass --wavm or --wazero to any bench command (binaries need to be in PATH):
npm run bench -- --wavm utf-vs-stdlib
npm run charts:build -- --wavmThe V8 runner loads payload fixtures via a readFile hostcall; WASI runtimes have none, so the harness packs the fetched fixtures and pipes them in on stdin (scripts/pack-simdutf-fixtures.mjs). Run npm run bench:fetch first for any payload bench under --wavm/--wazero.
Optional memory tracking via as-heap-analyzer:
npm run bench -- --memory utf-vs-stdlibContributing
PRs are welcome - open an issue first if it's a non-trivial change so we can sync on the approach. Run npm test and npm run bench:simdutf before submitting; the bench delta versus baseline is a useful thing to include in the PR description.
License
This project is distributed under an open source license. Work on this project is done by passion, but if you want to support it financially, you can do so by making a donation to the project's GitHub Sponsors page.
You can view the full license using the following link: License
Contact
Please send all issues to GitHub Issues and to converse, please send me an email at [email protected]
- Email: Send me inquiries, questions, or requests at [email protected]
- GitHub: Visit the official GitHub repository Here
- Website: Visit my official website at jairus.dev
- Discord: Contact me at My Discord or on the AssemblyScript Discord Server